In some cases, detecting and handling network partitions are not very straightforward. Because these kind of network partitions don’t cause a clearly separated, distinct groups. But they create overlapping partitioned groups or worse, asymmetric communication failures between members. This can be called as partial network partitioning.
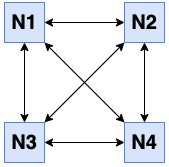
Assume [N1, N2, N3, N4] is a cluster with four members. This is how a healthy cluster looks,
each member has a connection to other members:
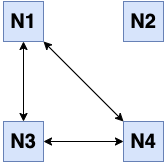
Assuming that N2 becomes partitioned away from rest of the cluster when it disconnects from
the other members, two separate groups are formed: [N1, N3, N4] and [N2].
This is called a full network partition:
But when N2 cannot communicate only one or two of the rest, then there won’t be a clear
separation of partitioned groups. For instance when N2 becomes disconnected from both
N3 and N4, two overlapping healthy groups are formed: [N1, N2] and [N1, N3, N4].

Or, when N2 is disconnected only from N1, again two overlapping healthy groups are
formed, but this time with equal size: [N1, N3, N4] and [N2, N3, N4].
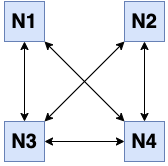
Last two figures above are samples of the partial network partitioning. Our solution to this problem is to figure out the largest set of fully-connected members and artificially separate these members from the rest. This way we will have a completely separated set of members without any intersection. This is the same problem with the maximum clique problem in graph theory. Hence we are using an implementation of the Bron–Kerbosch algorithm to find the maximum clique.
Normally each Hazelcast member tracks the liveliness of other members using local failure detectors. But they don’t share their failure detection knowledge with other cluster members. In order to execute the Bron–Kerbosch algorithm and figure out the largest set of fully-connected members, we need to gather those local failure detection data from all members. When partial network partitioning resolution mechanism is enabled, all members send their local failure detections (suspicions about other members) inside the usual heartbeat message. (See the Failure Detector Configuration section for more info about failure detectors.) The master (oldest) member in the cluster gathers all this information and executes the maximum clique algorithm and then decides the smallest set of Hazelcast members, if any, to kick from the cluster so that the remaining members are fully-connected to each other again. In a healthy cluster this set is empty.
This process has two properties to configure:
-
hazelcast.partial.member.disconnection.resolution.heartbeat.count: When the master receives a heartbeat problem report from another member, it first waits for a number of heartbeat rounds to allow other members to report their problems if there is any. After that, it takes all reports received so far and checks if it can update the cluster member in a way that the minimum number of members will be kicked from the cluster and there won’t be any heartbeat problem between the remaining members.If this configuration option is set to
0, this functionality is disabled. It is recommended to be set to at least3or5so that the master will wait long enough to collect heartbeat problem reports. Otherwise, the master member can make sub-optimal decisions. Default value is0. -
hazelcast.partial.member.disconnection.resolution.algorithm.timeout.seconds: The partial member disconnection resolution mechanism uses a graph algorithm that finds a maximum clique in non-polynomial time. Since it could take a lot of time to find a maximum clique in a large graph, i.e, in a large cluster with lots of random network disconnections, we use a timeout mechanism to stop execution of the algorithm. Default value is5seconds.
| Partial network partition resolution mechanism is not enabled by default. |