Overview
This topic is aimed at developers and describes basic usage, configuration, and advanced features.
Hazelcast provides a Java Client and Embedded Server which you can use to connect to a Hazelcast cluster. hazelcast-<VERSION>.jar is bundled in the Hazelcast standard package, so you simply add this file to your classpath to begin using the client as if you are using the Hazelcast API.
Get started
To get started using the Java Client and Embedded Server, you need to include the hazelcast.jar dependency in your classpath. You can then start using this client as if you are using the Hazelcast API.
If you have a Hazelcast Enterprise Edition license, you don’t need to set the license key in your Hazelcast Java clients to use the Enterprise Edition features. You only have to set it on the member side, and include the hazelcast-enterprise-<VERSION>.jar dependency in your classpath.
|
If you prefer to use Maven, make sure you have added the appropriate hazelcast or hazelcast-enterprise dependency to your pom.xml:
<repositories>
<repository>
<id>private-repository</id>
<name>Hazelcast Private Repository</name>
<url>https://repository.hazelcast.com/release/</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast-enterprise</artifactId>
<version>5.5.10</version>
</dependency>
</dependencies><dependencies>
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast</artifactId>
<version>5.5.0</version>
</dependency>
</dependencies>You can find Java Client and Embedded Server code samples in the Hazelcast Code Samples repository.
| For a tutorial on getting started with Java in an embedded topology, see Start a Local Embedded Cluster. |
API documentation
See the appropriate Javadoc API documentation for your Hazelcast edition (also available within your IDE):
-
Enterprise Edition: https://docs.hazelcast.org/hazelcast-ee-docs/5.5.10/javadoc
-
Community Edition: https://docs.hazelcast.org/docs/5.5.0/javadoc
Client API
The Client API is your gateway to access your Hazelcast cluster, including distributed objects and data pipelines (jobs).
First, you must configure your client. You can use either declarative or programmatic configuration to do this.
The following examples demonstrate the programmatic approach.
ClientConfig clientConfig = new ClientConfig();
clientConfig.setClusterName("dev");
clientConfig.getNetworkConfig().addAddress("10.90.0.1", "10.90.0.2:5702");For further information on client configuration, see Configure the client.
After completing the client configuration, you must create an HazelcastClient instance that will initialize and connect to the client based on the specified configuration:
HazelcastInstance client = HazelcastClient.newHazelcastClient(clientConfig);You can create a distributed map and populate it with some data as follows:
IMap<String, Customer> mapCustomers = client.getMap("customers"); //creates the map proxy
mapCustomers.put("1", new Customer("Joe", "Smith"));
mapCustomers.put("2", new Customer("Ali", "Selam"));
mapCustomers.put("3", new Customer("Avi", "Noyan"));For further information about using maps, see Distributed Map.
Lastly, after setting up your client, you can shut it down as follows:
client.shutdown();This command releases all used resources and closes all connections to the cluster.
Distributed data structures
Supported data structures
Hazelcast offers distributed implementations of many common data structures, most of which are supported by the Java Client and Embedded Server.
When you use clients in other languages, you should review the appropriate client documentation for exceptions and details. As a general rule, you should configure these data structures on the server side and access them through a proxy on the client side.
Use Map
You can use any distributed map object with the client, as follows:
Imap<Integer, String> map = client.getMap("myMap");
map.put(1, "John");
String value= map.get(1);
map.remove(1);The addLocalEntryListener() and localKeySet() methods are not supported because locality is ambiguous for the client. For more information, see Distributed Map.
Use MultiMap
You can use a distributed multiMap object with the Java Client and Embedded Server, as follows:
MultiMap<Integer, String> multiMap = client.getMultiMap("myMultiMap");
multiMap.put(1,"John");
multiMap.put(1,"Mary");
Collection<String> values = multiMap.get(1);The addLocalEntryListener(), localKeySet() and getLocalMultiMapStats() methods are not
supported because locality is ambiguous for the client. For more information, see MultiMap.
Use Queue
You can use a distributed Queue object with the client, as follows:
IQueue<String> myQueue = client.getQueue("theQueue");
myQueue.offer("John")The getLocalQueueStats() method is not supported because locality is ambiguous for the client.
For more information, see Queue.
Use Topic
The getLocalTopicStats() method is not supported because locality is ambiguous for the client.
Configure the client
Client cluster routing modes
The cluster routing mode specifies how the client connects to the cluster. It can currently be used only with Java and .NET clients.
| In previous releases, this functionality was known as the client operation mode and could be configured as smart or unisocket. If the cluster routing mode is not configured in your client, the configured client operation mode is used. |
The mode that you use depends on your network requirements due to the distributed nature of the data and cluster.
In all modes, the following information is provided to the client on initial connection:
-
Cluster version
-
Member details, including instance name, IP or UUID, partition group information, CP membership status, and type (Enterprise Edition only)
-
Partition group information (Enterprise Edition only)
-
CP group leader information (Enterprise Edition with
Advanced CPenabled only)
The client is updated whenever the cluster version, cluster topology, partition groups, or CP group leader changes.
From Enterprise Edition 5.5, you can use any of the following cluster routing modes:
-
ALL_MEMBERS
The default mode, and is the equivalent of the legacy Smart client operation mode.
In
ALL_MEMBERScluster routing mode, clients connect to each cluster member.Since clients are aware of data partitions, they are able to send an operation directly to the cluster member that owns the partition holding their data, which increases the overall throughput and efficiency.
If CP direct-to-leader routing is enabled on your clients, and the
ADVANCED_CPlicense is present on your Enterprise cluster, then clients in this routing mode can use this to send CP operations directly to group leaders wherever possible, even after leadership changes. -
SINGLE_MEMBER
In
SINGLE_MEMBERcluster routing mode, clients only connect to one of the configured addresses. This is the equivalent of the legacy Unisocket client operation mode.In some environments, clients must connect to only a single member instead of to each member in the cluster; for example, this can be enforced due to firewalls, security, or a custom network consideration. In these environments,
SINGLE_MEMBERmode allows to you connect to a single member, while retaining the ability to work with other members in the cluster.The single connected member behaves as a gateway to the other members of the cluster. When the client makes a request, the connected member redirects the request to the relevant member and returns the response from that member to the client.
-
MULTI_MEMBER
This mode provides most of the functionality of
ALL_MEMBERSrouting over a single partition group, falling back to the more restricted behavior ofSINGLE_MEMBERmode for members outside that partition group as follows:-
The client can connect to all members in the defined partition group
-
Outside the visible partition group, a member in the defined partition group acts as a gateway to the other members in the cluster
In
MULTI_MEMBERcluster routing mode, the client connection flow is as follows:-
Connect to the first member The client then has visibility of the partition group associated with the first member.
-
Read the partition group information
-
Connect to a limited subset of the cluster as defined by the partition grouping The client does not have a connection to any cluster members outside this partition group, but it will have knowledge of all cluster members
-
The following diagram shows how each mode connects to members in a cluster:
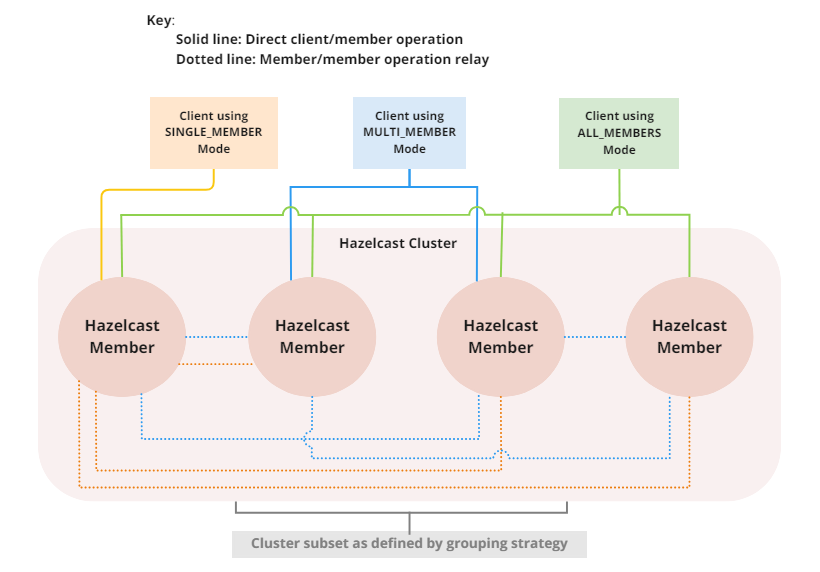
For information on configuring the cluster routing mode, see Configure Cluster Routing Mode.
If already using the legacy Smart and Unisocket client operation modes, these remain supported. However, we recommend that you update your configuration to use the appropriate cluster routing mode as these options will be removed in a future major version. For information on these modes and their configuration, select 5.4 from the version picker at the top of the navigation pane. Ensure that the cluster routing mode is not configured at the same time as the legacy client operation mode, only one should be defined.
Handling failures
The main areas are around client connections and retry-able operations. Some approaches to avoiding such failures are provided below.
Client connection failure
While the client initially tries to connect to one of the members in the ClientNetworkConfig.addressList, it’s possible that not all members are available.
Instead of giving up, throwing an exception and stopping, the client continues to attempt to connect as configured.
For information on the available configuration, see Configure client connection retry.
The client executes each operation through the already established connection to the cluster. If this connection disconnects or drops, the client tries to reconnect as configured.
If using the MULTI_MEMBER cluster routing mode, and the cluster has multiple partition groups defined
and the client connection to a partition group fails, connectivity is maintained by failing over to an alternative partition group.
If the connection is lost, which occurs only if all members of the partition group become unavailable, there is no attempt to retry the connection before failing over to another partition group.
For more information on client cluster routing modes, see Client cluster routing modes.
Retry-able operations failure
While sending the requests to related members, operations can fail due to various reasons.
Read-only operations are retried by default. If you want to enable retry for the other operations,
you can set the redoOperation to true. For more info, see Enable redo operation.
You can set a timeout for retrying the operations sent to a member.
This can be provided by using the hazelcast.client.invocation.timeout.seconds property in ClientProperties.
The client retries an operation within this given period, if it is a read-only operation, or if
you enabled the redoOperation as described above.
This timeout value is important when there is a failure caused by any of the following:
-
Member throws an exception
-
Connection between the client and member is closed
-
Client’s heartbeat requests time out
See Client system Properties for a description of the hazelcast.client.invocation.timeout.seconds property.
When any failure happens between a client and member (such as an exception on the member side or connection issues), an operation is retried if:
-
it is certain that it has not run on the member yet
-
it is idempotent such as a read-only operation, i.e. retrying does not have a side effect.
If it is not certain whether the operation has run on the member, then the non-idempotent operations are not retried.
However, as explained earlier, you can force all client operations to be retried (redoOperation) when there is a failure between the client and member.
But in this case, some operations may run multiple times and therefore cause conflicts.
For example, assume that your client sent a queue.offer operation to the member and then the connection is lost. Because there is no respond for this operation, you won’t know whether it has run on the member or not. If you enabled redoOperation, that specific queue.offer operation may rerun and this will cause the same objects to be offered twice in the member’s queue.
Configure client listeners
You can configure global event listeners using ListenerConfig as the following examples show:
ClientConfig clientConfig = new ClientConfig();
ListenerConfig listenerConfig = new ListenerConfig(LifecycleListenerImpl);
clientConfig.addListenerConfig(listenerConfig);ClientConfig clientConfig = new ClientConfig();
ListenerConfig listenerConfig = new ListenerConfig("com.hazelcast.example.MembershipListenerImpl");
clientConfig.addListenerConfig(listenerConfig);You can add the following types of event listeners:
-
LifecycleListener` -
MembershipListener` -
DistributedObjectListener`
Configure client near cache
To increase the performance of local read operations, the distributed map supports a local near cache for remotely stored entries. Because the client always requests data from the cluster members, it can be helpful in some use cases to configure a near cache on the client side. For a detailed explanation of this feature and its configuration, see Near cache.
Configure client cluster name
Clients should provide a cluster name in order to connect to the cluster.
You can configure it using ClientConfig, as the following example shows:
clientConfig.setClusterName("dev");Configure client security
Hazelcast Enterprise Edition
You can define control mechanisms for clients to control authentication and authorisation. For more information, see Client Authorization.
You can provide the Java client with an identity for cluster authentication. The identity of the connecting client is defined on the client side. Usually, there are no security realms on the clients; only the identity defined in the security configuration.
<hazelcast-client>
...
<security>
<username-password username="uid=member1,dc=example,dc=com" password="s3crEt"/>
</security>
...
</hazelcast-client>hazelcast-client:
security:
username-password:
username: uid=member1,dc=example,dc=com
password: s3crEtOn the clients, you can use the same identity types as in the security realms:
-
username-password -
token -
kerberos(may require an additional security realm definition) -
credentials-factory
Security realms on the client side
Hazelcast offers limited support for security realms in the Java client. You can configure the client to use JAAS login modules that can be referenced from the Kerberos identity configuration.
<security>
<kerberos>
<realm>ACME.COM</realm>
<security-realm>krb5Initiator</security-realm>
</kerberos>
<realms>
<realm name="krb5Initiator">
<authentication>
<jaas>
<login-module class-name="com.sun.security.auth.module.Krb5LoginModule" usage="REQUIRED">
<properties>
<property name="useTicketCache">true</property>
<property name="doNotPrompt">true</property>
</properties>
</login-module>
</jaas>
</authentication>
</realm>
</realms>
</security>security:
kerberos:
realm: ACME.COM
security-realm: krb5Initiator
realms:
name: krb5Initiator
authentication:
jaas:
class-name: com.sun.security.auth.module.Krb5LoginModule
usage: REQUIRED
properties:
useTicketCache: true
doNotPrompt: trueFor more information, see ClientSecurityConfig API documentation
Configure ClassLoader
You can configure a custom classLoader for your client.
It is used by the serialization service and loads any class specified in the configuration, including event listeners or ProxyFactories.
Configure CP direct-to-leader operation routing for clients
When operating a Hazelcast Enterprise cluster with the ADVANCED_CP license it is possible to configure clients to
leverage direct-to-leader routing for CP Subsystem operations. When enabled,
this functionality enables clients to receive a mapping of CP group leadership from the cluster and use it to send
CP data structure operations directly to the relevant group leader. This leadership mapping is also updated whenever
leadership changes occur.
CP data structure reads and writes must be actioned by the CP leader responsible for the group involved. By leveraging direct-to-leader routing for CP operations, clients are able to send all operations directly to their group leaders, cutting out the need for intermediate hops through other cluster members. This allows clients to achieve lower latency and higher throughput for their CP operations, while also reducing the pressure on the internal cluster network, resulting in greater cluster stability.
This functionality is disabled by default and must be explicitly enabled. This is done because you should consider your specific use-case for CP operation sending and assess the impact of direct to leader routing on your topology. In scenarios where clients have increased latency to CP group leaders, it may be detrimental to route all operations directly to them instead of using a faster internal cluster link and routing through another member. You should also consider that direct-to-leader routing can put uneven pressure on the cluster if CP group leaders receive a substantially greater load than other members of the cluster, which is particularly problematic when only one CP group leader is present.
If a client does not have an active connection to a known CP group leader then the client will be unable to leverage
direct-to-leader CP operations and will fall back to default round-robin behaviour, sending the request to any available
cluster member instead. This feature provides no benefit when SINGLE_MEMBER routing is used as the client only has 1
available connection to use for all operation sending.
|
You can enable CP direct-to-leader routing with a single configuration option, as the following example shows:
ClientConfig clientConfig = new ClientConfig();
clientConfig.setCPDirectToLeaderRoutingEnabled(true);The following code shows the equivalent declarative configuration:
Java client connection strategy
You can configure the client’s starting mode as async or sync using
the configuration element async-start. When it is set to true (async),
Hazelcast creates the client without waiting for a connection to the cluster.
In this case, the client instance throws an exception until it connects to the cluster.
If it is false, the client is not created until the cluster is ready to use clients and
a connection with each of the cluster members (defined by the routing mode) is established.
The default value is false (sync).
You can also configure how the client reconnects to the cluster after a disconnection.
This is configured using the configuration element reconnect-mode, which has three options:
-
OFF: disables the reconnection -
ON: enables reconnection in a blocking manner, where all waiting invocations are blocked until a cluster connection is established or fails -
ASYNC: enables reconnection in a non-blocking manner, where all waiting invocations receive aHazelcastClientOfflineException.
The default value for reconnect-mode is ON.
When you have ASYNC as the reconnect-mode and have defined a near cache for your client, the client functions without interruptions/downtime by communicating the data from its near cache,
provided that there is non-expired data in it. To learn how to add a near cache to your client, see Configure client near cache.
|
The following declarative and programmatic configuration examples show how to configure a Java client’s starting and reconnecting modes:
Configure with CNAME
Using CNAME, you can change the hostname resolutions and use them dynamically.
As an example, assume that you have two clusters, Cluster A and Cluster B, and two Java clients.
First, configure the Cluster A members as shown below:
<hazelcast>
...
<network>
<join>
<tcp-ip enabled="true">
<member>clusterA.member1</member>
<member>clusterA.member2</member>
</tcp-ip>
</join>
</network>
...
</hazelcast>hazelcast:
network:
join:
tcp-ip:
enabled: true
members: clusterA.member1,clusterA.member2Next, configure the Cluster B members as shown below:
<hazelcast>
...
<network>
<join>
<tcp-ip enabled="true">
<member>clusterB.member1</member>
<member>clusterB.member2</member>
</tcp-ip>
</join>
</network>
...
</hazelcast>hazelcast:
network:
join:
tcp-ip:
enabled: true
members: clusterB.member1,clusterB.member2Now, configure the two clients as shown below:
<hazelcast-client>
...
<cluster-name>cluster-a</cluster-name>
<network>
<cluster-members>
<address>production1.myproject</address>
<address>production2.myproject</address>
</cluster-members>
</network>
...
</hazelcast-client>hazelcast-client:
cluster-name: cluster-a
network:
cluster-members:
- production1.myproject
- production2.myproject<hazelcast-client>
...
<cluster-name>cluster-b</cluster-name>
<network>
<cluster-members>
<address>production1.myproject</address>
<address>production2.myproject</address>
</cluster-members>
</network>
...
</hazelcast-client>hazelcast-client:
cluster-name: cluster-b
network:
cluster-members:
- production1.myproject
- production2.myprojectAssuming that the client configuration filenames for the above example clients are
hazelcast-client-c1.xml/yaml and hazelcast-client-c2.xml/yaml, you should configure the
client failover for a blue-green deployment scenario as follows:
<hazelcast-client-failover>
<try-count>4</try-count>
<clients>
<client>hazelcast-client-c1.xml</client>
<client>hazelcast-client-c2.xml</client>
</clients>
</hazelcast-client-failover>hazelcast-client-failover:
try-count: 4
clients:
- hazelcast-client-c1.yaml
- hazelcast-client-c2.yaml
You can find the complete Hazelcast client failover
example configuration file (hazelcast-client-failover-full-example)
both in XML and YAML formats including the descriptions of elements and attributes,
in the /bin directory of your Hazelcast download directory.
|
You should also configure your clients to forget DNS lookups using the networkaddress.cache.ttl JVM parameter.
You should also configure the addresses in your clients' configuration to resolve to the hostnames of Cluster A via CNAME so that the clients will connect to Cluster A when it starts:
production1.myproject → clusterA.member1
production2.myproject → clusterA.member2
When you want the clients to switch to the other cluster, change the mapping as follows:
production1.myproject → clusterB.member1
production2.myproject → clusterB.member2
Wait for the time you configured using the networkaddress.cache.ttl JVM parameter for
the client JVM to forget the old mapping.
Finally, blocklist the clients in Cluster A using Hazelcast Management Center.
Configure without CNAME
Review these example configurations and the descriptions that follow:
Programmatic configuration
ClientConfig clientConfig = new ClientConfig();
clientConfig.setClusterName("cluster-a");
ClientNetworkConfig networkConfig = clientConfig.getNetworkConfig();
networkConfig.addAddress("10.216.1.18", "10.216.1.19");
ClientConfig clientConfig2 = new ClientConfig();
clientConfig2.setClusterName("cluster-b");
ClientNetworkConfig networkConfig2 = clientConfig2.getNetworkConfig();
networkConfig2.addAddress( "10.214.2.10", "10.214.2.11");
ClientFailoverConfig clientFailoverConfig = new ClientFailoverConfig();
clientFailoverConfig.addClientConfig(clientConfig).addClientConfig(clientConfig2).setTryCount(10)
HazelcastInstance client = HazelcastClient.newHazelcastFailoverClient(clientFailoverConfig);For more information on the configuration elements, see the following descriptions:
-
try-count: count of connection retries by the client to the alternative clusters.
When this value is reached, the client shuts down if it can’t connect to a cluster. This value also applies to alternative clusters configured by the client element. For the above example, two alternative clusters are given
with the try-count set as 4. This means the number of connection attempts is 4 x 2 = 8.
-
client: path to the client configuration that corresponds to an alternative cluster that the client will try to connect to.
The client configurations must be exactly the same except for the following configuration options:
-
SecurityConfig -
NetworkConfig.Addresses -
NetworkConfig.SocketInterceptorConfig -
NetworkConfig.SSLConfig -
NetworkConfig.AwsConfig -
NetworkConfig.GcpConfig -
NetworkConfig.AzureConfig -
NetworkConfig.KubernetesConfig -
NetworkConfig.EurekaConfig -
NetworkConfig.CloudConfig -
NetworkConfig.DiscoveryConfig
You can also configure it within the Spring context, as shown below:
<beans>
<hz:client-failover id="blueGreenClient" try-count="5">
<hz:client>
<hz:cluster-name name="dev"/>
<hz:network>
<hz:member>127.0.0.1:5700</hz:member>
<hz:member>127.0.0.1:5701</hz:member>
</hz:network>
</hz:client>
<hz:client>
<hz:cluster-name name="alternativeClusterName"/>
<hz:network>
<hz:member>127.0.0.1:5702</hz:member>
<hz:member>127.0.0.1:5703</hz:member>
</hz:network>
</hz:client>
</hz:client-failover>
</beans>Configure client network
Configuration options
You can manage all network-related configuration setting using either the network element (declarative) or the ClientNetworkConfig class (programmatic).
This section provides full examples for these two approaches, and then looks at the sub-elements and attributes in detail.
Declarative configuration
The following declarative network configuration examples include all the public configuration APIs/methods:
<hazelcast-client>
...
<network>
<cluster-members>
<address>127.0.0.1</address>
<address>127.0.0.2</address>
</cluster-members>
<outbound-ports>
<ports>34600</ports>
<ports>34700-34710</ports>
</outbound-ports>
<cluster-routing mode="ALL_MEMBERS"/>
<redo-operation>true</redo-operation>
<connection-timeout>60000</connection-timeout>
<socket-options>
...
</socket-options>
<socket-interceptor enabled="true">
...
</socket-interceptor>
<ssl enabled="false">
...
</ssl>
<aws enabled="true" connection-timeout-seconds="11">
...
</aws>
<gcp enabled="false">
...
</gcp>
<azure enabled="false">
...
</azure>
<kubernetes enabled="false">
...
</kubernetes>
<eureka enabled="false">
...
</eureka>
<icmp-ping enabled="false">
...
</icmp-ping>
<hazelcast-cloud enabled="false">
<discovery-token>EXAMPLE_TOKEN</discovery-token>
</hazelcast-cloud>
<discovery-strategies>
<node-filter class="DummyFilterClass" />
<discovery-strategy class="DummyDiscoveryStrategy1" enabled="true">
<properties>
<property name="key-string">foo</property>
<property name="key-int">123</property>
<property name="key-boolean">true</property>
</properties>
</discovery-strategy>
</discovery-strategies>
</network>
...
</hazelcast-client>hazelcast-client:
network:
cluster-members:
- 127.0.0.1
- 127.0.0.2
outbound-ports:
- 34600
- 34700-34710
cluster-routing:
mode: ALL_MEMBERS
redo-operation: true
connection-timeout: 60000
socket-options:
...
socket-interceptor:
...
ssl:
enabled: false
...
aws:
enabled: true
connection-timeout-seconds: 11
...
gcp:
enabled: false
...
azure:
enabled: false
...
kubernetes:
enabled: false
...
eureka:
enabled: false
...
icmp-ping:
enabled: false
...
hazelcast-cloud:
enabled: false
discovery-token: EXAMPLE_TOKEN
discovery-strategies:
node-filter:
class: DummyFilterClass
discovery-strategies:
- class: DummyDiscoveryStrategy1
enabled: true
properties:
key-string: foo
key-int: 123
key-boolean: trueProgrammatic configuration
The following example programmatic network configuration includes all the parent configuration attributes:
ClientConfig clientConfig = new ClientConfig();
clientConfig.getConnectionStrategyConfig().getConnectionRetryConfig().setMaxBackoffMillis(5000);
ClientNetworkConfig networkConfig = clientConfig.getNetworkConfig();
networkConfig.addAddress("10.1.1.21", "10.1.1.22:5703")
.setClusterRoutingConfig(new ClusterRoutingConfig().setRoutingMode(RoutingMode.ALL_MEMBERS))
.addOutboundPortDefinition("34700-34710")
.setRedoOperation(true)
.setConnectionTimeout(5000);
AwsConfig clientAwsConfig = new AwsConfig();
clientAwsConfig.setProperty("access-key", "my-access-key")
.setProperty("secret-key", "my-secret-key")
.setProperty("region", "us-west-1")
.setProperty("host-header", "ec2.amazonaws.com")
.setProperty("security-group-name", ">hazelcast-sg")
.setProperty("tag-key", "type")
.setProperty("tag-value", "hz-members")
.setProperty("iam-role", "s3access")
.setEnabled(true);
clientConfig.getNetworkConfig().setAwsConfig(clientAwsConfig);
HazelcastInstance client = HazelcastClient.newHazelcastClient(clientConfig);The following sections include details and usage examples for sub-elements and attributes.
Configure backup acknowledgment
When an operation with sync backup is sent by a client to the Hazelcast member(s), the acknowledgment of the operation’s backup is sent to the client by the backup replica member(s). This improves the performance of the client operations.
| Backup acknowledgement is sometimes referred to as boomerang backups. |
If using the ALL_MEMBERS cluster routing mode, backup acknowledgement to the client is enabled by default.
However, neither the MULTI_MEMBER nor the SINGLE_MEMBER cluster routing modes support backup acknowledgement to the client.
The following declarative example shows how to configure backup acknowledgement:
<hazelcast-client ... >
<backup-ack-to-client-enabled>false</backup-ack-to-client-enabled>
</hazelcast-client>hazelcast-client:
backup-ack-to-client: falseThe following programmatic example shows how to configure backup acknowledgement:
clientConfig.setBackupAckToClientEnabled(boolean enabled)You can also fine tune this feature using the following system properties:
-
hazelcast.client.operation.backup.timeout.millis: if an operation has sync backups, this property specifies how long (in milliseconds) the invocation waits for acks from the backup replicas. If acks are not received from some of the backups, there will not be any rollback on the other successful replicas. The default value is5000milliseconds. -
hazelcast.client.operation.fail.on.indeterminate.state: whentrue, if an operation has sync backups and acks are not received from backup replicas in time, or the member which owns the primary replica of the target partition leaves the cluster, then the invocation fails. However, even if the invocation fails, there will not be any rollback on other successful replicas. The default value isfalse.
Configure address list
The address List is the initial list of cluster addresses to which the client will connect. The client uses this list to find an alive member. Although it may be enough to give only one address of a member in the cluster (since all members communicate with each other), we recommended that you add the addresses for all the members.
Programmatic configuration
ClientConfig clientConfig = new ClientConfig();
ClientNetworkConfig networkConfig = clientConfig.getNetworkConfig();
networkConfig.addAddress("10.1.1.21", "10.1.1.22:5703");You can add addresses with or without the port number. If the port is omitted, then the default ports (5701, 5702, 5703) are tried in random order.
The address list is tried in random order. The default value is localhost.
If you have multiple members on a single machine and you are using the
SINGLE_MEMBER cluster routing mode, we recommend that you set explicit
ports for each member. Then you should provide those ports in your client configuration
when you give the member addresses (using the address configuration element or
addAddress method as exemplified above). This provides faster connections between clients and members. Otherwise,
all the load coming from your clients may go through a single member.
|
Set outbound ports
You may want to restrict outbound ports to be used by Hazelcast-enabled applications. To fulfill this requirement, you can configure Hazelcast Java client to use only defined outbound ports. The following are example configurations.
Declarative configuration:
<hazelcast-client>
...
<network>
<outbound-ports>
<!-- ports between 34700 and 34710 -->
<ports>34700-34710</ports>
<!-- comma separated ports -->
<ports>34700,34701,34702,34703</ports>
<ports>34700,34705-34710</ports>
</outbound-ports>
</network>
...
</hazelcast-client>hazelcast-client:
network:
outbound-ports:
- 34700-34710
- 34700,34701,34702,34703
- 34700,34705-34710Programmatic configuration:
...
NetworkConfig networkConfig = config.getNetworkConfig();
// ports between 34700 and 34710
networkConfig.addOutboundPortDefinition("34700-34710");
// comma separated ports
networkConfig.addOutboundPortDefinition("34700,34701,34702,34703");
networkConfig.addOutboundPort(34705);
...| You can use port ranges and/or comma separated ports. |
As shown in the programmatic configuration, you use the method addOutboundPort to
add only one port. If you need to add a group of ports, then use the method addOutboundPortDefinition.
In the declarative configuration, the element ports can be used for
both single and multiple port definitions.
Configure cluster routing mode
You can configure the cluster routing mode to suit your requirements, as described in Client Cluster Routing Modes.
The following examples show the configuration for each cluster routing mode.
| If your clients want to use temporary permissions defined in a member, see Handling Permissions. |
Client ALL_MEMBERS routing
To connect to all members, use the ALL_MEMBERS cluster routing mode, which can be defined as follows.
Declarative configuration:
<hazelcast-client>
...
<network>
<cluster-routing mode="ALL_MEMBERS"/>
</network>
...
</hazelcast-client>Declarative configuration:
hazelcast-client:
network:
cluster-routing:
mode: ALL_MEMBERSProgrammatic configuration:
ClientConfig clientConfig = new ClientConfig();
ClientNetworkConfig networkConfig = clientConfig.getNetworkConfig();
networkConfig.getClusterRoutingConfig().setRoutingMode(RoutingMode.ALL_MEMBERS);Client SINGLE_MEMBER routing
To connect to a single member, which can be used as a gateway to the other members, use the SINGLE_MEMBER cluster routing mode, which can be defined as described below.
When using the SINGLE_MEMBER cluster routing mode, consider the following:
-
The absence of backup acknowledgements, as the client does not have a view of the entire cluster
-
If you have multiple members on a single machine, we advise that explicit ports are set for each member
-
If CP group leader priority is assigned appropriately, and the client is explicitly set to connect to a CP group leader, connections to the CP Subsystem are direct-to-leader, which can result in improved performance. If leadership is reassigned while using
SINGLE_MEMBERcluster routing, then this benefit may be lost. -
LoadBalancerconfiguration is ignored -
Thread-Per-Core is not supported for
SINGLE_MEMBERcluster routing and no benefit will be gained by enabling it with this routing mode.
Declarative configuration:
<hazelcast-client>
...
<network>
<cluster-routing mode="SINGLE_MEMBER"/>
</network>
...
</hazelcast-client>Declarative configuration:
hazelcast-client:
network:
cluster-routing:
mode: SINGLE_MEMBERProgrammatic configuration:
ClientConfig clientConfig = new ClientConfig();
ClientNetworkConfig networkConfig = clientConfig.getNetworkConfig();
networkConfig.getClusterRoutingConfig().setRoutingMode(RoutingMode.SINGLE_MEMBER);Client MULTI_MEMBER routing
To connect to a subset partition grouping of members, which allows direct connection to the specified group and gateway connections to other members, use the MULTI_MEMBER cluster routing mode, which can be defined as follows.
To use the MULTI_MEMBER cluster routing mode, you must also define the grouping strategy to apply. For further information on configuring partition groups, see Partition Group Configuration.
When using the MULTI_MEMBER cluster routing mode, consider the following:
-
The handling of connection failures, which failover to another partition group where one is available. No retry attempt is made to connect to the lost member(s)
In a split and heal scenario, where the client has no access to other group members, the client is re-assigned to the initial group.
In a scenario where all group members are killed almost simultaneously, the client loses connection but reconnects when a member starts again.
-
The absence of backup acknowledgements, as the client does not have a view of the entire cluster If CP direct-to-leader routing is enabled on your clients, and the
ADVANCED_CPlicense is present on your Enterprise cluster, then clients in this routing mode can use this to send CP operations directly to group leaders wherever possible, even after leadership changes. -
Best efforts are made to route operations to the required member, but if this cannot be done operations are routed as defined in the
LoadBalancer -
Thread-Per-Core is not supported for
MULTI_MEMBERcluster routing and may lead to event inconsistency if used.
Declarative configuration:
<hazelcast-client>
...
<network>
<cluster-routing mode="MULTI_MEMBER">
<grouping-strategy>PARTITION_GROUPS</grouping-strategy>
</cluster-routing>
</network>
...
</hazelcast-client>Declarative configuration:
hazelcast-client:
network:
cluster-routing:
mode: MULTI_MEMBER
grouping-strategy: PARTITION_GROUPSProgrammatic configuration:
ClientConfig clientConfig = new ClientConfig();
ClientNetworkConfig networkConfig = clientConfig.getNetworkConfig();
networkConfig.getClusterRoutingConfig().setRoutingMode(RoutingMode.MULTI_MEMBER);
// PARTITION_GROUPS is the default strategy, so it does not need to be explicitly defined
networkConfig.getClusterRoutingConfig().setRoutingStrategy(RoutingStrategy.PARTITION_GROUPS);
If you are using the smart or unisocket client operation modes, select 5.4 from the version picker above the navigation pane to see the configuration information. The cluster routing mode described above must not be present in your configuration.
|
Enable redo operations
It enables/disables redo-able operations as described in Handling Retry-able Operation Failure. The following are the example configurations.
Declarative Configuration:
<hazelcast-client>
...
<network>
<redo-operation>true</redo-operation>
</network>
...
</hazelcast-client>hazelcast-client:
network:
redo-operation: trueProgrammatic Configuration:
ClientConfig clientConfig = new ClientConfig();
ClientNetworkConfig networkConfig = clientConfig.getNetworkConfig();
networkConfig().setRedoOperation(true);Its default value is false (disabled).
Set connection timeout
Connection timeout is the timeout value in milliseconds for members to accept client connection requests.
The following code shows a declarative example configuration:
<hazelcast-client>
...
<network>
<connection-timeout>5000</connection-timeout>
</network>
...
</hazelcast-client>hazelcast-client:
network:
connection-timeout: 5000The following code shows a programmatic example configuration:
ClientConfig clientConfig = new ClientConfig();
clientConfig.getNetworkConfig().setConnectionTimeout(5000);The default value is 5000 milliseconds.
Set a socket interceptor
Hazelcast Enterprise Edition
Any class implementing com.hazelcast.nio.SocketInterceptor is a socket interceptor.
The following code sample shows an example of how to set a socket interceptor:
public interface SocketInterceptor {
void init(Properties properties);
void onConnect(Socket connectedSocket) throws IOException;
}The first method initializes the SocketInterceptor using the defined properties.
The second method informs when the socket is connected using the onConnect method.
The following example shows how to create a SocketInterceptor and add it to the client configuration:
SocketInterceptorConfig socketInterceptorConfig = clientConfig
.getNetworkConfig().getSocketInterceptorConfig();
MyClientSocketInterceptor myClientSocketInterceptor = new MyClientSocketInterceptor();
socketInterceptorConfig.setEnabled(true);
socketInterceptorConfig.setImplementation(myClientSocketInterceptor);If you want to configure the socket interceptor with a class name instead of an instance, see the example below:
SocketInterceptorConfig socketInterceptorConfig = clientConfig
.getNetworkConfig().getSocketInterceptorConfig();
socketInterceptorConfig.setEnabled(true);
//These properties are provided to the interceptor during init
socketInterceptorConfig.setProperty("kerberos-host","kerb-host-name");
socketInterceptorConfig.setProperty("kerberos-config-file","kerb.conf");
socketInterceptorConfig.setClassName(MyClientSocketInterceptor.class.getName());| For more information, see Socket interceptor. |
Configure network socket options
You can configure the network socket options using SocketOptions. It has the following methods:
-
socketOptions.setKeepAlive(x): Enables/disables the SO_KEEPALIVE socket option. The default value istrue. -
socketOptions.setTcpNoDelay(x): Enables/disables the TCP_NODELAY socket option. The default value istrue. -
socketOptions.setReuseAddress(x): Enables/disables the SO_REUSEADDR socket option. The default value istrue. -
socketOptions.setLingerSeconds(x): Enables/disables SO_LINGER with the specified linger time in seconds. The default value is3. -
socketOptions.setBufferSize(x): Sets the SO_SNDBUF and SO_RCVBUF options to the specified value in KB for this Socket. The default value is32.
SocketOptions socketOptions = clientConfig.getNetworkConfig().getSocketOptions();
socketOptions.setBufferSize(32)
.setKeepAlive(true)
.setTcpNoDelay(true)
.setReuseAddress(true)
.setLingerSeconds(3);Enable client TLS
Hazelcast Enterprise Edition
You can use TLS to secure the connection between the client and the members.
If you want TLS enabled for the client-cluster connection, you should set SSLConfig.
For more information, see TLS.
SSL (Secure Sockets Layer) is the predecessor protocol to TLS (Transport Layer Security).
Both protocols encrypt and secure data transmitted over networks but SSL is now considered outdated and has been replaced by TLS for improved security.
Hazelcast code still refers to ssl in places for backward compatibility but consider these references to also include TLS.
|
Keys and certificates in keyStores are used to prove identity to the other side of the connection, and trustStores are used to
specify trusted parties (from which the connection should be accepted).
Clients only need to have their keyStores specified when TLS Mutual Authentication is
required by members.
For a programmatic example, see this code example.
Configure Hazelcast Cloud
You can connect the Java Client and Embedded Server to a Cloud Standard cluster which is hosted on Cloud. For this, you need to enable Cloud and specify the cluster’s discovery token provided while creating the cluster; this allows the cluster to discover your clients. See the following example configurations:
Declarative configuration
<hazelcast-client>
...
<network>
<ssl enabled="true"/>
<hazelcast-cloud enabled="true">
<discovery-token>YOUR_TOKEN</discovery-token>
</hazelcast-cloud>
</network>
...
</hazelcast-client>hazelcast-client:
network:
ssl:
enabled: true
hazelcast-cloud:
enabled: true
discovery-token: YOUR_TOKENProgrammatic configuration
ClientConfig config = new ClientConfig();
ClientNetworkConfig networkConfig = config.getNetworkConfig();
networkConfig.getCloudConfig().setDiscoveryToken("TOKEN").setEnabled(true);
networkConfig.setSSLConfig(new SSLConfig().setEnabled(true));
HazelcastInstance client = HazelcastClient.newHazelcastClient(config);Cloud is disabled for the Java client, by default (enabled attribute is false).
See Hazelcast Cloud for more information about Cloud.
| Because this is a REST based discovery, you need to enable the REST listener service. See the REST Endpoint Groups section on how to enable REST endpoints. |
|
Deprecation Notice for the Community Edition REST API
The Community Edition REST API has been deprecated and will be removed as of Hazelcast version 7.0. An improved Enterprise version of this feature is available and actively being developed. For more information, see Enterprise REST API. |
|
For security reasons, we recommend you enable certificate revocation status JRE-wide.
You need to set the following Java system properties to
And you need to set the Java security property as follows:
You can find more details on the related security topics from the Oracle Docs on JSSE Ref Guide and Cert Path Prog Guide. |
Configure client for AWS
The example declarative and programmatic configurations below show how to configure a Java client for connecting to a Hazelcast cluster in AWS (Amazon Web Services).
Declarative Configuration
<hazelcast-client>
...
<network>
<aws enabled="true">
<use-public-ip>true</use-public-ip>
<access-key>my-access-key</access-key>
<secret-key>my-secret-key</secret-key>
<region>us-west-1</region>
<host-header>ec2.amazonaws.com</host-header>
<security-group-name>hazelcast-sg</security-group-name>
<tag-key>type</tag-key>
<tag-value>hz-members</tag-value>
</aws>
</network>
...
</hazelcast-client>hazelcast-client:
network:
aws:
enabled: true
use-public-ip: true
access-key: my-access-key
secret-key: my-secret-key
region: us-west-1
host-header: ec2.amazonaws.com
security-group-name: hazelcast-sg
tag-key: type
tag-value: hz-membersProgrammatic Configuration
ClientConfig clientConfig = new ClientConfig();
AwsConfig clientAwsConfig = new AwsConfig();
clientAwsConfig.setProperty("access-key", "my-access-key")
.setProperty("secret-key", "my-secret-key")
.setProperty("region", "us-west-1")
.setProperty("host-header", "ec2.amazonaws.com")
.setProperty("security-group-name", ">hazelcast-sg")
.setProperty("tag-key", "type")
.setProperty("tag-value", "hz-members")
.setProperty("iam-role", "s3access")
.setEnabled(true);
clientConfig.getNetworkConfig().setAwsConfig(clientAwsConfig);
HazelcastInstance client = HazelcastClient.newHazelcastClient(clientConfig);For more information on AWS configuration elements (except use-public-ip), see AWS Element section on network configuration.
If the use-public-ip element is set to true, the private addresses of cluster members
are always converted to public addresses. Also, the client uses public addresses to
connect to the members. In order to use private addresses, set the use-public-ip parameter to false.
When connecting outside from AWS, if you set the use-public-ip parameter to false then
the client will not be able to reach the members.
|
Use client services
Hazelcast provides the following client services.
Use distributed executor service
The distributed executor service is for distributed computing. It can be used to execute tasks on the cluster on a designated partition or on all the partitions. It can also be used to process entries. For more information, see Java Executor Service.
IExecutorService executorService = client.getExecutorService("default");After getting an instance of IExecutorService, you can use the instance as
the interface with the one provided on the server side. See
Distributed Computing for detailed usage.
Listen to client connections
If you need to track clients and want to listen to their connection events,
you can use the clientConnected() and clientDisconnected() methods of the ClientService class.
This class must be run on the member side. The following code shows an example of how to do this:
ClientConfig clientConfig = new ClientConfig();
//clientConfig.setClusterName("dev");
clientConfig.getNetworkConfig().addAddress("10.90.0.1", "10.90.0.2:5702");
HazelcastInstance instance = Hazelcast.newHazelcastInstance();
final ClientService clientService = instance.getClientService();
clientService.addClientListener(new ClientListener() {
@Override
public void clientConnected(Client client) {
//Handle client connected event
}
@Override
public void clientDisconnected(Client client) {
//Handle client disconnected event
}
});
//this will trigger `clientConnected` event
HazelcastInstance client = HazelcastClient.newHazelcastClient();
final Collection<Client> connectedClients = clientService.getConnectedClients();
//this will trigger `clientDisconnected` event
client.shutdown();Find the partition of a key
You use the partition service to find the partition of a key. It returns all partitions. See the example code below:
PartitionService partitionService = client.getPartitionService();
//partition of a key
Partition partition = partitionService.getPartition(key);
//all partitions
Set<Partition> partitions = partitionService.getPartitions();Handling Lifecycle
Lifecycle handling performs:
-
checking if the client is running
-
shutting down the client gracefully
-
terminating the client ungracefully (forced shutdown)
-
adding/removing lifecycle listeners.
LifecycleService lifecycleService = client.getLifecycleService();
if(lifecycleService.isRunning()){
//it is running
}
//shutdown client gracefully
lifecycleService.shutdown();Build data pipeline
To build a data pipeline:
Pipeline EvenNumberStream = Pipeline.create();
EvenNumberStream.readFrom(TestSources.itemStream(10))
.withoutTimestamps()
.filter(event -> event.sequence() % 2 == 0)
.setName("filter out odd numbers")
.writeTo(Sinks.logger());
client.getJet().newJob(EvenNumberStream);For details about data pipelines, see About Data Pipelines.
Define client labels
You can define labels in your Java client, similar to the way labels are used for members. With client labels you can assign special roles for your clients and use these roles to perform actions specific to those client connections. For more information on labels, see Cluster Utilities.
You can also group your clients using labels. You can use Hazelcast Management Center to blocklist these client groups to prevent them connecting to a cluster. For more information, see Manage client connections.
The following declarative example shows how to define client using the client-labels
configuration element:
<hazelcast-client>
...
<instance-name>barClient</instance-name>
<client-labels>
<label>user</label>
<label>bar</label>
</client-labels>
....
</hazelcast-client>hazelcast-client:
instance-name: barClient
client-labels:
- user
- barThe following programmatic example shows how to define client using the client-labels
configuration element:
ClientConfig clientConfig = new ClientConfig();
clientConfig.setInstanceName("ExampleClientName");
clientConfig.addLabel("user");
clientConfig.addLabel("bar");
HazelcastClient.newHazelcastClient(clientConfig);For an working code sample using client labels, see the Client labels code sample.
Query with SQL
To query a map using SQL:
String query =
"SELECT * FROM customers csv_likes";
try (SqlResult result = client.getSql().execute(query)) {
for (SqlRow row : result) {
System.out.println("" + row.getObject(0));
}
}For details about querying with SQL, see SQL.
Client system properties
There are some advanced client configuration properties that help you tune the Java Client and Embedded Server. You can set them as property name and value pairs through either declarative or programmatic configuration, or with a JVM system property. For more information on system properties in general, including how to set them, see System Properties.
| You need to restart clients after modifying system properties. |
| Property Name | Default Value | Type | Description |
|---|---|---|---|
|
long |
Token to use when discovering the cluster via Cloud. |
|
|
100 |
int |
Property needed for concurrency detection so that write through and dynamic response handling can be done correctly. This property sets the window for a concurrency detection (duration when it signals that a concurrency has been detected), even if there are no further updates in that window. Normally in a concurrent system the windows keeps sliding forward so it always remains concurrent. Setting it too high effectively disables the optimization because once concurrency has been detected it will keep that way. Setting it too low could lead to suboptimal performance because the system will try to use write-through and other optimizations even though the system is concurrent. |
|
false |
bool |
Enables/disables the Discovery SPI lookup over the old native implementations. See Discovery SPI for more information. |
|
false |
bool |
Enables the discovery joiner to use public IPs from |
|
1000000 |
int |
Default value of the capacity of executor that handles the incoming event packets. |
|
5 |
int |
Thread count for handling the incoming event packets. |
|
5000 |
int |
Frequency of the heartbeat messages sent by the clients to members. |
|
60000 |
int |
Timeout for the heartbeat messages sent by the client to members. If no messages pass between the client and member within the given time via this property in milliseconds, the connection will be closed. |
|
-1 |
int |
Controls the maximum timeout, in milliseconds, to wait for an invocation space to be available.
If an invocation cannot be made because there are too many pending invocations,
then an exponential backoff is done to give the system time to deal with
the backlog of invocations. This property controls how long an invocation is
allowed to wait before getting a |
|
1000 |
int |
Pause time between each retry cycle of an invocation in milliseconds. |
|
120 |
int |
Period, in seconds, to give up the invocation when a member in the member list is not reachable, or the member fails with an exception, or the client’s heartbeat requests are timed out. |
|
20 |
int |
Interval in seconds between each |
|
-1 |
int |
Controls the number of I/O input threads. Defaults to -1, i.e., the system decides.
If the client is using either the |
|
-1 |
int |
Controls the number of I/O output threads. Defaults to -1, i.e., the system decides.
If the client is using either the |
|
true |
bool |
Optimization that allows sending of packets over the network to be done on the calling thread if the conditions are right. This can reduce the latency and increase the performance for low threaded environments. |
|
Integer.MAX_VALUE |
int |
Maximum allowed number of concurrent invocations. You can apply a constraint on
the number of concurrent invocations in order to prevent the system from overloading.
If the maximum number of concurrent invocations is exceeded and a new invocation comes in,
Hazelcast throws |
|
5 |
int |
Frequency, in seconds, of the metrics collection cycle. Note that the preferred way for controlling this setting is Metrics Configuration. |
|
false |
bool |
Enables collecting debug metrics if set to |
|
true |
bool |
Enables the metrics collection if set to |
|
true |
bool |
Enables exposing the collected metrics over JMX if set to |
|
5000 |
int |
If an operation has sync backups, this property specifies how long the invocation will wait for acks from the backup replicas. If acks are not received from some backups, there will not be any rollback on other successful replicas. |
|
false |
bool |
When this configuration is enabled, if an operation has sync backups and acks are not received from backup replicas
in time, or the member which owns primary replica of the target partition leaves the cluster, then the invocation fails
with |
|
2 |
int |
Number of the response threads. By default, there are two response threads; this gives stable and good performance. If set to 0, the response threads are bypassed and the response handling is done on the I/O threads. Under certain conditions this can give a higher throughput, but setting to 0 should be regarded as an experimental feature. If set to 0, the IO_OUTPUT_THREAD_COUNT is really going to matter because the inbound thread will have more work to do. By default when TLS is not enabled, there is just one inbound thread. |
|
true |
bool |
Enables dynamic switching between processing the responses on the I/O threads and offloading the response threads. Under certain conditions (single threaded clients) processing on the I/O thread can increase the performance because useless handover to the response thread is removed. Also the response thread is not created until it is needed. Especially for ephemeral clients, reducing the threads can lead to increased performance and reduced memory usage. |
|
true |
string |
The client shuffles the given member list to prevent all the clients to connect
to the same member when this property is |
|
10 |
int |
Delay in seconds after which the client logs connectivity statistics after member connection changes. If a member connection state changes before the delay period has elapsed, the delay is reset. The delay reduces noise from frequent connection updates that can occur in bursts. Note that only the last connectivity view will be logged when the task is run after this delay. |
|
false |
bool |
If set to |
|
3 |
int |
Period in seconds the client statistics are collected and sent to the cluster.
This property is deprecated, use |
Advanced configuration
Declarative configuration
You can configure the client declaratively (XML), programmatically (API), or using client system properties.
For declarative configuration, the client checks the following places for the client configuration file:
-
System property: The client first checks if the
hazelcast.client.configsystem property is set to a file path e.g.-Dhazelcast.client.config=C:/myhazelcast.xml. -
Classpath: If the configuration file is not set as a system property, the client checks the classpath for the
hazelcast-client.xmlfile.
If the client does not find a configuration file, it starts with the default configuration
(hazelcast-client-default.xml) from the hazelcast.jar library.
| Before changing the configuration file, try using the default configuration as a first step. The default configuration should be fine for most environments but you can always consider a custom configuration if it doesn’t fit your requirements. |
If you want to define your own configuration file to create a Config object, you can do this using:
-
Config cfg = new XmlClientConfigBuilder(xmlFileName).build(); -
Config cfg = new XmlClientConfigBuilder(inputStream).build();
Client load balancer
LoadBalancer enables you to send operations to one of a number of endpoints (members).
Its main purpose is to determine the next member, if queried. You can use the com.hazelcast.client.LoadBalancer interface to apply different load balancing policies.
For Client cluster routing modes, the behaviour is as follows:
-
If set to
ALL_MEMBERSonly the non key-based operations are routed to the endpoint returned by theLoadBalancer -
If set to
SINGLE_MEMBER,LoadBalanceris ignored -
If set to
MULTI_MEMBER, best effort is made to route operations to the required member. If this can’t be done for any reason, operations are routed as defined by theLoadBalancer
| If you are using smart or unisocket client operation modes, see previous documentation on this topic. |
For example configurations, see the following code samples:
Configure serialization
For client side serialization, use the Hazelcast configuration. For more information, see Serialization.
Configure reliable topic on client side
Normally when a client uses a Hazelcast data structure,
that structure is configured on the member side and the client uses that configuration.
For the Reliable Topic structure, which is backed by Ringbuffer, you need to configure it on the client side instead. The class used for this configuration is ClientReliableTopicConfig.
Here is an example programmatic configuration:
Config config = new Config();
RingbufferConfig ringbufferConfig = new RingbufferConfig("default");
ringbufferConfig.setCapacity(10000000)
.setTimeToLiveSeconds(5);
config.addRingBufferConfig(ringbufferConfig);
ClientConfig clientConfig = new ClientConfig();
ClientReliableTopicConfig topicConfig = new ClientReliableTopicConfig("default");
topicConfig.setTopicOverloadPolicy( TopicOverloadPolicy.BLOCK )
.setReadBatchSize( 10 );
clientConfig.addReliableTopicConfig(topicConfig);
HazelcastInstance hz = Hazelcast.newHazelcastInstance(config);
HazelcastInstance client = HazelcastClient.newHazelcastClient(clientConfig);
ITopic topic = client.getReliableTopic(topicConfig.getName());When you create a Reliable Topic structure on your client, a Ringbuffer (with the same name as the Reliable Topic) is automatically created on the member side, with the default configuration. See the Configuring Ringbuffer section for the defaults. You can edit that configuration according to your needs.
You can also declaratively configure a Reliable Topic structure on the client side, as the following declarative code example shows:
<hazelcast-client>
...
<ringbuffer name="default">
<capacity>10000000</capacity>
<time-to-live-seconds>5</time-to-live-seconds>
</ringbuffer>
<reliable-topic name="default">
<topic-overload-policy>BLOCK</topic-overload-policy>
<read-batch-size>10</read-batch-size>
</reliable-topic>
...
</hazelcast-client>hazelcast-client:
ringbuffer:
default:
capacity: 10000000
time-to-live-seconds: 5
reliable-topic:
default:
topic-overload-policy: BLOCK
read-batch-size: 10Configure client connection retry
When a client is disconnected from the cluster, or is trying to connect to a cluster
for the first time, it searches for new connections. You can configure the frequency
of the connection attempts and client shutdown behavior using
ConnectionRetryConfig (programmatic) or connection-retry (declarative).
Declarative Configuration
<hazelcast-client>
...
<connection-strategy async-start="false" reconnect-mode="ON">
<connection-retry>
<initial-backoff-millis>1000</initial-backoff-millis>
<max-backoff-millis>60000</max-backoff-millis>
<multiplier>2</multiplier>
<cluster-connect-timeout-millis>50000</cluster-connect-timeout-millis>
<jitter>0.2</jitter>
</connection-retry>
</connection-strategy>
...
</hazelcast-client>hazelcast-client:
connection-strategy:
async-start: false
reconnect-mode: ON
connection-retry:
initial-backoff-millis: 1000
max-backoff-millis: 60000
multiplier: 2
cluster-connect-timeout-millis: 50000
jitter: 0.2Programmatic Configuration
ClientConfig config = new ClientConfig();
ClientConnectionStrategyConfig connectionStrategyConfig = config.getConnectionStrategyConfig();
ConnectionRetryConfig connectionRetryConfig = connectionStrategyConfig.getConnectionRetryConfig();
connectionRetryConfig.setInitialBackoffMillis(1000)
.setMaxBackoffMillis(60000)
.setMultiplier(2)
.setClusterConnectTimeoutMillis(50000)
.setJitter(0.2);The following are configuration element descriptions:
-
initial-backoff-millis: Specifies how long to wait (backoff), in milliseconds, after the first failure before retrying. The default value is 1000 ms. -
max-backoff-millis: Specifies the upper limit for the backoff in milliseconds. The default value is 30000 ms. -
multiplier: Factor to multiply the backoff after a failed retry. The default value is 1.05. -
cluster-connect-timeout-millis: Timeout value in milliseconds for the client to give up connecting to the current cluster. The default value is-1, i.e. infinite. For the default value, client will not stop trying to connect to the target cluster (infinite timeout). If the failover client is used with the default value of this configuration element, the failover client will try to connect alternative clusters after 120000 ms (2 minutes). For any other value, both the client and the failover client will use this as it is. -
jitter: Specifies how much to randomize backoff periods. The default value is 0.
The pseudo-code is as follows:
begin_time = getCurrentTime()
current_backoff_millis = INITIAL_BACKOFF_MILLIS
while (TryConnect(connectionTimeout)) != SUCCESS) {
if (getCurrentTime() - begin_time >= CLUSTER_CONNECT_TIMEOUT_MILLIS) {
// Give up to connecting to the current cluster and switch to another if exists.
// For the default values, CLUSTER_CONNECT_TIMEOUT_MILLIS is infinite for the
// client and equal to the 120000 ms (2 minutes) for the failover client.
}
Sleep(current_backoff_millis + UniformRandom(-JITTER * current_backoff_millis, JITTER * current_backoff_millis))
current_backoff = Min(current_backoff_millis * MULTIPLIER, MAX_BACKOFF_MILLIS)
}TryConnect tries to connect to any member that the client knows,
and the connection timeout applies for each connection. For more information, see
Set connection timeout.
Use High-Density Memory Store with Java Client
Hazelcast Enterprise Edition
If you have Hazelcast Enterprise Edition, the client’s Near Cache can benefit from the High-Density Memory Store.
Let’s consider the Java client’s Near Cache configuration (see the Configure Client Near Cache section) without High-Density Memory Store:
<hazelcast-client>
...
<near-cache name="MENU">
<eviction size="2000" eviction-policy="LFU"/>
<time-to-live-seconds>0</time-to-live-seconds>
<max-idle-seconds>0</max-idle-seconds>
<invalidate-on-change>true</invalidate-on-change>
<in-memory-format>OBJECT</in-memory-format>
</near-cache>
...
</hazelcast-client>You can configure this Near Cache to use Hazelcast’s High-Density Memory Store by setting the in-memory format to NATIVE. See the following configuration example:
<hazelcast-client>
...
<near-cache>
<eviction size="1000" max-size-policy="ENTRY_COUNT" eviction-policy="LFU"/>
<time-to-live-seconds>0</time-to-live-seconds>
<max-idle-seconds>0</max-idle-seconds>
<invalidate-on-change>true</invalidate-on-change>
<in-memory-format>NATIVE</in-memory-format>
</near-cache>
</hazelcast-client>The <eviction> element has the following attributes:
-
size: Maximum size (entry count) of the Near Cache. -
max-size-policy: Maximum size policy for eviction of the Near Cache. Available values are as follows:-
ENTRY_COUNT: Maximum entry count per member.
-
USED_NATIVE_MEMORY_SIZE: Maximum used native memory size in megabytes.
-
USED_NATIVE_MEMORY_PERCENTAGE: Maximum used native memory percentage.
-
FREE_NATIVE_MEMORY_SIZE: Minimum free native memory size to trigger cleanup.
-
FREE_NATIVE_MEMORY_PERCENTAGE: Minimum free native memory percentage to trigger cleanup.
-
-
eviction-policy: Eviction policy configuration. The default value is NONE. Available values are as follows:-
NONE: No items are evicted and the
sizeproperty is ignored. You can still combine it with time-to-live-seconds. -
LRU: Least Recently Used.
-
LFU: Least Frequently Used.
-
Keep in mind that you should have already enabled the High-Density Memory Store
usage for your client, using the <native-memory> element in the client’s configuration.
See the High-Density Memory Store section for more information about Hazelcast’s High-Density Memory Store feature.
Blue-Green Deployment
Hazelcast Enterprise Edition
Blue-green deployment refers to a client connection technique that reduces system downtime by deploying two mirrored clusters: blue (active) and green (idle). One of these clusters is running in production while the other is on standby.
Using the blue-green mechanism, clients can connect to another cluster automatically when they are blacklisted from their currently connected cluster. See the Hazelcast Management Center Reference Manual for information about blacklisting the clients.
The client’s behavior after this disconnection depends on its
reconnect-mode.
The following are the options when you are using the blue-green mechanism, i.e.,
you have alternative clusters for your clients to connect:
-
If
reconnect-modeis set toON, the client changes the cluster and blocks the invocations while doing so. -
If
reconnect-modeis set toASYNC, the client changes the cluster in the background and throwsClientOfflineExceptionwhile doing so. -
If
reconnect-modeis set toOFF, the client does not change the cluster; it shuts down immediately.
| Here it could be the case that the whole cluster is restarted. In this case, the members in the restarted cluster reject the client’s connection request, since the client is trying to connect to the old cluster. So, the client needs to search for a new cluster, if available and according to the blue-green configuration (see the following configuration related sections in this section). |
Consider the following notes for the blue-green mechanism (also valid for the disaster recovery mechanism described in the next section):
-
When a client disconnects from a cluster and connects to a new one the
InitialMemberEventandCLIENT_CHANGED_CLUSTERevents are fired. -
When switching clusters, the client reuses its UUID.
-
The client’s listener service re-registers its listeners on the new cluster; the listener service opens a new connection to all members in the current member list and registers the listeners for each connection.
-
The client’s Near Caches and Continuous Query Caches are cleared when the client joins a new cluster successfully.
-
If the new cluster’s partition size is different, the client is rejected by the cluster. The client is not able to connect to a cluster with different partition count.
-
The state of any running job on the original cluster will be undefined. * Streaming jobs may continue running on the original cluster if the cluster is still alive and the switching happened due to a network problem. If you try to query the state of the job using the Job interface, you’ll get a
JobNotFoundException.
Disaster Recovery Mechanism
When one of your clusters is gone due to a failure, the connection between your clients and members in that cluster is gone too. When a client is disconnected because of a failure in the cluster, it first tries to reconnect to the same cluster.
The client’s behavior after this disconnection depends on its
reconnect-mode, and it has the same options
that are described in the above section (Blue-Green Mechanism).
If you have provided alternative clusters for your clients to connect,
the client tries to connect to those alternative clusters (depending on the reconnect-mode).
When a failover starts, i.e., the client is disconnected and was configured to connect to alternative clusters, the current member list is not considered; the client cuts all the connections before attempting to connect to a new cluster and tries the clusters as configured. See the below configuration related sections.
Reconnect order for clusters
The order of clusters that the client will try to reconnect in a blue-green or disaster recovery scenario is decided by the order of the cluster declarations defined in the client configuration.
Every time the client disconnects from a cluster and cannot connect back to the same cluster,
this list is iterated over. The try-count configuration element limits the number of iterations before the client shuts down.
As an example, assume that your hazelcast-client-failover XML or YAML file defines the following order:
-
client-config1 -
client-config2 -
client-config3
Which means you have three alternative clusters.
<hazelcast-client-failover>
<try-count>4</try-count>
<clients>
<client>client-config1.xml</client>
<client>client-config2.xml</client>
<client>client-config3.xml</client>
</clients>
</hazelcast-client-failover>hazelcast-client-failover:
try-count: 4
clients:
- client-config1.yaml
- client-config2.yaml
- client-config3.yamlIf the client is disconnected from the cluster configured in client-config2, the cluster will try to connect to the next cluster in the list, which is client-config3.
If the client fails to connect to this cluster then the try-count is incremented, and the client tries to connect to the next alternative cluster, which in this case is client-config1 (because it has reached the end of the list and returns to the start). This iteration continues until either the client successfully connects to a cluster or the try-count limit is reached. If the try-count is reached without connecting, the client shuts down.
Failures
Client deadline failure detector
Deadline Failure Detector uses an absolute timeout for missing/lost heartbeats. After timeout, a member is considered as crashed/unavailable and marked as suspected.
Deadline Failure Detector has two configuration properties:
-
hazelcast.client.heartbeat.interval: This is the interval at which client sends heartbeat messages to members. -
hazelcast.client.heartbeat.timeout: This is the timeout which defines when a cluster member is suspected, because it has not sent any response back to client requests.
The value of hazelcast.client.heartbeat.interval should be smaller than
that of hazelcast.client.heartbeat.timeout. In addition, the value of system property
hazelcast.client.max.no.heartbeat.seconds, which is set on the member side,
should be larger than that of hazelcast.client.heartbeat.interval.
|
The following is a declarative example showing how you can configure the Deadline Failure Detector
for your client (in the client’s configuration XML file, e.g., hazelcast-client.xml):
<hazelcast-client>
...
<properties>
<property name="hazelcast.client.heartbeat.timeout">60000</property>
<property name="hazelcast.client.heartbeat.interval">5000</property>
</properties>
...
</hazelcast-client>hazelcast-client:
properties
hazelcast.client.heartbeat.timeout: 60000
hazelcast.client.heartbeat.interval: 5000And, the following is the equivalent programmatic configuration:
ClientConfig config = ...;
config.setProperty("hazelcast.client.heartbeat.timeout", "60000");
config.setProperty("hazelcast.client.heartbeat.interval", "5000");
[...]Client ping failure detector
In addition to the Deadline Failure Detector, the Ping Failure Detector may be configured on your client. Please note that this detector is disabled by default. The Ping Failure Detector operates at Layer 3 of the OSI protocol and provides much quicker and more deterministic detection of hardware and other lower level events. When the JVM process has enough permissions to create RAW sockets, the implementation chooses to rely on ICMP Echo requests. This is preferred.
If there are not enough permissions, it can be configured to fallback on attempting a TCP Echo on port 7. In the latter case, both a successful connection or an explicit rejection is treated as "Host is Reachable". Or, it can be forced to use only RAW sockets. This is not preferred as each call creates a heavyweight socket and moreover the Echo service is typically disabled.
For the Ping Failure Detector to rely only on the ICMP Echo requests, the following criteria need to be met:
-
Supported OS: as of Java 1.8 only Linux/Unix environments are supported.
-
The Java executable must have the
cap_net_rawcapability. -
The file
ld.confmust be edited to overcome the rejection by the dynamic linker when loading libs from untrusted paths. -
ICMP Echo Requests must not be blocked by the receiving hosts.
The details of these requirements are explained in the Requirements section of Hazelcast members' Ping Failure Detector.
If any of the above criteria isn’t met, then isReachable will always
fall back on TCP Echo attempts on port 7.
An example declarative configuration to use the Ping Failure Detector is
as follows (in the client’s configuration XML file, e.g., hazelcast-client.xml):
<hazelcast-client>
...
<network>
<icmp-ping enabled="true">
<timeout-milliseconds>1000</timeout-milliseconds>
<interval-milliseconds>1000</interval-milliseconds>
<ttl>255<ttl>
<echo-fail-fast-on-startup>false</echo-fail-fast-on-startup>
<max-attempts>2</max-attempts>
</icmp-ping>
</network>
...
</hazelcast-client>hazelcast-client:
network:
icmp-ping:
enabled: false
timeout-milliseconds: 1000
interval-milliseconds: 1000
ttl: 255
echo-fail-fast-on-startup: false
max-attempts: 2And, the equivalent programmatic configuration:
ClientConfig config = ...;
ClientNetworkConfig networkConfig = clientConfig.getNetworkConfig();
ClientIcmpPingConfig clientIcmpPingConfig = networkConfig.getClientIcmpPingConfig();
clientIcmpPingConfig.setIntervalMilliseconds(1000)
.setTimeoutMilliseconds(1000)
.setTtl(255)
.setMaxAttempts(2)
.setEchoFailFastOnStartup(false)
.setEnabled(true);The following are the descriptions of configuration elements and attributes:
-
enabled: Enables the legacy ICMP detection mode, works cooperatively with the existing failure detector and only kicks-in after a pre-defined period has passed with no heartbeats from a member. Its default value isfalse. -
timeout-milliseconds: Number of milliseconds until a ping attempt is considered failed if there was no reply. Its default value is 1000 milliseconds. -
max-attempts: Maximum number of ping attempts before the member gets suspected by the detector. Its default value is 3. -
interval-milliseconds: Interval, in milliseconds, between each ping attempt. 1000ms (1 sec) is also the minimum interval allowed. Its default value is 1000 milliseconds. -
ttl: Maximum number of hops the packets should go through. Its default value is 255. You can set to 0 to use your system’s default TTL.
In the above example configuration, the Ping Failure Detector attempts 2 pings, one every second, and waits up to 1 second for each to complete. If there is no successful ping after 2 seconds, the member gets suspected.
To enforce the Requirements,
the property echo-fail-fast-on-startup can also be set to true, in which case Hazelcast fails to start if any of the requirements
isn’t met.
Unlike the Hazelcast members, Ping Failure Detector works always in parallel with Deadline Failure Detector on the clients. Below is a summary table of all possible configuration combinations of the Ping Failure Detector.
| ICMP | Fail-Fast | Description | Linux | Windows | macOS |
|---|---|---|---|---|---|
true |
false |
Parallel ping detector, works in parallel with the configured failure detector. Checks periodically if members are live (OSI Layer 3) and suspects them immediately, regardless of the other detectors. |
Supported ICMP Echo if available - Falls back on TCP Echo on port 7 |
Supported TCP Echo on port 7 |
Supported ICMP Echo if available - Falls back on TCP Echo on port 7 |
true |
true |
Parallel ping detector, works in parallel with the configured failure detector. Checks periodically if members are live (OSI Layer 3) and suspects them immediately, regardless of the other detectors. |
Supported - Requires OS Configuration Enforcing ICMP Echo if available - No start up if not available |
Not Supported |
Not Supported - Requires root privileges |
Java Client Failure Detectors
The client failure detectors are responsible to determine if a member in the cluster is unreachable or crashed. The most important problem in the failure detection is to distinguish whether a member is still alive but slow, or has crashed. But according to the famous FLP result, it is impossible to distinguish a crashed member from a slow one in an asynchronous system. A workaround to this limitation is to use unreliable failure detectors. An unreliable failure detector allows a member to suspect that others have failed, usually based on liveness criteria but it can make mistakes to a certain degree.
Hazelcast Java client has two built-in failure detectors: Deadline Failure Detector and Ping Failure Detector. These client failure detectors work independently of the member failure detectors, e.g., you do not need to enable the member failure detectors to benefit from the client ones.