Hazelcast doesn’t delegate its cluster management and fault tolerance concerns to an outside system like ZooKeeper. Instead, it uses its own implementation of Chandy-Lamport distributed snapshots. If a cluster member fails, Hazelcast will restart the job on the remaining members, restore the state of processing from the last snapshot, and then seamlessly continue from that point.
Processing Guarantee is a Shared Concern
When you configure the processing guarantee for your job as
exactly-once or at-least-once, Hazelcast uses the distributed
snapshotting feature to store all the internal computation state to
an IMap. However, this on its own isn’t enough to provide the
processing guarantee because the snapshot must cover the entire
pipeline, including the external changes performed by sources and sinks.
Hazelcast requires certain guarantees from sources and sinks in a
fault-tolerant data pipeline.
When the job is restarting after a member failure, Hazelcast resets the whole data pipeline to the state of the last snapshot. More technically, processors can save arbitrary data to the snapshot and Hazelcast will present that same data to the processors after a restart. Hazelcast performs such snapshots in regular intervals. Sources can cooperate with the job in multiple ways:
-
Replayable sources: Seek to certain position and re-read events from that positions multiple times. An example is Apache Kafka or an IMap Journal. Such source saves the offset(s) to the snapshot and in case of restart it continues from the saved position.
-
Acknowledging sources: Acknowledge messages after fully processing them. A typical example of an acknowledging source is a JMS queue. Unacknowledged messages are delivered again in case the job fails. Such sources need to do two things: (1) acknowledge messages only after a next snapshot is completed and (2) save message IDs for deduplication to snapshot in case the job fails after a snapshot is completed but before it manages to acknowledge the consumption. Those IDs are used to drop re-delivered messages after a restart.
Sinks can cooperate in different ways:
-
Transactional sinks: such sinks write their output using a transaction and they commit it only after the snapshot is completed. Since there are multiple parallel workers writing the data, each with its own transaction, Hazelcast employs two-phase commit to ensure that either all participants commit or all roll back. An example is JMS, JDBC or Kafka sinks.
-
Idempotent writes: Idempotent operation is an operation that, if performed multiple times, has the same effect as if performed once. An example is writing to an IMap:
map.put("key", "value")has the same effect if you execute it once or twice. Such sinks only need to ensure that all in-flight operations are finished before each snapshot is performed. That is they need to wait for async operations to finish or fsync writes to files. But it’s not enough to just use such a sink: you also need to ensure that the keys are stable. For example if you use random UUID for the key, it won’t work, the job must produce identical keys after a restart. Also, if you process the journal for a map, the journal will contain the update event multiple times.
Distributed Snapshot
The technique Hazelcast uses to achieve fault tolerance is called a “distributed snapshot”, described in a paper by Chandy and Lamport. At regular intervals, Hazelcast raises a global flag that says "it’s time for another snapshot". All processors belonging to source vertices observe the flag, save their state, emit a barrier item to the downstream processors and resume processing.
As the barrier item reaches a processor, it stops what it’s doing and saves its state to the snapshot storage. Once complete, it forwards the barrier item to its downstream processors and resumes. The same story repeats in the downstream processors, eventually reaching the sink processors. When they complete, the snapshot is done.
This is the basic story, but due to parallelism, in most cases a processor receives data from more than one upstream processor. It will receive the barrier item from each of them at separate times, but it must start taking a snapshot at a single point in time. There are two approaches it can take, as explained below.
Exactly-Once
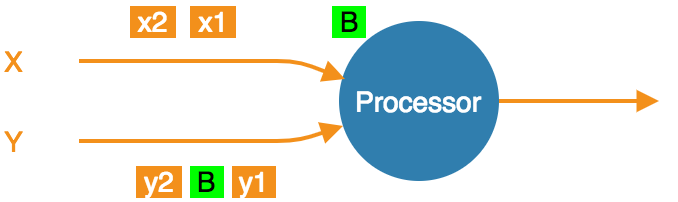
With exactly-once configured, as soon as the processor gets a barrier item in any input stream (from any upstream processor), it must stop consuming it until it gets the same barrier item in all the streams:
-
Stream X is at the barrier, Y not yet. The processor must not accept any more X items.
-
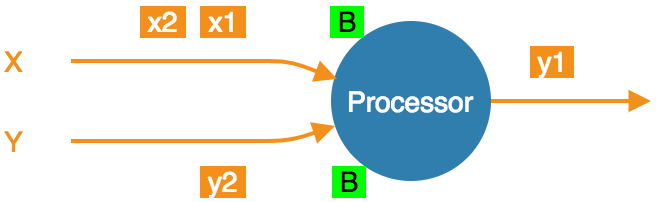
At the barrier in both streams, taking a snapshot.
-
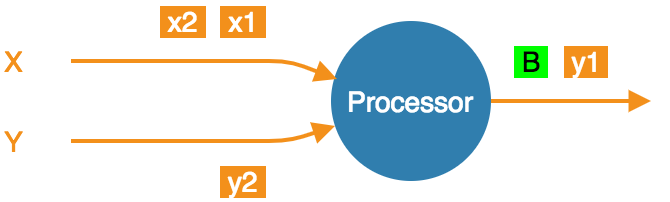
Snapshot done, barrier forwarded. Processor resumes consuming all streams.
At-Least-Once
With at-least-once configured, the processor can keep consuming all the streams until it gets all the barriers, at which point it stops to take the snapshot:
-
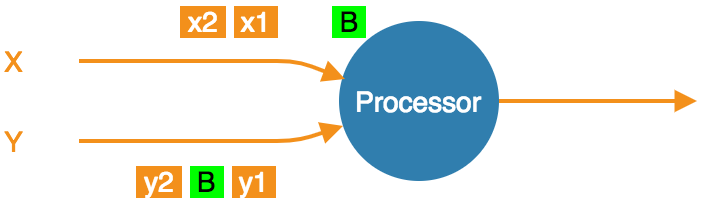
Stream X is at the barrier, Y not yet. Carry on consuming all streams.
-
At the barrier in both streams, already consumed x1 and x2. Taking a snapshot.
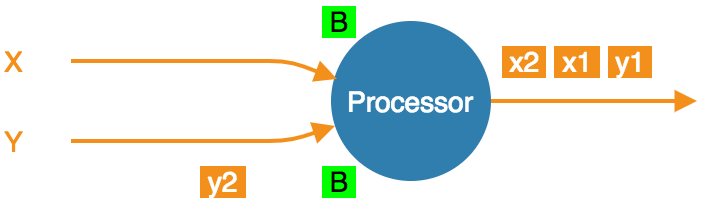
-
Snapshot done, barrier forwarded.
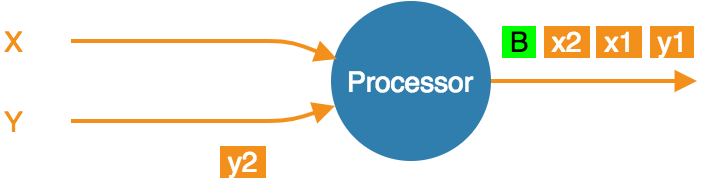
Even though x1 and x2 occur after the barrier, the processor
consumed and processed them before processing the barrier, updating its
state accordingly. If the computation job stops and restarts, this state
will be restored from the snapshot and then the source will replay x1
and x2. The processor will think it got two new items.
Initial Snapshot
Some stateful sources—such as map journal and Kafka—determine their initial reading position at the moment the job starts.
If a job restarts due to a failure before completing its first snapshot, this initial state may be reinitialized and in some cases to a different state.
This can lead to data loss (for example, skipping records already produced but not yet observed by job source).
To prevent this, enable setRequireSnapshotBeforeProcessing(true)
in the job configuration.
Data Safety
In-Memory Snapshot Storage
Hazelcast backs up the state of jobs to its own map objects. Map is a replicated in-memory data structure, storing each key-value pair on a configurable number of cluster members. By default it makes a single backup copy, resulting in a system that tolerates the failure of a single member at a time. The cluster recovers its safety level by re-establishing all the missing backups, and when this is done, another node can fail without data loss. You can set the backup count in the configuration, for example:
hazelcast:
jet:
instance:
backup-count: 2If multiple members fail simultaneously, some data from the backing maps can be lost. Hazelcast detects this by counting the entries in the snapshot map and it won’t run a job with missing data.
Split-Brain Protection
There is a special kind of cluster failure, popularly called the "Split Brain". It occurs due to a complex network failure (a network partition) where the graph of live connections among cluster members falls apart into two islands. In each island it seems like all the other members failed, so the remaining cluster should self-heal and continue working. Now you have two Hazelcast clusters working in parallel, each running all the jobs on all the data.
Hazelcast offers a mechanism to mitigate this risk: split-brain protection. It works by ensuring that a job can be restarted only in a cluster whose size is more than half of what it ever was. Enable split-brain protection like this:
jobConfig.setSplitBrainProtection(true);| Make sure that you resolve the split-brain condition before introducing new members to the cluster. Otherwise, both sub-clusters may grow to more than half of the previous size, circumventing split-brain protection. |
Hazelcast stores Jet job state in distributed map objects and uses their backup configuration for replication.
During a split-brain, the primary partition and all its backups may end up in the same (smaller) sub-cluster,
leaving the larger one without the required snapshot data and causing the job restart to fail.
To reduce this risk, increase the number of job backups using backup-count in the member configuration. See Configuring the Jet Engine.
Disk Snapshot Storage
In-memory snapshot storage doesn’t cover the case when the entire cluster must shut down. To save snapshots to disk, see Persisting Data on Disk.