Hazelcast JCache Extension - ICache
Hazelcast provides extension methods to the Cache API through
the interface com.hazelcast.cache.ICache.
It has two sets of extensions:
-
Asynchronous version of all cache operations. See Async Operations.
-
Cache operations with custom
ExpiryPolicyparameter to apply on that specific operation. See Custom ExpiryPolicy.
| ICache data structure can also be used in data pipelines for Real-Time Stream Processing (by enabling the Event Journal on your cache) and Fast Batch Processing. |
Scoping to Join Clusters
A CacheManager, started either as a client or as an embedded member,
can be configured to start a new Hazelcast instance or reuse an already
existing one to connect to a Hazelcast cluster. To achieve this, request
a CacheManager by passing a java.net.URI instance to CachingProvider.getCacheManager().
The java.net.URI instance must point to a Hazelcast configuration, e.g., hazelcast.xml.
In addition to the above,
the same can be achieved by passing Hazelcast-specific properties to
CachingProvider.getCacheManager(URI, ClassLoader, Properties) as detailed in the
sections that follow.
Examples
The following examples illustrate how HazelcastInstances are created
or reused during the creation of a new CacheManager. Complete reference
on the HazelcastInstance lookup mechanism is provided in the sections that follow.
Starting the Default CacheManager
Assuming no other HazelcastInstance exists in the same JVM, the
cacheManager below starts a new HazelcastInstance, configured
according to the configuration lookup rules as defined for Hazelcast.newHazelcastInstance()
in case of an embedded member or HazelcastClient.newHazelcastClient()
for a client-side CacheManager.
CachingProvider caching = Caching.getCachingProvider();
CacheManager cacheManager = caching.getCacheManager();Reusing Existing HazelcastInstance with the Default CacheManager
When using both Hazelcast-specific features and JCache, a HazelcastInstance
might be already available to your JCache configuration.
By configuring an instance name in hazelcast.xml in the classpath root,
the CacheManager locates the existing instance by name and reuses it.
hazelcast.xml/yaml:
<hazelcast>
...
<instance-name>hz-member-1</instance-name>
...
</hazelcast>hazelcast:
instance-name: hz-member-1HazelcastInstance & CacheManager startup:
// start hazelcast, configured with default hazelcast.xml
HazelcastInstance hz = Hazelcast.newHazelcastInstance();
// start the default CacheManager -- it locates the default hazelcast.xml configuration
// and identify the existing HazelcastInstance by its name
CachingProvider caching = Caching.getCachingProvider();
CacheManager cacheManager = caching.getCacheManager();Starting a CacheManager with a New HazelcastInstance Configured with a Non-default Configuration File
Given a configuration file named hazelcast-jcache.xml in the package
com.domain, a CacheManager can be configured to start a new HazelcastInstance:
-
By passing the URI to the configuration file as the CacheManager’s
URI:CachingProvider caching = Caching.getCachingProvider(); CacheManager cacheManager = caching.getCacheManager(new URI("classpath:com/domain/hazelcast-jcache.xml"), null); -
By specifying the configuration file location as a property:
Properties properties = HazelcastCachingProvider.propertiesByLocation("classpath:com/domain/aaa-hazelcast.xml"); CachingProvider caching = Caching.getCachingProvider(); CacheManager cacheManager = caching.getCacheManager(new URI("any-uri-will-do"), null, properties);
Note that if the Hazelcast configuration file does specify an
instance name, then any CacheManager referencing the
same configuration file locates by name and reuses the same
HazelcastInstance.
Reusing an Existing Named HazelcastInstance
Assuming a HazelcastInstance named hc-instance is already
started, it can be used as the HazelcastInstance to back a
CacheManager by specifying the instance name as a property:
Properties properties = HazelcastCachingProvider.propertiesByInstanceName("hc-instance");
CachingProvider caching = Caching.getCachingProvider();
CacheManager cacheManager = caching.getCacheManager(null, null, properties);Applying Configuration Scope
To connect or join different clusters, apply a configuration
scope to the CacheManager. If the same URI is
used to request a CacheManager that was created previously,
those CacheManagers share the same underlying HazelcastInstance.
To apply configuration scope you can do either one of the following:
-
pass the path to the configuration file using the location property
HazelcastCachingProvider#HAZELCAST_CONFIG_LOCATION(which resolves tohazelcast.config.location) as a mapping inside ajava.util.Propertiesinstance to theCachingProvider.getCacheManager(uri, classLoader, properties)call. -
use directly the configuration path as the
CacheManager'sURI.
If both HazelcastCachingProvider#HAZELCAST_CONFIG_LOCATION property is set
and the CacheManager URI resolves to a valid config file location, then
the property value is used to obtain the configuration for the HazelcastInstance
the first time a CacheManager is created for the given URI.
Here is an example of using configuration scope:
CachingProvider cachingProvider = Caching.getCachingProvider();
// Create Properties instance pointing to a Hazelcast config file
Properties properties = new Properties();
// "scope-hazelcast.xml" resides in package com.domain.config
properties.setProperty( HazelcastCachingProvider.HAZELCAST_CONFIG_LOCATION,
"classpath:com/domain/config/scoped-hazelcast.xml" );
URI cacheManagerName = new URI( "my-cache-manager" );
CacheManager cacheManager = cachingProvider
.getCacheManager( cacheManagerName, null, properties );Here is an example using HazelcastCachingProvider.propertiesByLocation() helper method:
CachingProvider cachingProvider = Caching.getCachingProvider();
// Create Properties instance pointing to a Hazelcast config file in root package
String configFile = "classpath:scoped-hazelcast.xml";
Properties properties = HazelcastCachingProvider
.propertiesByLocation( configFile );
URI cacheManagerName = new URI( "my-cache-manager" );
CacheManager cacheManager = cachingProvider
.getCacheManager( cacheManagerName, null, properties );The retrieved CacheManager is scoped to use the HazelcastInstance
that was just created and configured using the given XML
configuration file.
Available protocols for config file URL include classpath to point to
a classpath location, file to point to a filesystem
location and http and https for remote web locations. In addition,
everything that does not specify a protocol is recognized
as a placeholder that can be configured using a system property.
String configFile = "my-placeholder";
Properties properties = HazelcastCachingProvider
.propertiesByLocation( configFile );You can set this on the command line:
-Dmy-placeholder=classpath:my-configs/scoped-hazelcast.xmlYou should consider the following rules about the Hazelcast instance name
when you specify the configuration file location using
HazelcastCachingProvider#HAZELCAST_CONFIG_LOCATION (which resolves to
hazelcast.config.location):
-
If you also specified the
HazelcastCachingProvider#HAZELCAST_INSTANCE_NAME(which resolves tohazelcast.instance.name) property, this property is used as the instance name even though you configured the instance name in the configuration file. -
If you do not specify
HazelcastCachingProvider#HAZELCAST_INSTANCE_NAMEbut you configure the instance name in the configuration file using the element<instance-name>, then this element’s value is used as the instance name. -
If you do not specify an instance name via property or in the configuration file, the URL of the configuration file location is used as the instance name.
No check is performed to prevent creating multiple CacheManagers
with the same cluster
configuration on different configuration files. If the same cluster is
referred from different configuration files, multiple
cluster members or clients are created.
|
The configuration file location will not be a part of
the resulting identity of the
CacheManager. An attempt to create a CacheManager with a
different set of properties but an already used name results in
an undefined behavior.
|
Binding to a Named Instance
You can bind CacheManager to an existing and named HazelcastInstance
instance. If the instanceName is specified in com.hazelcast.config.Config,
it can be used directly by passing it to CachingProvider implementation.
Otherwise (instanceName not set or instance is a client instance) you must
get the instance name from the HazelcastInstance instance via the String getName()
method to pass the CachingProvider implementation.
Please note that instanceName is not configurable for the client-side HazelcastInstance
instance and is auto-generated by the using cluster name (if it is specified).
In general, the String getName() method over HazelcastInstance is safer and the preferable way to get the name of the instance. Multiple CacheManagers created using an equal java.net.URI share the same HazelcastInstance.
Note that the client- and member-side CacheManager's look for client- and member-side
Hazelcast instances by those instance names, respectively.
A named scope is applied nearly the same way as the configuration scope.
You can pass the instance name using the property HazelcastCachingProvider#HAZELCAST_INSTANCE_NAME
(which resolves to hazelcast.instance.name) as a mapping inside a java.util.Properties instance to the CachingProvider.getCacheManager(uri, classLoader, properties) call. When a valid instance name is provided, the property value is used to resolve the HazelcastInstance the first time a CacheManager is created.
Here is an example of Named Instance Scope with specified name:
Config config = new Config();
config.setInstanceName( "my-named-hazelcast-instance" );
// Create a named HazelcastInstance
Hazelcast.newHazelcastInstance( config );
CachingProvider cachingProvider = Caching.getCachingProvider();
// Create Properties instance pointing to a named HazelcastInstance
Properties properties = new Properties();
properties.setProperty( HazelcastCachingProvider.HAZELCAST_INSTANCE_NAME,
"my-named-hazelcast-instance" );
URI cacheManagerName = new URI( "my-cache-manager" );
CacheManager cacheManager = cachingProvider
.getCacheManager( cacheManagerName, null, properties );Here is an example of Named Instance Scope with auto-generated name:
Config config = new Config();
// Create a auto-generated named HazelcastInstance
HazelcastInstance instance = Hazelcast.newHazelcastInstance( config );
String instanceName = instance.getName();
CachingProvider cachingProvider = Caching.getCachingProvider();
// Create Properties instance pointing to a named HazelcastInstance
Properties properties = new Properties();
properties.setProperty( HazelcastCachingProvider.HAZELCAST_INSTANCE_NAME,
instanceName );
URI cacheManagerName = new URI( "my-cache-manager" );
CacheManager cacheManager = cachingProvider
.getCacheManager( cacheManagerName, null, properties );Here is an example of Named Instance Scope with auto-generated name on client instance:
ClientConfig clientConfig = new ClientConfig();
ClientNetworkConfig networkConfig = clientConfig.getNetworkConfig();
networkConfig.addAddress("127.0.0.1", "127.0.0.2");
// Create a client side HazelcastInstance
HazelcastInstance instance = HazelcastClient.newHazelcastClient( clientConfig );
String instanceName = instance.getName();
CachingProvider cachingProvider = Caching.getCachingProvider();
// Create Properties instance pointing to a named HazelcastInstance
Properties properties = new Properties();
properties.setProperty( HazelcastCachingProvider.HAZELCAST_INSTANCE_NAME,
instanceName );
URI cacheManagerName = new URI( "my-cache-manager" );
CacheManager cacheManager = cachingProvider
.getCacheManager( cacheManagerName, null, properties );Here is an example using HazelcastCachingProvider.propertiesByInstanceName() method:
Config config = new Config();
config.setInstanceName( "my-named-hazelcast-instance" );
// Create a named HazelcastInstance
Hazelcast.newHazelcastInstance( config );
CachingProvider cachingProvider = Caching.getCachingProvider();
// Create Properties instance pointing to a named HazelcastInstance
Properties properties = HazelcastCachingProvider
.propertiesByInstanceName( "my-named-hazelcast-instance" );
URI cacheManagerName = new URI( "my-cache-manager" );
CacheManager cacheManager = cachingProvider
.getCacheManager( cacheManagerName, null, properties );
The instanceName will not be a part of the resulting identity of
the CacheManager.
An attempt to create a CacheManager with a different set of properties
but an already used name will result in undefined behavior.
|
Binding to an Existing Hazelcast Instance Object
When an existing HazelcastInstance object is available, you can pass it to CacheManager.
The following example shows it for a member-side instance:
// Create a member HazelcastInstance
HazelcastInstance instance = Hazelcast.newHazelcastInstance();
CachingProvider cachingProvider = Caching.getCachingProvider(HazelcastCachingProvider.MEMBER_CACHING_PROVIDER);
cachingProvider.getCacheManager(null, null, HazelcastCachingProvider.propertiesByInstanceName("instance"));The following example shows it for a client-side instance:
HazelcastInstance client-instance = HazelcastClient.newHazelcastClient();
// the line below by default returns the client-side CachingProvider
CachingProvider cachingProvider = Caching.getCachingProvider();
// obtain a CacheManager backed by the named client instance
CacheManager cacheManager = cachingProvider.getCacheManager(null, null, HazelcastCachingProvider.propertiesByInstanceName("client-instance"));
When binding to an existing Hazelcast instance, the member- and client-side CachingProviders
must be backed by member- and client-side instances, respectively. Also note that, the getCachingProvider
returns the client-side provider by default, if the provider is not explicitly passed as an argument (as shown
in the above client-side code sample).
|
Namespacing
The java.net.URIs that don’t use the above-mentioned
Hazelcast-specific schemes are recognized as namespacing. Those
CacheManagers share the same underlying default HazelcastInstance
created (or set) by the CachingProvider, but they cache with the
same names and different namespaces on the CacheManager level, and
therefore they won’t share the same data. This is useful where multiple
applications might share the same Hazelcast JCache implementation, e.g.,
on application or OSGi servers, but are developed by
independent teams. To prevent interfering on caches using the same name,
every application can use its own namespace when
retrieving the CacheManager.
Here is an example of using namespacing.
CachingProvider cachingProvider = Caching.getCachingProvider();
URI nsApp1 = new URI( "application-1" );
CacheManager cacheManagerApp1 = cachingProvider.getCacheManager( nsApp1, null );
URI nsApp2 = new URI( "application-2" );
CacheManager cacheManagerApp2 = cachingProvider.getCacheManager( nsApp2, null );That way both applications share the same HazelcastInstance instance but not the same caches.
Retrieving an ICache Instance
Besides Scoping to Join Clusters and
Namespacing, which are implemented using the URI feature of the
specification, all other extended operations are required to retrieve the
com.hazelcast.cache.ICache interface instance from
the JCache javax.cache.Cache instance. For Hazelcast, both interfaces are
implemented on the same object instance. It
is recommended that you stay with the specification method to retrieve the
ICache version, since ICache might be subject to change without notification.
To retrieve or unwrap the ICache instance, you can execute the following code example:
CachingProvider cachingProvider = Caching.getCachingProvider();
CacheManager cacheManager = cachingProvider.getCacheManager();
Cache<Object, Object> cache = cacheManager.getCache( ... );
ICache<Object, Object> unwrappedCache = cache.unwrap( ICache.class );After unwrapping the Cache instance into an ICache instance, you have
access to all the following operations, e.g.,
ICache Async Methods and ICache Convenience Methods.
ICache Configuration
As mentioned in the JCache Declarative Configuration section, the Hazelcast ICache extension offers additional configuration properties over the default JCache configuration. These additional properties include internal storage format, backup counts, eviction policy and split-brain protection reference.
The declarative configuration for ICache is a superset of the previously discussed JCache configuration:
<hazelcast>
...
<cache name="*">
<!-- ... default cache configuration goes here ... -->
<backup-count>1</backup-count>
<async-backup-count>1</async-backup-count>
<in-memory-format>BINARY</in-memory-format>
<eviction size="10000" max-size-policy="ENTRY_COUNT" eviction-policy="LRU" />
<partition-lost-listeners>
<partition-lost-listener>CachePartitionLostListenerImpl</partition-lost-listener>
</partition-lost-listeners>
<split-brain-protection-ref>split-brain-protection-name</split-brain-protection-ref>
<disable-per-entry-invalidation-events>true</disable-per-entry-invalidation-events>
</cache>
...
</hazelcast>hazelcast:
cache:
"*":
backup-count: 1
async-backup-count: 0
in-memory-format: BINARY
eviction:
size: 10000
max-size-policy: ENTRY_COUNT
eviction-policy: LRU
partition-lost-listeners:
- CachePartitionLostListenerImpl
split-brain-protection-ref: split-brain-protection-name
disable-per-entry-invalidation-events: true-
backup-count: Number of synchronous backups. Those backups are executed before the mutating cache operation is finished. The mutating operation is blocked. Its default value is 1. -
async-backup-count: Number of asynchronous backups. Those backups are executed asynchronously so the mutating operation is not blocked and it is done immediately. Its default value is 0. -
in-memory-format: Internal storage format. For more information, see the in-memory format section. Its default value isBINARY. -
eviction: Defines the used eviction strategies and sizes for the cache. For more information about eviction, see the JCache Eviction section.-
size: Maximum number of records or maximum size in bytes depending on themax-size-policyproperty. Size can be any integer between0andInteger.MAX_VALUE. The defaultmax-size-policyisENTRY_COUNTand its default size is10.000. -
max-size-policy: Maximum size. If maximum size is reached, the cache is evicted based on the eviction policy. Defaultmax-size-policyisENTRY_COUNTand its default size is10.000. The following eviction policies are available:-
ENTRY_COUNT: Maximum number of the entries in cache. Based on this number, Hazelcast calculates an approximate maximum size for each partition. See the Eviction Algorithm section for more details. Available on heap based cache record store only. -
USED_NATIVE_MEMORY_SIZE: Maximum used native memory size in megabytes per cache for each Hazelcast instance. Available on High-Density Memory cache record store only. -
USED_NATIVE_MEMORY_PERCENTAGE: Maximum used native memory size percentage per cache for each Hazelcast instance. Available on High-Density Memory cache record store only. -
FREE_NATIVE_MEMORY_SIZE: Minimum free native memory size in megabytes for each Hazelcast instance. Available on High-Density Memory cache record store only. -
FREE_NATIVE_MEMORY_PERCENTAGE: Minimum free native memory size percentage for each Hazelcast instance. Available on High-Density Memory cache record store only.
-
-
eviction-policy: Eviction policy that compares values to find the best matching eviction candidate. Its default value isLRU.
-
-
partition-lost-listeners: Defines listeners for dispatching partition lost events for the cache. For more information, see the ICache Partition Lost Listener section. -
split-brain-protection-ref: Name of the split-brain protection configuration that you want this cache to use. -
disable-per-entry-invalidation-events: Disables invalidation events for each entry; but full-flush invalidation events are still enabled. Full-flush invalidation means the invalidation of events for all entries whenclearis called. Its default value isfalse.
Since javax.cache.configuration.MutableConfiguration misses the above
additional configuration properties, Hazelcast ICache extension
provides an extended configuration class called com.hazelcast.config.CacheConfig.
This class is an implementation of javax.cache.configuration.CompleteConfiguration
and all the properties shown above can be configured
using its corresponding setter methods.
| ICache can be configured only programmatically on the client side. |
ICache Async Methods
As another addition of Hazelcast ICache over the normal JCache specification,
Hazelcast provides asynchronous versions of almost
all methods, returning a java.util.concurrent.CompletionStage. By using these
methods and the returned objects, you can use JCache in a reactive way by
registering dependent computation stages on the returned CompletionStage
to prevent blocking the current thread.
The asynchronous versions of the methods append the phrase Async to the method
name. The example code below uses the method putAsync().
ICache<Integer, String> unwrappedCache = cache.unwrap(ICache.class);
CompletionStage<String> stage = unwrappedCache.getAndPutAsync(1, "value");
stage.thenAcceptAsync(v -> System.out.println("Previous value: " + v));Following methods are available in asynchronous versions:
-
get(key):-
getAsync(key) -
getAsync(key, expiryPolicy)
-
-
put(key, value):-
putAsync(key, value) -
putAsync(key, value, expiryPolicy)
-
-
putIfAbsent(key, value):-
putIfAbsentAsync(key, value) -
putIfAbsentAsync(key, value, expiryPolicy)
-
-
getAndPut(key, value):-
getAndPutAsync(key, value) -
getAndPutAsync(key, value, expiryPolicy)
-
-
remove(key):-
removeAsync(key)
-
-
remove(key, value):-
removeAsync(key, value)
-
-
getAndRemove(key):-
getAndRemoveAsync(key)
-
-
replace(key, value):-
replaceAsync(key, value) -
replaceAsync(key, value, expiryPolicy)
-
-
replace(key, oldValue, newValue):-
replaceAsync(key, oldValue, newValue) -
replaceAsync(key, oldValue, newValue, expiryPolicy)
-
-
getAndReplace(key, value):-
getAndReplaceAsync(key, value) -
getAndReplaceAsync(key, value, expiryPolicy)
-
The methods with a given javax.cache.expiry.ExpiryPolicy are further discussed in the
Defining a Custom ExpiryPolicy.
| Asynchronous versions of the methods are not compatible with synchronous events. |
Defining a Custom ExpiryPolicy
The JCache specification has an option to configure a single ExpiryPolicy
per cache. Hazelcast ICache extension
offers the possibility to define a custom ExpiryPolicy per key by providing
a set of method overloads with an expirePolicy
parameter, as in the list of asynchronous methods in the Async Methods section. This means that you can pass custom expiry policies to
a cache operation.
Here is how an ExpiryPolicy is set on JCache configuration:
CompleteConfiguration<String, String> config =
new MutableConfiguration<String, String>()
.setExpiryPolicyFactory(
AccessedExpiryPolicy.factoryOf( Duration.ONE_MINUTE )
);To pass a custom ExpiryPolicy, a set of overloads is provided. You can use
them as shown in the following code example.
ICache<Integer, String> unwrappedCache = cache.unwrap( ICache.class );
unwrappedCache.put( 1, "value", new AccessedExpiryPolicy( Duration.ONE_DAY ) );The ExpiryPolicy instance can be pre-created, cached and re-used, but only for
each cache instance. This is because ExpiryPolicy
implementations can be marked as java.io.Closeable. The following list shows
the provided method overloads over javax.cache.Cache
by com.hazelcast.cache.ICache featuring the ExpiryPolicy parameter:
-
get(key):-
get(key, expiryPolicy)
-
-
getAll(keys):-
getAll(keys, expirePolicy)
-
-
put(key, value):-
put(key, value, expirePolicy)
-
-
getAndPut(key, value):-
getAndPut(key, value, expirePolicy)
-
-
putAll(map):-
putAll(map, expirePolicy)
-
-
putIfAbsent(key, value):-
putIfAbsent(key, value, expirePolicy)
-
-
replace(key, value):-
replace(key, value, expirePolicy)
-
-
replace(key, oldValue, newValue):-
replace(key, oldValue, newValue, expirePolicy)
-
-
getAndReplace(key, value):-
getAndReplace(key, value, expirePolicy)
-
Asynchronous method overloads are not listed here. See the ICache Async Methods section for the list of asynchronous method overloads.
ICache also offers setExpiryPolicy(key, expirePolicy) method to associate certain
keys with custom expiry policies.
Per key expiry policies defined by this method take precedence over cache policies,
but they are overridden by the expiry policies specified in above-mentioned overloaded methods.
JCache Eviction
Caches are generally not expected to grow to an infinite size. Implementing an expiry policy is one way you can prevent infinite growth, but sometimes it is hard to define a meaningful expiration timeout. Therefore, Hazelcast JCache provides the eviction feature. Eviction offers the possibility of removing entries based on the cache size or amount of used memory (Hazelcast Enterprise Edition Only) and not based on timeouts.
| By default, eviction for Hazelcast JCache is enabled (it cannot be disabled), and its default value is LRU. Hence, it is not possible to configure Hazelcast JCache without eviction. |
Eviction and Runtime
Since a cache is designed for high throughput and fast reads, Hazelcast put a lot of effort into designing the eviction system to be as predictable as possible. All built-in implementations provide an amortized O(1) runtime. The default operation runtime is rendered as O(1), but it can be faster than the normal runtime cost if the algorithm finds an expired entry while sampling.
Cache Types
Most importantly, typical production systems have two common types of caches:
-
Reference Caches: Caches for reference data are normally small and are used to speed up the de-referencing as a lookup table. Those caches are commonly tend to be small and contain a previously known, fixed number of elements, e.g., states of the USA or abbreviations of elements.
-
Active DataSet Caches: The other type of caches normally caches an active data set. These caches run to their maximum size and evict the oldest or not frequently used entries to keep in memory bounds. They sit in front of a database or HTML generators to cache the latest requested data.
Hazelcast JCache eviction supports both types of caches using a slightly different approach based on the configured maximum size of the cache. For detailed information, see the Eviction Algorithm section.
Configuring Eviction Policies
Hazelcast JCache provides two commonly known eviction policies, LRU and LFU,
but loosens the rules for predictable runtime
behavior. LRU, normally recognized as Least Recently Used, is implemented
as Less Recently Used and LFU known as Least Frequently Used is implemented as
Less Frequently Used. The details about this difference are explained in the
Eviction Algorithm section.
Eviction Policies are configured by providing the corresponding abbreviation to the configuration as shown in the ICache Configuration section. As already mentioned, two built-in policies are available:
To configure the use of the LRU (Less Recently Used) policy:
<eviction size="10000" max-size-policy="ENTRY_COUNT" eviction-policy="LRU" />And to configure the use of the LFU (Less Frequently Used) policy:
<eviction size="10000" max-size-policy="ENTRY_COUNT" eviction-policy="LFU" />The default eviction policy is LRU. Therefore, Hazelcast JCache does not offer the possibility of performing no eviction.
Custom Eviction Policies
Besides the out-of-the-box eviction policies LFU and LRU, you can also specify your custom eviction policies through the eviction configuration either programmatically or declaratively.
You can provide your com.hazelcast.cache.CacheEvictionPolicyComparator
implementation to compare com.hazelcast.cache.CacheEntryViews. Supplied
CacheEvictionPolicyComparator is used to compare cache entry views to
select the one with higher priority to evict.
Here is an example for custom eviction policy comparator implementation for JCache:
public class MyCacheEvictionPolicyComparator
implements CacheEvictionPolicyComparator<Long, String> {
@Override
public int compare(CacheEntryView<Long, String> e1, CacheEntryView<Long, String> e2) {
long id1 = e1.getKey();
long id2 = e2.getKey();
if (id1 > id2) {
// first entry has higher priority to be evicted
return -1;
}
if (id1 < id2) {
// second entry has higher priority to be evicted
return 1;
}
// both entries have same priority
return 0;
}
}Custom eviction policy comparator can be specified through the eviction configuration
by giving the full class name of the EvictionPolicyComparator
(CacheEvictionPolicyComparator for JCache and its Near Cache)
implementation or by specifying its instance itself.
Programmatic Configuration:
You can specify the full class name of custom EvictionPolicyComparator
(CacheEvictionPolicyComparator for JCache and its Near Cache) implementation
through EvictionConfig. This approach is useful when the eviction configuration
is specified on the client side
and the custom EvictionPolicyComparator implementation class itself does not
exist on the client but on the member side.
CacheConfig cacheConfig = new CacheConfig();
...
EvictionConfig evictionConfig =
new EvictionConfig(50000,
MaxSizePolicy.ENTRY_COUNT,
"com.mycompany.MyEvictionPolicyComparator");
cacheConfig.setEvictionConfig(evictionConfig);You can specify the custom EvictionPolicyComparator (CacheEvictionPolicyComparator
for JCache and its Near Cache) instance itself directly through EvictionConfig.
CacheConfig cacheConfig = new CacheConfig();
...
EvictionConfig evictionConfig =
new EvictionConfig(50000,
MaxSizePolicy.ENTRY_COUNT,
new MyEvictionPolicyComparator());
cacheConfig.setEvictionConfig(evictionConfig);Declarative Configuration:
You can specify the full class name of custom EvictionPolicyComparator
(CacheEvictionPolicyComparator for JCache and its Near Cache) implementation
in the <eviction> tag through comparator-class-name or comparator-bean attributes in Hazelcast
configuration files:
<hazelcast>
...
<cache name="cacheWithCustomEvictionPolicyComparator">
<eviction size="50000" max-size-policy="ENTRY_COUNT" comparator-class-name="com.mycompany.MyEvictionPolicyComparator"/>
</cache>
...
</hazelcast>hazelcast:
cache:
cacheWithCustomEvictionPolicyComparator:
eviction:
size: 50000
max-size-policy: ENTRY_COUNT
expiry-policy-factory:
class-name: com.mycompany.MyEvictionPolicyComparator<hz:cache name="cacheWithCustomEvictionPolicyComparator">
<hz:eviction size="50000" max-size-policy="ENTRY_COUNT" comparator-class-name="com.mycompany.MyEvictionPolicyComparator"/>
</hz:cache>Eviction Strategy
Eviction strategies implement the logic of selecting one or more eviction candidates from the underlying storage implementation and passing them to the eviction policies. Hazelcast JCache provides an amortized O(1) cost implementation for this strategy to select a fixed number of samples from the current partition that it is executed against.
The default implementation is com.hazelcast.cache.impl.eviction.impl.strategy.sampling.SamplingBasedEvictionStrategy which, as
mentioned, samples 15 random elements. A detailed description
of the algorithm will be explained in the next section.
Eviction Algorithm
The Hazelcast JCache eviction algorithm is specially designed for the use case of high performance caches and with predictability in mind. The built-in implementations provide an amortized O(1) runtime and therefore provide a highly predictable runtime behavior which does not rely on any kind of background threads to handle the eviction. Therefore, the algorithm takes some assumptions into account to prevent network operations and concurrent accesses.
As an explanation of how the algorithm works, let’s examine the following flowchart step by step.
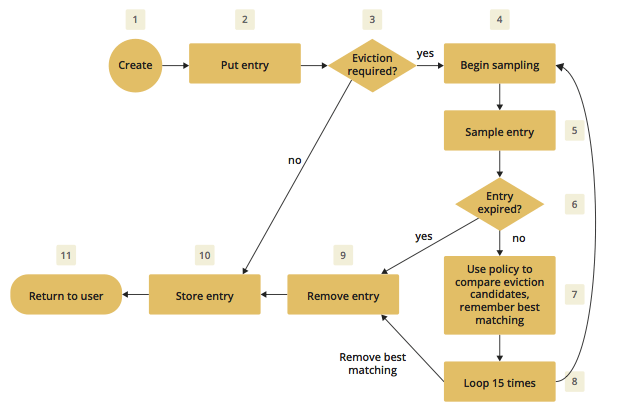
-
A new cache is created. Without any special settings, the eviction is configured to kick in when the cache exceeds 10.000 elements and an LRU (Less Recently Used) policy is set up.
-
The user puts in a new entry, e.g., a key-value pair.
-
For every put, the eviction strategy evaluates the current cache size and decides if an eviction is necessary or not. If not, the entry is stored in step 10.
-
If eviction is required, a new sampling is started. The built-in sampler is implemented as a lazy iterator.
-
The sampling algorithm selects a random sample from the underlying data storage.
-
The eviction strategy tests whether the sampled entry is already expired (lazy expiration). If expired, the sampling stops and the entry is removed in step 9.
-
If not yet expired, the entry (eviction candidate) is compared to the last best matching candidate (based on the eviction policy) and the new best matching candidate is remembered.
-
The sampling is repeated 15 times and then the best matching eviction candidate is returned to the eviction strategy.
-
The expired or best matching eviction candidate is removed from the underlying data storage.
-
The new put entry is stored.
-
The put operation returns to the user.
| Note that expiration based eviction does not only occur for the above scenario (Step 6). It is mentioned for the sake of explaining the eviction algorithm. |
As seen in the flowchart, the general eviction operation is easy. As long as the cache does not reach its maximum capacity, or you execute updates (put/replace), no eviction is executed.
To prevent network operations and concurrent access, as mentioned earlier, the cache size is estimated based on the size of the currently handled partition. Due to the imbalanced partitions, the single partitions might start to evict earlier than the other partitions.
As mentioned in the Cache Types section, typically two types of caches are found in the production systems. For small caches, referred to as Reference Caches, the eviction algorithm has a special set of rules depending on the maximum configured cache size. See the Reference Caches section for details. The other type of cache is referred to as an Active DataSet Cache, which in most cases makes heavy use of the eviction to keep the most active data set in the memory. Those kinds of caches use a very simple but efficient way to estimate the cluster-wide cache size.
All the following calculations have a well known set of fixed variables:
-
GlobalCapacity: User defined maximum cache size (cluster-wide). -
PartitionCount: Number of partitions in the cluster (defaults to 271). -
BalancedPartitionSize: Number of elements in a balanced partition state,BalancedPartitionSize := GlobalCapacity / PartitionCount. -
Deviation: An approximated standard deviation (tests proofed it to be pretty near),Deviation := sqrt(BalancedPartitionSize).
Reference Caches
A Reference Cache is typically small and the number of elements to store in the reference caches is normally known prior to creating the cache. Typical examples of reference caches are lookup tables for abbreviations or the states of a country. They tend to have a fixed but small element number and the eviction is an unlikely event and rather undesirable behavior.
Since an imbalanced partition is a worse problem in small and mid-sized caches than in caches with millions of entries, the normal estimation rule (as discussed in a bit) is not applied to these kinds of caches. To prevent unwanted eviction on the small and mid-sized caches, Hazelcast implements a special set of rules to estimate the cluster size.
To adjust the imbalance of partitions as found in the typical runtime, the actual calculated maximum cache size (known as the eviction threshold) is slightly higher than the user defined size. That means more elements can be stored into the cache than expected by the user. This needs to be taken into account especially for large objects, since those can easily exceed the expected memory consumption!
Small caches:
If a cache is configured with no more than 4.000 elements, this cache
is considered to be a small cache. The actual partition
size is derived from the number of elements (GlobalCapacity) and
the deviation using the following formula:
MaxPartitionSize := Deviation * 5 + BalancedPartitionSizeThis formula ends up with big partition sizes which, summed up, exceed the expected maximum cache size (set by the user). Since the small caches typically have a well known maximum number of elements, this is not a big issue. Only if the small caches are used for a use case other than as a reference cache, this needs to be taken into account.
Mid-sized caches
A mid-sized cache is defined as a cache with a maximum number of
elements that is bigger than 4.000 but not bigger than
1.000.000 elements. The calculation of mid-sized caches is similar
to that of the small caches but with a different
multiplier. To calculate the maximum number of elements per partition,
the following formula is used:
MaxPartitionSize := Deviation * 3 + BalancedPartitionSizeActive DataSet Caches
For large caches, where the maximum cache size is bigger than
1.000.000 elements, there is no additional calculation needed. The maximum
partition size is considered to be equal to BalancedPartitionSize
since statistically big partitions are expected to almost
balance themselves. Therefore, the formula is as easy as the following:
MaxPartitionSize := BalancedPartitionSizeCache Size Estimation
As mentioned earlier, Hazelcast JCache provides an estimation algorithm to prevent cluster-wide network operations, concurrent access to other partitions and background tasks. It also offers a highly predictable operation runtime when the eviction is necessary.
The estimation algorithm is based on the previously calculated maximum partition size (see the Reference Caches and Active DataSet Caches sections) and is calculated against the current partition only.
The algorithm to reckon the number of stored entries in the cache (cluster-wide) and decide if the eviction is necessary is shown in the following pseudo-code example:
RequiresEviction[Boolean] := CurrentPartitionSize >= MaxPartitionSizeJCache Near Cache
The Hazelcast JCache implementation supports a local Near Cache for remotely stored entries to increase the performance of local read operations. See the Near Cache section for a detailed explanation of the Near Cache feature and its configuration.
| Near Cache for JCache is only available for clients, NOT members. |
ICache Convenience Methods
In addition to the operations explained in ICache Async Methods and Defining a Custom ExpiryPolicy, Hazelcast ICache also provides a set of convenience methods. These methods are not part of the JCache specification.
-
size(): Returns the total entry count of the distributed cache. -
destroy(): Destroys the cache and removes its data, which makes it different from the methodjavax.cache.Cache.close(); theclosemethod closes the cache so no further operational methods (get, put, remove, etc. See Section 4.1.6 in JCache Specification which can be downloaded from here) can be executed on it - data is not necessarily destroyed, if you get again the sameCachefrom the sameCacheManager, the data will be there. In the case ofdestroy(), both the cache is destroyed and cache’s data is removed. -
isDestroyed(): Determines whether the ICache instance is destroyed or not. -
getLocalCacheStatistics(): Returns acom.hazelcast.cache.CacheStatisticsinstance, both on Hazelcast members and clients, providing the same statistics data as the JMX beans.
See the ICache Javadoc to see all the methods provided by ICache.
Implementing BackupAwareEntryProcessor
Another feature, especially interesting for distributed environments
like Hazelcast, is the JCache specified
javax.cache.processor.EntryProcessor. For more general information,
see the Implementing EntryProcessor section.
Since Hazelcast provides backups of cached entries on other members,
the default way to backup an object changed by an
EntryProcessor is to serialize the complete object and send it to the
backup partition. This can be a huge network overhead for big objects.
Hazelcast offers a sub-interface for EntryProcessor called
com.hazelcast.cache.BackupAwareEntryProcessor. This allows
you to create or pass another EntryProcessor to run on backup
partitions and apply delta changes to the backup entries.
The backup partition EntryProcessor can either be the currently
running processor (by returning this) or it can be
a specialized EntryProcessor implementation (different from the
currently running one) that does different operations or leaves
out operations, e.g., sending emails.
If we again take the EntryProcessor example from the
demonstration application provided in the Implementing EntryProcessor section,
the changed code looks like the following snippet:
public class UserUpdateEntryProcessor
implements BackupAwareEntryProcessor<Integer, User, User> {
@Override
public User process( MutableEntry<Integer, User> entry, Object... arguments )
throws EntryProcessorException {
// Test arguments length
if ( arguments.length < 1 ) {
throw new EntryProcessorException( "One argument needed: username" );
}
// Get first argument and test for String type
Object argument = arguments[0];
if ( !( argument instanceof String ) ) {
throw new EntryProcessorException(
"First argument has wrong type, required java.lang.String" );
}
// Retrieve the value from the MutableEntry
User user = entry.getValue();
// Retrieve the new username from the first argument
String newUsername = ( String ) arguments[0];
// Set the new username
user.setUsername( newUsername );
// Set the changed user to mark the entry as dirty
entry.setValue( user );
// Return the changed user to return it to the caller
return user;
}
public EntryProcessor<Integer, User, User> createBackupEntryProcessor() {
return this;
}
}You can use the additional method
BackupAwareEntryProcessor.createBackupEntryProcessor()
to create or return the EntryProcessor
implementation to run on the backup partition (in the
example above, the same processor again).
| For the backup runs, the returned value from the backup processor is ignored and not returned to the user. |
ICache Partition Lost Listener
You can listen to CachePartitionLostEvent instances
by registering an implementation
of CachePartitionLostListener, which is also a
sub-interface of java.util.EventListener
from ICache.
Let’s consider the following example code:
public class PartitionLostListenerUsage {
public static void main(String[] args) {
String cacheName1 = "myCache1";
CachingProvider cachingProvider = Caching.getCachingProvider();
CacheManager cacheManager = cachingProvider.getCacheManager();
CacheConfig<Integer, String> config1 = new CacheConfig<Integer, String>();
Cache<Integer, String> cache1 = cacheManager.createCache(cacheName1, config1);
ICache<Object, Object> unwrappedCache = cache1.unwrap( ICache.class );
unwrappedCache.addPartitionLostListener(new CachePartitionLostListener() {
@Override
public void partitionLost(CachePartitionLostEvent event) {
System.out.println(event);
}
});
}
}Within this example code, a CachePartitionLostListener implementation
is registered to a cache and assumes that this cache is configured with
one backup. For this particular cache and any of the partitions in the
system, if the partition owner member and its first backup member
crash simultaneously, the
given CachePartitionLostListener receives a
corresponding CachePartitionLostEvent. If only a single member
crashes in the cluster,
a CachePartitionLostEvent is not fired for this cache since
backups for the partitions
owned by the crashed member are kept on other members.
See the Partition Lost Listener section for more information about partition lost detection and partition lost events.
