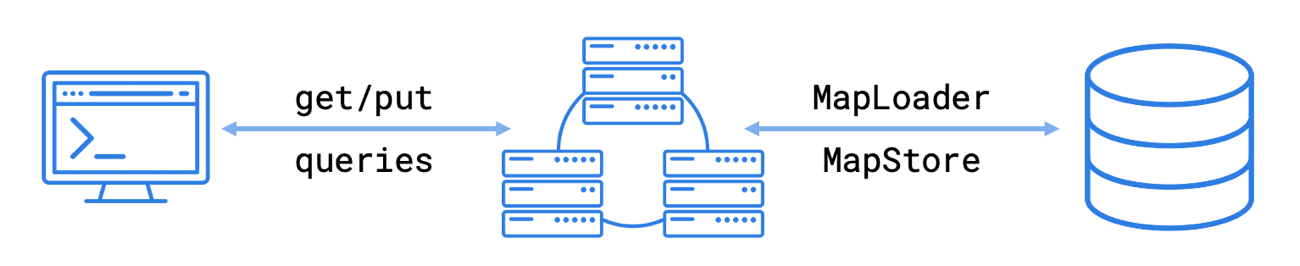
One of the most common implementations of Hazelcast is as a front-end cache for an external storage system, such as a relational database. Hazelcast offers a way to automate the process of loading the data into an in-memory map for faster application access, as well as automatically write updates back to the external storage to keep the systems synchronized.
Applications that access in-memory data are using gets, puts, or performing queries as described elsewhere in this documentation. When you work with an external data store, the Hazelcast cluster members are retrieving data from and writing data to that external data store independently of the application.
| This feature is a server-side feature. Because these operations run within the Hazelcast cluster natively, the interfaces that perform these functions are only available in Java. |
To load data from external systems in a map you will use the Java MapLoader interface.
To save map entries to an external system, you will use the Java MapStore interface.
| Interface | Description |
|---|---|
|
This method gets invoked when the application requests a value from the map. If the requested value does not exist in memory, the |
|
This method replicates updates to the in-memory map data to the data store. This replication can be implemented as a blocking (write-through) or non-blocking (write-behind) operation. (See below for details.) |
| The data store that you choose must be a centralized system that is accessible from all Hazelcast members. Persistence to a local file system is not supported. |
The MapStore interface extends the MapLoader interface. Therefore, all methods and configuration parameters of the MapLoader interface are also available on the MapStore interface.
|
Loading Data From Your External Store
Read-Through Persistence
When you have MapLoader implemented, a map.get() triggers the load() method if the requested entry does not exist in memory. The MapLoader retrieves the requested entry, hands it to Hazelcast, which adds it to the in-memory map. This automatic loading is called read-through persistence.
Map Initialization
Although read-through persistence will retrieve a requested map entry from the external data store, retrieving each individual entry as it is requested is inefficient. Instead, use the MapLoader.loadAllKeys() method to pre-populate your in-memory map. When used, each Hazelcast cluster member connects to the database to retrieve its owned portion of the map. This parallel processing is the fastest way to retrieve entries from the data store.
You have two options for pre-populating your map.
| Initial Mode | Behavior |
|---|---|
|
The |
|
After getting or creating the map, the |
If you add indices to your map with the IndexConfig
class or the addIndex method, then the initial-mode property is overridden by EAGER.
|
If your implementation of the MapLoader.loadAllKeys() method returns a null value, nothing will be loaded. Your MapLoader.loadAllKeys() method can also return all or some of the keys, depending on how you set up your MapLoader implementation. For example, you can specify a range of keys to be pre-loaded, then rely on read-through persistence to load the remaining keys on demand.
Here’s the MapLoader initialization process in detail:
-
Initialization starts depending on the value of the
initial-modeproperty. If it is set toEAGER, initialization starts on all partitions as soon as the map is created (i.e. whenmap.get()is called). If it is set toLAZY, data is loaded when amap.get()or other operation tries to read an entry from the map. -
Hazelcast calls the
MapLoader.loadAllKeys()to get all your keys on one of the members. -
That member distributes keys to all other members in batches.
-
Each member loads values of all its owned keys by calling
MapLoader.loadAll(keys)for their own keys. -
Each member puts its owned entries into the map by calling
IMap.putTransient(key,value).
If the load mode is LAZY and the clear() method is called (which triggers MapStore.deleteAll()), Hazelcast removes ONLY the
loaded entries from your map and data store. Since all the data is not loaded in this case (LAZY mode), please note that there may still be entries in your data store.
|
If you do not want the MapStore start to load as soon as the first cluster member starts, you can use the system property hazelcast.initial.min.cluster.size. For example, if you set its value as 3, loading process will be blocked until three cluster members are completely up.
|
Loading Keys Incrementally
If the number of keys to load is large, it is more efficient to load them incrementally rather than loading them all at once. To support
incremental loading, the MapLoader.loadAllKeys() method returns an Iterable which can be lazily populated with the results of a database query. Hazelcast iterates over the returned data and, while doing so, sends the keys to their respective owner members. The iterator that was returned from the MapLoader.loadAllKeys() may also implement the Closeable interface, in which case the iterator is closed when the iteration is over. This is intended for releasing resources such as closing a JDBC result set.
Writing Data to Your External Store
Write-Through Persistence
Write-through persistence performs synchronous updates to both the map and the external data store. When implemented, the map.put(key,value) call triggers the following actions in order:
-
Call
MapStore.store(key,value)- this writes the entry to the external data store. -
Write entry to in-memory primary map.
-
Write entry to backup maps, if configured (i.e. if the
backup-countproperty is greater than 0).
If the MapStore.store(key,value) method throws an exception, it is propagated to the original IMap.put() or IMap.remove() call in the form of RuntimeException.
The same behavior goes for the map.remove(key), the only difference is that MapStore.delete(key) is called when the entry will be deleted.
Write-Behind Persistence
Write-behind persistence performs asynchronous updates to the external data store. When triggered, the map.put(key,value) call triggers the following actions in order:
-
Write entry to primary map.
-
Write entry to backup maps, if configured.
-
Mark entry as "dirty" - entry has not been written to external store.
-
After
write-delay-secondshas elapsed, write entry to external store using definedMapStore.storeAll.
write-delay-seconds is the interval between writes to the external store. For example, if you configure an interval of 5 seconds, every 5 seconds the cluster will store all "dirty" entries. In other words, the longest delay between writing to memory and writing to the store will be 5 seconds, but for any given entry, it could be less depending on when the map.put occurred. Another way to to look at write-behind is as scheduled batch update at given intervals.
For fault tolerance, dirty entries are stored in a queue on the primary member and also on a back-up member. If you have eviction configured, the eviction process overrides the timer and forces dirty entries to be stored in order to empty the queue and free up memory.
If MapStore throws an exception, then Hazelcast tries to store the entry again. If the entry still cannot be stored, the cluster logs the event and re-queues the entry.
In write-behind mode, Hazelcast coalesces enqueued updates on a specific key by default. Only the most recent enqueued update for each key will be written when the write-delay-seconds interval has elapsed. You can override this and write all enqueued updates by setting the MapStoreConfig.setWriteCoalescing() system property to FALSE.
When you set MapStoreConfig.setWriteCoalescing() to FALSE, after you reached per-node maximum write-behind-queue capacity, subsequent put operations will fail with ReachedMaxSizeException. This exception is thrown to prevent uncontrolled grow of write-behind queues. You can set per-node maximum capacity using the system property hazelcast.map.write.behind.queue.capacity. See the System Properties appendix for information about this property and how to set the system properties.
|
Batch Updates
Batch operations are only allowed in write-behind mode. If your application performs a batch update or batch delete from the in-memory map, Hazelcast will call the MapStore.storeAll(map) and MapStore.deleteAll(collection) methods defined in your MapStore class to do all writes in a single call.
Creating the MapStore Implementation
The following example shows you how to implement the MapStore interface.
public class PersonMapStore implements MapStore<Long, Person> {
private final Connection con;
private final PreparedStatement allKeysStatement;
public PersonMapStore() {
try {
con = DriverManager.getConnection("jdbc:hsqldb:mydatabase", "SA", "");
con.createStatement().executeUpdate(
"create table if not exists person (id bigint not null, name varchar(45), primary key (id))");
allKeysStatement = con.prepareStatement("select id from person");
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
public synchronized void delete(Long key) {
System.out.println("Delete:" + key);
try {
con.createStatement().executeUpdate(
format("delete from person where id = %s", key));
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
public synchronized void store(Long key, Person value) {
try {
con.createStatement().executeUpdate(
format("insert into person values(%s,'%s')", key, value.getName()));
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
public synchronized void storeAll(Map<Long, Person> map) {
for (Map.Entry<Long, Person> entry : map.entrySet()) {
store(entry.getKey(), entry.getValue());
}
}
public synchronized void deleteAll(Collection<Long> keys) {
for (Long key : keys) {
delete(key);
}
}
public synchronized Person load(Long key) {
try {
ResultSet resultSet = con.createStatement().executeQuery(
format("select name from person where id =%s", key));
try {
if (!resultSet.next()) {
return null;
}
String name = resultSet.getString(1);
return new Person(key, name);
} finally {
resultSet.close();
}
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
public synchronized Map<Long, Person> loadAll(Collection<Long> keys) {
Map<Long, Person> result = new HashMap<Long, Person>();
for (Long key : keys) {
result.put(key, load(key));
}
return result;
}
public Iterable<Long> loadAllKeys() {
return new StatementIterable<Long>(allKeysStatement);
}
}During the initial loading process, the MapStore interface uses an ExecutorService thread, not a partition thread, in order to avoid affecting ongoing partition operations. After the initial loading process, the IMap.get() and IMap.put() methods use a partition thread.
MapStore or MapLoader implementations should not use Hazelcast Map/Queue/MultiMap/List/Set operations. Your implementation should
only work with your data store. Otherwise, you may get into deadlock situations.
|
To monitor the MapLoader instance for each loaded entry, use the EntryLoadedListener interface. See the Listening for Map Events section to learn how you can catch entry-based events.
|
Forcing All Keys To Be Loaded
The MapLoader.loadAll() method loads some or all keys into a data store in order to optimize multiple load operations. This method has two signatures (the same method can take two different parameter lists). One signature loads the given keys and the other loads all keys. See the example code below.
final int numberOfEntriesToAdd = 1000;
final String mapName = LoadAll.class.getCanonicalName();
final Config config = createNewConfig(mapName);
final HazelcastInstance node = Hazelcast.newHazelcastInstance(config);
final IMap<Integer, Integer> map = node.getMap(mapName);
populateMap(map, numberOfEntriesToAdd);
System.out.printf("# Map store has %d elements\n", numberOfEntriesToAdd);
map.evictAll();
System.out.printf("# After evictAll map size\t: %d\n", map.size());
map.loadAll(true);
System.out.printf("# After loadAll map size\t: %d\n", map.size());Post-Processing Objects in MapStore
In some scenarios, you may need to modify the object after writing it to the external data store. For example, you can get an ID or version auto-generated by your database, but then need to modify the in-memory entry for local use without writing the change back to the external store.
To post-process an object, implement the PostProcessingMapStore interface to put the modified object into the distributed map. This triggers an extra step of Serialization, so use it only when needed. (This is only valid when using write-through to update your external data store.)
Here is an example of post processing:
class ProcessingStore implements MapStore<Integer, Employee>, PostProcessingMapStore {
@Override
public void store( Integer key, Employee employee ) {
EmployeeId id = saveEmployee();
employee.setId( id.getId() );
}
}| Please note that if you are using post-processing in combination with Entry Processors, post-processed values will not be carried to in-memory backups. |
Configuring Hazelcast to use your MapStore Implementation
Once you’ve created your MapStore implementation, you need to configure your map to use it.
<hazelcast>
...
<map name="default">
<map-store enabled="true" initial-mode="LAZY">
<class-name>com.hazelcast.examples.DummyStore</class-name>
<write-delay-seconds>60</write-delay-seconds>
<write-batch-size>1000</write-batch-size>
<write-coalescing>true</write-coalescing>
</map-store>
</map>
...
</hazelcast>hazelcast:
map:
default:
map-store:
enabled: true
initial-mode: LAZY
class-name: com.hazelcast.examples.DummyStore
write-delay-seconds: 60
write-batch-size: 1000
write-coalescing: trueThe following are the descriptions of MapStore configuration elements and attributes:
-
class-name: Name of the class implementingMapLoaderand/orMapStore. -
write-delay-seconds: Number of seconds to delay to call theMapStore.store(key, value)`. If the value is zero then it is write-through, so theMapStore.store(key,value)method is called as soon as the entry is updated. Otherwise, it is write-behind; so the updates will be stored after thewrite-delay-secondsvalue by calling theHazelcast.storeAll(map)method. Its default value is 0 (write-through). -
write-batch-size: Used to create batch chunks when writing to the external data store. In default mode, all map entries are tried to be written in one go. To create batch chunks, the minimum meaningful value for write-batch-size is 2. For values smaller than 2, it works as in default mode. -
write-coalescing: In write-behind mode, Hazelcast coalesces updates on a specific key by default; it applies only the last update on it. You can set this element tofalseto store all updates performed on a key to the data store. -
enabled: True to enable this map-store, false to disable. Its default value is true. -
initial-mode: Sets the initial load mode. LAZY is the default load mode, where load is asynchronous. EAGER means map operations are blocked until all partitions are loaded.
Setting Expiration Times on Loaded and Stored Data Entries
Entries loaded by MapLoader implementations do not have a set time-to-live property. Therefore, they live until evicted or explicitly removed. To enforce expiration times on the entries, you can use the EntryLoader and EntryStore interfaces.
These interfaces extend the MapLoader and MapStore interfaces. Therefore, all methods and configuration parameters of the MapLoader and
MapStore implementations are also available on the EntryLoader and EntryStore implementations.
|
EntryLoader allows you to set time-to-live values per key before handing the values to Hazelcast. Therefore, you can store and load
key-specific time-to-live values in the external storage.
Similar to EntryLoader, in order to store custom expiration times associated with the entries, you may use EntryStore. EntryStore allows you to retrieve associated expiration date for each entry. The expiration date is an offset from an epoch in milliseconds. Epoch is January 1, 1970 UTC which is used by System.currentTimeMillis().
Although the expiration date is expressed in milliseconds, expiration dates are rounded to the nearest lower whole second because the IMap interface
uses second granularity when it comes to expiration.
|
The following example shows you how to implement the EntryStore interface.
public class PersonEntryStore implements EntryStore<Long, Person> {
private final Connection con;
private final PreparedStatement allKeysStatement;
public PersonEntryStore() {
try {
con = DriverManager.getConnection("jdbc:hsqldb:mydatabase", "SA", "");
con.createStatement().executeUpdate(
"create table if not exists person (id bigint not null, name varchar(45), expiration-date bigint, primary key (id))");
allKeysStatement = con.prepareStatement("select id from person");
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
@Override
public synchronized void delete(Long key) {
System.out.println("Delete:" + key);
try {
con.createStatement().executeUpdate(
format("delete from person where id = %s", key));
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
@Override
public synchronized void store(Long key, MetadataAwareValue<Person> value) {
try {
con.createStatement().executeUpdate(
format("insert into person values(%s,'%s', %d)", key, value.getValue().getName(), value.getExpirationTime()));
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
@Override
public void storeAll(Map<Long, MetadataAwareValue<Person>> map) {
for (Map.Entry<Long, MetadataAwareValue<Person>> entry : map.entrySet()) {
store(entry.getKey(), entry.getValue());
}
}
@Override
public synchronized void deleteAll(Collection<Long> keys) {
for (Long key : keys) {
delete(key);
}
}
@Override
public synchronized MetadataAwareValue<Person> load(Long key) {
try {
ResultSet resultSet = con.createStatement().executeQuery(
format("select name,expiration-date from person where id =%s", key));
try {
if (!resultSet.next()) {
return null;
}
String name = resultSet.getString(1);
Long expirationDate = resultSet.getLong(2);
return new MetadataAwareValue<>(new Person(key, name), expirationDate);
} finally {
resultSet.close();
}
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
@Override
public synchronized Map<Long, MetadataAwareValue<Person>> loadAll(Collection<Long> keys) {
Map<Long, MetadataAwareValue<Person>> result = new HashMap<>();
for (Long key : keys) {
result.put(key, load(key));
}
return result;
}
public Iterable<Long> loadAllKeys() {
return new StatementIterable<Long>(allKeysStatement);
}
}Managing the Lifecycle of a MapLoader
With MapLoader (and MapStore which extends it), you can do the regular store and load operations. If you need to perform other operations on create or on destroy of a MapLoader, such as establishing a connection to a database or accessing to other Hazelcast maps,
you need to implement the MapLoaderLifeCycleSupport interface. By implementing it, you will have the init() and destroy() methods.
The init() method initializes the MapLoader implementation. Hazelcast calls this method when the map is first created on a Hazelcast instance. The MapLoader implementation can initialize the required resources such as reading a configuration file, creating a database connection, or accessing a Hazelcast instance.
The destroy() method is called during the graceful shutdown of a Hazelcast instance. You can override this method to clean up the resources held by the MapLoader implementation, such as closing the database connections.
See here to see this interface in action.
Storing Entries to Multiple Maps
A configuration can be applied to more than one map using wildcards (see Using Wildcards), meaning that the configuration is shared among the maps. But MapStore does not know which entries to store when there is one configuration applied to multiple maps.
To store entries when there is one configuration applied to multiple maps, use Hazelcast’s MapStoreFactory interface. Using the MapStoreFactory interface, MapStores for each map can be created when a wildcard configuration is used. Example code is shown below.
Config config = new Config();
MapConfig mapConfig = config.getMapConfig( "*" );
MapStoreConfig mapStoreConfig = mapConfig.getMapStoreConfig();
mapStoreConfig.setFactoryImplementation( new MapStoreFactory<Object, Object>() {
@Override
public MapLoader<Object, Object> newMapStore( String mapName, Properties properties ) {
return null;
}
});To initialize the MapLoader implementation with the given map name, configuration properties and the Hazelcast instance, implement the
MapLoaderLifecycleSupport interface
which is described in the previous section.
For a list of all IMap methods that trigger the MapLoader methods, see MapStore and MapLoader Methods Triggered by IMap Operations
|
Accessing a Database Using Properties
You can prepare your own MapLoader to access a database such as Cassandra and MongoDB. For this, you can first declaratively specify the database properties in your hazelcast.xml configuration file and then implement the MapLoaderLifecycleSupport interface to pass those properties.
You can define the database properties, such as its URL and name, using the properties configuration element. The following is a configuration example
for MongoDB:
<hazelcast>
...
<map name="supplements">
<map-store enabled="true" initial-mode="LAZY">
<class-name>com.hazelcast.loader.YourMapStoreImplementation</class-name>
<properties>
<property name="mongo.url">mongodb://localhost:27017</property>
<property name="mongo.db">mydb</property>
<property name="mongo.collection">supplements</property>
</properties>
</map-store>
</map>
...
</hazelcast>hazelcast:
map:
supplements:
map-store:
enabled: true
initial-mode: LAZY
class-name: com.hazelcast.loader.YourMapStoreImplementation
properties:
mongo_url: mongodb://localhost:27017
mongo.db: mydb
mango.collection: supplementsAfter specifying the database properties in your configuration, you need to implement the MapLoaderLifecycleSupport interface and
give those properties in the init() method, as shown below:
public class YourMapStoreImplementation implements MapStore<String, Supplement>, MapLoaderLifecycleSupport {
private MongoClient mongoClient;
private MongoCollection collection;
public YourMapStoreImplementation() {
}
@Override
public void init(HazelcastInstance hazelcastInstance, Properties properties, String mapName) {
String mongoUrl = (String) properties.get("mongo.url");
String dbName = (String) properties.get("mongo.db");
String collectionName = (String) properties.get("mongo.collection");
this.mongoClient = new MongoClient(new MongoClientURI(mongoUrl));
this.collection = mongoClient.getDatabase(dbName).getCollection(collectionName);
}See the full example here.
IMap Operations that Trigger MapStore and MapLoader
This section summarizes the IMap operations that may trigger the MapStore or MapLoader methods.
If the initial-mode property of the MapLoader
implementation is set to LAZY, the first time any IMap method
is called, it triggers the MapLoader.loadAllKeys() method.
|
IMap Method |
Impact on the MapStore/MapLoader implementations |
|---|---|
|
This method flushes all the local dirty entries by calling the |
|
These methods are used to put entries to the map. Because |
|
These methods put an entry into the map without returning the old value. If write-through persistence is enabled, they call the `MapStore.store(Object,Object) method to write the entry to write the value to the external data store. |
|
This method removes the mapping for a key from the map if it is present. Because |
|
These methods are used to remove entries from the map for various conditions. They call the |
|
This method updates time-to-live of an existing entry. It calls the |
|
This method the map and deletes the items from the external data store. It calls the |
|
This method replaces the entry for a key only if currently mapped to a given value. It calls the |
|
These methods apply the user-defined entry processors to the entry or entries. They call the |