What’s New in Hazelcast Platform
| The What’s New page for Hazelcast Platform 6.0-SNAPSHOT will be available when this version is released. For the last major release, see below. |
Here are the highlights of what’s new and improved in Hazelcast Platform 5.5.
Get instant answers with new Hazelcast Ask AI
On every docs page you can now click the Ask AI button in the bottom right and get instant answers to all your questions about Hazelcast Platform, and our tools and clients. Ask AI is powered by the entire suite of Hazelcast documentation, including the latest docs from docs.hazelcast.com, the various API docs microsites, the latest official blogs, and a bunch of code samples and support knowledgebase articles.
Give it a try now - for more information, see Ask AI.
New Vector Collection for building semantic search (BETA)
Enterprise
With the introduction of a new data structure specifically designed for vector search, Hazelcast Platform 5.5 adds functionality to help you build and deliver vector search capabilities, and improve the quality and accuracy of search results. Indexes are based on the JVector library, which implements a DiskANN algorithm for similarity search and provides exceptional performance.
A Hazelcast vector database engine is a specialized type of database, which is optimized for storing, searching, and managing vector embeddings and additional metadata. You can include values in the metadata to provide filtering, additional processing, or analysis of vectors. The primary object for interacting with vector storage is a Vector Collection. A Vector Collection holds information about the vectors and associated metadata (user values). Use with Jet Job placement control (see below) to dedicate resources for vector embedding and optimizing search performance.
For more info on vector collections, see Data Structure Design.
Distribute your workload with Jet Job placement control
Compute Isolation drives greater efficiency and performance by moving the compute closer to the data to improve performance and reduce network overheads. With 5.5 your Jet processing jobs can now be distributed across a defined subset of the cluster, which means you can distribute your workload to meet your business and regulatory requirements. You can configure Jet processing jobs so that they run on lite members only, allowing you to split your computational and storage requirements without the need to configure each job separately. You control the members to use for your Jet job processing on a job-by-job basis.
For more info, including how to use the 'JobBuilder' API, see Jet Job Placement Control.
Multi-member routing for Java clients
Geographically dispersed or 'stretched' clusters are not as resilient as standard HA clusters, and also suffer from lower throughput, longer recovery and longer operations. With the release of Hazelcast Platform 5.5, you can use multi-member routing to provide greater performance and stability for Java client applications connecting to geographically dispersed clusters. This means much faster transaction re-routing in the event of an outage. You can implement strong consistency on a stretch cluster and reduce connection overheads and improve overall performance. You can easily enable client multi-member routing using your existing client network configuration and get these benefits, all with zero downtime.
Before 5.5, Hazelcast clients could only have one of two types of connection to a cluster: single member (also known as unisocket) or all member (also known as smart). With a unisocket connection the client only connected to a single cluster member, which meant all communication was relayed via the connected cluster member and could therefore suffer from performance issues. With an all member connection the client connects to every member in the cluster and is partition-aware, which means that communications are sent directly to the cluster member holding the required data. If you’re using partition groups to isolate data to specific cluster members, there was previously no way for the client to have visibility into this configuration and therefore was not connecting as efficiently as possible, or adapting to failovers. For example, the CP Subsystem uses a group leader - clients would not be aware of this and there would an extra internal relay stage rather than sending directly to the group leader alone.
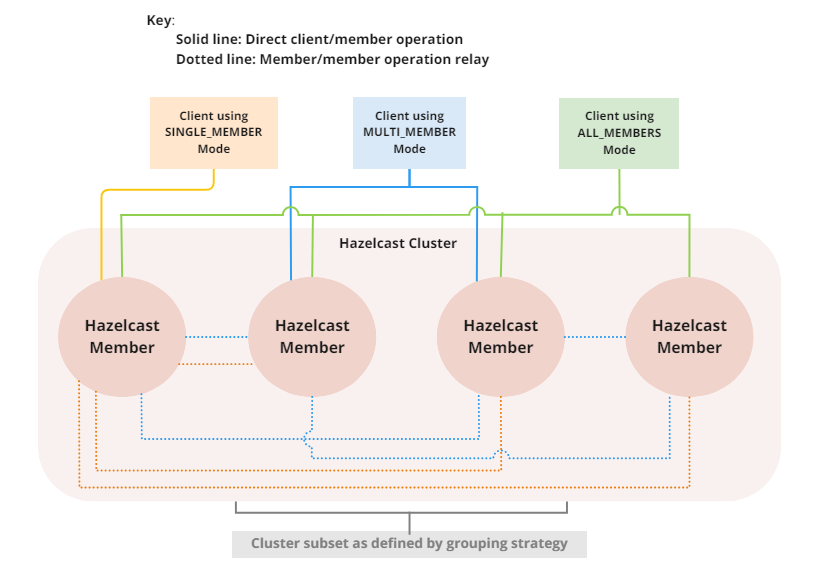
For more info, see Client cluster routing modes.
Introduction of Long-term Support (LTS) releases
Hazelcast Platform 5.5 introduces Long-term Support (LTS) releases to simplify your upgrade experience and give you greater control over when and how you upgrade your software. You can perform upgrades with more precision and consistency, and with reduced effort and risk. You can upgrade directly from a supported previous release to the LTS release or directly between LTS releases using a rolling upgrade. Between LTS releases, Hazelcast will provide short-term support (STS) releases, which will focus on innovation, and provide the latest features and bug fixes.
You can upgrade from Hazelcast Community Edition 5.5 to Hazelcast Enterprise Edition 5.5 with zero downtime, or from Hazelcast 5.2.x or later to 5.5 without the need to upgrade to each release between your current version and the LTS release. We recommend that you upgrade to 5.5 from the latest available patch for your current release.
For more info, see Long-term Support Releases.
Feast feature store integration
Release 5.5 includes integration of Feast (Feature Store), an open-source feature store that can be used on your existing infrastructure to manage and serve ML features to real-time models. A feature store is a central repository where features can be stored and processed for reuse or sharing. When integrated with Hazelcast, you can benefit from an online store that supports materializing feature values in a running Hazelcast cluster.
Feast can help to decouple ML from your data infrastructure. This can be useful in a number of ways; for example, to allow you to move between model types, such as training models to serving models, or from one data infrastructure system to another. With Feast you use the following in your ML models:
-
Historical data to support predictions that allow scaling to improve model performance
-
Real-time data to support data-driven insights
-
Pre-computed features that can be served online
For more info, see Integrate with Feast.
Dynamic configuration using REST API
Enterprise
Hazelcast now provides a REST API that allows you to access your data structures and cluster using HTTP/HTTPS protocols. You can interact with the API using various tools and platforms such as cURL, REST clients (like Postman and Insomnia), or programming languages with HTTP request libraries or built-in support. The new REST API comes with an integrated Swagger UI for learning about the API and trying out API calls.
For more info, including tutorials for Java and Docker, see REST API.
Release Notes
For detailed release notes that include new features and enhancements, breaking changes, deprecations and other fixes, see 5.5 Release Notes.
To evaluate Hazelcast Enterprise Edition features, you can request a trial license key. To install Hazelcast Enterprise Edition, see Installing Hazelcast Community Edition.
Hazelcast Command Line Client (CLC)
Support added for CPMap data structures, including cpmap commands and advanced script functions.
For detailed release notes that include new features and fixes, see Hazelcast CLC 5.4.0.
To get started with Hazelcast CLC, see Installing the Hazelcast CLC.
