The Jobs menu item provides a general overview of the jobs in a Hazelcast cluster that have Jet enabled.
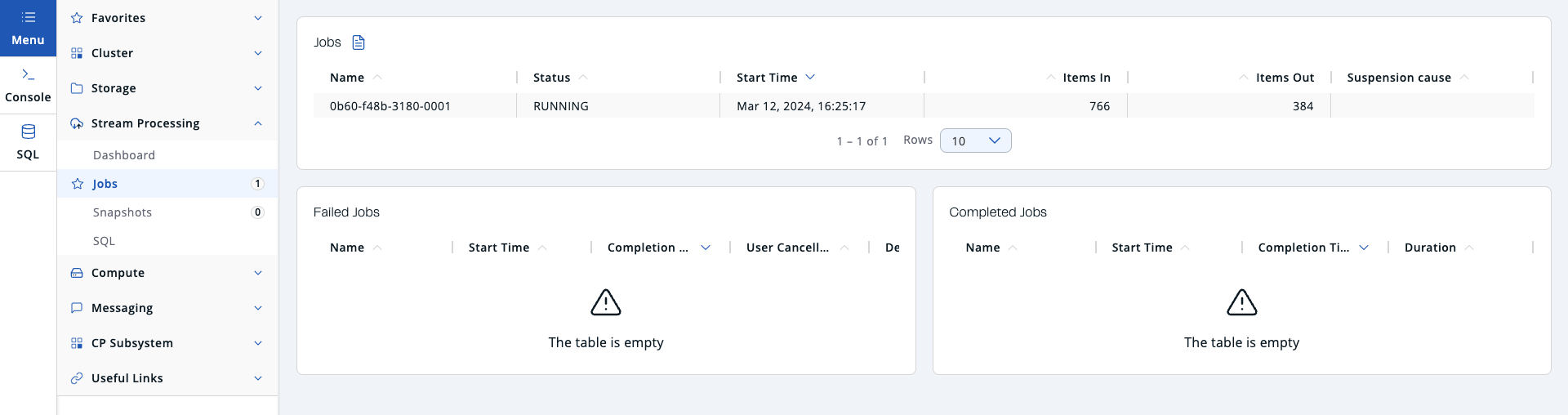
Active Jobs
This section displays the list of actively running jobs in the cluster:
-
Name: Name/ID of the job.
-
Status: Current status of the job.
-
Start Time: Start time of the job.
-
Items In: Total number of items read from the sources of the jobs.
-
Items Out: Total number of items written to the sinks of the jobs.
-
Suspension Cause: Shows the reason when the task is suspended due to a problem.
Failed Jobs
This section displays a list of failed jobs in the cluster with the following information:
-
Name: Name/ID of the job.
-
Status: Current status of the job.
-
Start Time: Start time of the job.
-
Completion Time: Completion time of the job.
-
Items In: Total number of items read from the sources of the jobs.
-
Items Out: Total number of items written to the sinks of the jobs.
Completed Jobs
This section displays a list of completed jobs in the cluster with the following information:
-
Name: Name/ID of the job.
-
Status: Current status of the job.
-
Start Time: Start time of the job.
-
Completion Time: Completion time of the job.
-
Items In: Total number of items read from the sources of the jobs.
-
Items Out: Total number of items written to the sinks of the jobs.
Job Details
When you click on a job, you’ll see a detailed view of it.
This view offers the following:
-
A tool for diagnosing data flow within the job.
-
A graphical visualization of the stages.
-
The ability to manage the lifecycle of the job and peek into dataflow stats across the DAG.

Job Management

| You must be an admin user to execute any of the following actions. |
-
Suspend: Suspends the running job, only visible when the job is in the Running state.
-
Resume: Resumes the suspended job, only visible when the job is in the Suspended state.
-
Cancel: Stops the execution of the job.
-
Restart: Stops the execution of the job and starts a new execution for it.
-
Export Snapshot: Initiates a named snapshot export; exported snapshots can be managed via snapshots view.
-
Status: Current status of the job.
-
Mode: Processing guarantee mode of the job; either
None,At Least OnceorExactly Once.
Items Flow
This section displays the dataflow metrics for the cluster:
-
Total In: Total number of items read from the source of the job.
-
Total Out: Total number of items written to the sink of the job.
-
Last Min In: Number of items read from the source of the job in the last minute.
-
Last Min Out: Number of items written to the sink of the job in the last minute.
Job Details
-
Start Time: Start time of the job.
-
Completion Time: Completion time of the job.
-
Duration: Duration of the job.
Last Successful Snapshot
-
Completion Time: Latest successful snapshot completion time.
-
Size: Size of the snapshot.
-
Duration: Duration of the snapshot creation.
| These metrics are for only non-exported snapshots. |
Job Graph
This section displays a graphical representation of the job’s processing plan as a directed acyclic graph (DAG). Each processing step is a node in the DAG.
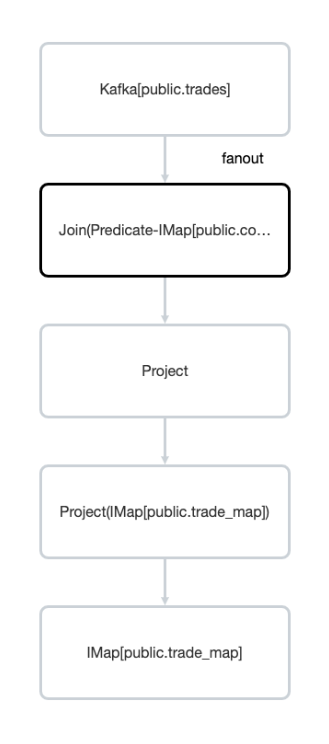
If you click a node in the graph, you’ll see the following details about that processing step:
Parallelism:
-
Local: Number of processors running for that vertex on each member.
-
Global: Total number of processors running for that vertex on the cluster.
Incoming Items:
This section displays all the incoming edges by their source vertices and shows the following information and totals for each of them.
-
All Time: Total number of items received by this vertex.
-
Last Min: Number of items received by this vertex in the last minute.
Outgoing Items:
This section displays all the outgoing edges by their target vertices and shows the following information and totals for each of them.
-
All Time: Total number of items sent by this vertex.
-
Last Min: Number of items sent by this vertex in the last minute.
Watermark Statistics:
-
Latency: This is the time difference between wall-clock time and the last forwarded watermark (“event time, time of the stream”). Multiple factors contribute to the total latency, such as the latency in the external system, allowed lag (which is always included), clock drift and also long event-to-event intervals in any partition (this one is the trickiest). See here for more information.
-
Skew: This is the difference between latencies of the processor with the highest and lowest latencies. Most common cause is a long event-to-event interval in some source partition or an idle partition (until the idle timeout elapses). Overload of events in one partition can also cause it.
Processors:
This section displays all the processors this vertex has in the cluster and shows the following information for each of them.
-
Queue Size: Current size of the processor inbox queue.
-
Queue Cap: Capacity of the processor inbox queue.
-
Queue Cap Usage: Queue utilization percentage.
-
Items In: Total number of items received by this processor.
-
Items Out: Total number of items sent by this processor.
-
Latency: Time difference between the wall-clock time and the last forwarded watermark (“event time, time of the stream”). Multiple factors contribute to the total latency:
-
latency in the external system; events arrive already delayed to Stream source
-
allowed lag; if you allow for some time to wait for delayed events, watermarks will always be delayed by this lag. Note that the actual output might not be delayed.
-
event-to-event interval; if there is a time period between two events, the event time “stops” for that time. In other words, until a new event occurs, the current time is the time of the last event. As “current event time” is tracked independently for each partition, this can be the major source of skew. If your events are irregular, you might consider adding heartbeat events. This factor also applies if you use
withIngestionTimestampssince a new wall-clock time is assigned only if a new event occurs. -
time to execute map/filter stages; these contribute to the latency of the async call or to the time to execute CPU-heavy sync call.
-
internal processing latency of Hazelcast; typically very low: 1 or 2 milliseconds. It can be higher if the network is slow, the system is overloaded, if there are many vertices in the job, or many jobs which cause lots of switching, etc.
-
clock drift; since we’re comparing to the real time, latency can be caused by a clock drift between this and the machine where event time is assigned (which can also be an end user’s device). It can even be negative. Always use NTP to keep wall-clock precise, and avoid using timestamps from devices out of your control as event time.
-