FencedLock is a linearizable and distributed implementation of
java.util.concurrent.locks.Lock, meaning that if you lock using a FencedLock,
the critical section that it guards is guaranteed to be executed by only one thread
in the entire cluster. Even though locks are great for synchronization, they can lead
to problems if not used properly. Also note that Hazelcast Lock does not support fairness.
For detailed information and configuration, see the Configuring Fenced Locks.
| This data structure is a member of the CP Subsystem. By default, the CP Subsystem is in unsafe mode, which provides weaker consistency guarantees. You can enable the CP Subsystem in the member configuration. |
Fencing Tokens
Distributed locks are unfortunately not equivalent to single-node mutexes
because of the complexities in distributed systems, such as uncertain
communication patterns, and independent and partial failures.
In an asynchronous network, no lock service can guarantee mutual exclusion,
because there is no way to distinguish between a slow and a crashed process.
Consider the following scenario, where a Hazelcast client acquires
a FencedLock, then hits a long GC pause. Since it will not be able to commit
session heartbeats while paused, its CP session will be eventually closed.
After this moment, another Hazelcast client can acquire this lock. If the first
client wakes up again, it may not immediately notice that it has lost ownership
of the lock. In this case, multiple clients think they hold the lock. If they
attempt to perform an operation on a shared resource, they can break
the system. To prevent such situations, you can choose to use an infinite
session timeout, but this time probably you are going to deal with liveness
issues. For the scenario above, even if the first client actually crashes,
the requests sent by two clients can be reordered in the network and hit
the external resource in the reverse order.
There is a simple solution for this problem. Lock holders are ordered by a monotonic fencing token, which increments each time the lock is assigned to a new owner. This fencing token can be passed to external services or resources to ensure sequential execution of the side effects performed by lock holders.
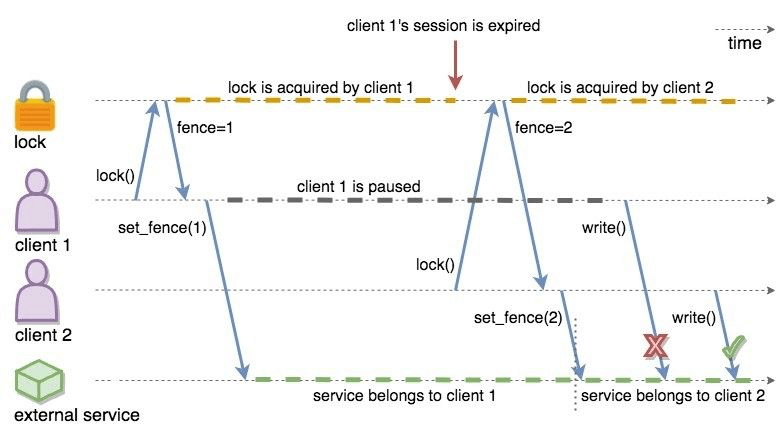
The following diagram illustrates the idea. Client-1 acquires the lock first
and receives 1 as its fencing token. Then, it passes this token to
the external service, which is our shared resource in this scenario. Just after
that, Client-1 hits a long GC pause and eventually loses ownership of the lock
because it misses to commit CP session heartbeats. Then, Client-2 chimes in and
acquires the lock. Similar to Client-1, Client-2 passes its fencing token to
the external service. After that, once Client-1 comes back alive, its write
request will be rejected by the external service, and only Client-2 will be
able to safely talk to it.
You can read more about the fencing token idea in Martin Kleppmann’s
How to do distributed locking
blog post and Google’s Chubby paper.
FencedLock integrates this idea with the j.u.c.locks.Lock abstraction,
excluding j.u.c.locks.Condition. newCondition() is not implemented and
throws UnsupportedOperationException.
All the API methods in the new FencedLock abstraction offer exactly-once
execution semantics. For instance, even if a lock() call is internally
retried because of a crashed CP member, the lock is acquired only once.
The same rule also applies to the other methods in the API.
Using Try-Catch Blocks with Locks
Always use locks with try-catch blocks. This ensures that locks are
released if an exception is thrown from
the code in a critical section. Also note that the lock method is outside
the try-catch block because we do not want to unlock
if the lock operation itself fails.
HazelcastInstance hazelcastInstance = Hazelcast.newHazelcastInstance();
Lock lock = hazelcastInstance.getCPSubsystem().getLock("myLock");
lock.lock();
try {
// do something here
} finally {
lock.unlock();
}Releasing Locks with tryLock Timeout
If a lock is not released in the cluster, another thread that is trying to get the
lock can wait forever. To avoid this, use tryLock with a timeout value. You can
set a high value (normally it should not take that long) for tryLock.
You can check the return value of tryLock as follows:
if ( lock.tryLock ( 10, TimeUnit.SECONDS ) ) {
try {
// do some stuff here..
} finally {
lock.unlock();
}
} else {
// warning
}Understanding Lock Behavior
Locks are not automatically removed. If a lock is not used anymore, Hazelcast
does not automatically perform garbage collection in it.
This can lead to an OutOfMemoryError. If you create locks on the fly,
make sure they are destroyed. See Destroying Objects
and CP Data Structures.
|
-
Locks are fail-safe. If a member holds a lock and some other members go down, the cluster will keep your locks safe and available. Moreover, when a member leaves the cluster, all the locks acquired by that dead member will be removed so that those locks are immediately available for live members.
-
Locks are re-entrant. The same thread can lock multiple times on the same lock. Note that for other threads to be able to require this lock, the owner of the lock must call
unlockas many times as the owner calledlock.