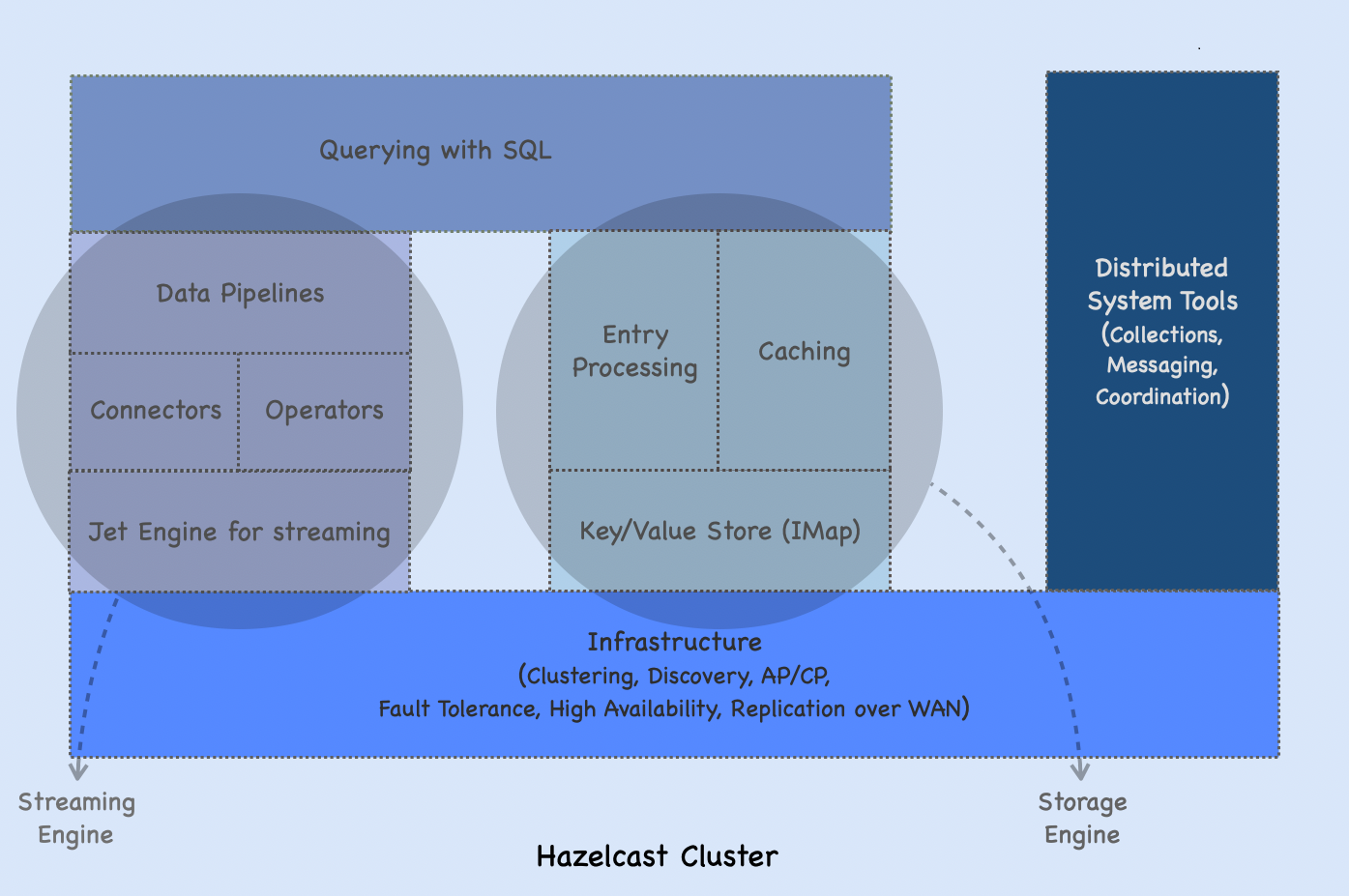
Hazelcast is a distributed computation and storage platform for consistent low-latency querying, aggregation, and stateful computation against event streams and traditional data sources. This guide outlines how Hazelcast works under the hood to help you understand some important concepts.
In Hazelcast, data is load-balanced in-memory across a cluster. This cluster is a network of members each of which runs Hazelcast. A cluster of Hazelcast members share both the data storage and computational load which can dynamically scale up and down. When you add new members to the cluster, both the data and computations are automatically rebalanced across the cluster.
Discovery and Clustering
Members discover each other automatically and form a cluster. after the cluster is formed, members communicate with each other via TCP.
Hazelcast supports automatic discovery in cloud environments such as Amazon EC2, Google Cloud Platform and Azure. You can also configure Hazelcast to discover members by TCP/IP or multicast. In addition, you can make use of the automatic member discovery in the Kubernetes environment.
Fault Tolerance
Hazelcast distributes your storage data, computational data, and backups, among all cluster members. This way, if a member is lost, Hazelcast can restore the data from these backups, providing continuous availability.
Backups are distributed and stored in memory (RAM). The distribution happens on the partition level, where the primary data and its backups are stored in the partitions.
When a member in your cluster is lost, Hazelcast redistributes the backups on the remaining members so that every partition has a backup. This makes Hazelcast resilient to data loss. The number of backups is configurable. Based on the configuration, data can be kept in multiple replicas of a partition.
High Availability
In Hazelcast, cluster members monitor the health of each other. When a cluster member becomes inaccessible due to an event such as a network failure, other members cooperatively diagnose the state and immediately take over the responsibility of the failed member. To determine if a member is unreachable or crashed, Hazelcast provides built-in failure detectors.
Hazelcast also provides replication over WAN for high availability. You can have deployments across multiple data centers using the WAN replication mechanism which offers protection against a data center or wider network failures.
AP/CP
In the context of the CAP theorem, Hazelcast offers AP and CP data structures:
-
Availability: All working members in a distributed system return a valid response to any request, without exceptions.
-
Consistency: All the clients connected to the system see the same data at the same time, no matter which member they connect to; whenever data is written to a member, it is instantly replicated to all the other members in the system.
-
Partition Tolerance: Partition refers to a lost or temporarily delayed connection between the members; partition tolerance refers to continued work of the cluster despite any number of communication breakdowns between the members of the cluster.
Hazelcast as an AP system delivers availability and partition tolerance at the expense of consistency. When a communication breakdown occurs, all members remain available, however some members affected by the partition might return an older version of data than others. When the partition is resolved, Hazelcast typically synchronizes the members to repair all inconsistencies in the system.
As a CP system, Hazelcast delivers consistency and partition tolerance at the expense of availability. When a partition occurs between any members, Hazelcast makes the non-consistent member unavailable until the partition is resolved.
Data structures exposed under HazelcastInstance API are all AP data structures and the ones
accessed via HazelcastInstance.getCPSubsytem() provides CP structures and APIs, which are built
on the Raft consensus algorithm. See the Consistency and Replication Model section
and CP Subsystem section.
Storage Engine
The storage engine provides caching and data processing on top of Hazelcast’s key/value store called IMap. You can load and store data from/to external data sources, control the eviction of data entries and execute your codes on them, use Hazelcast’s specification-compliant JCache implementation and integrate your cache with Spring.
Jet (Streaming) Engine
The Jet engine is responsible for running streaming applications. For this, it uses many different connectors (sources and sinks) to ingest data into Hazelcast and output data that data, and stateless/stateful transforms with operators including join, aggregate and sort to process data.
A data pipeline is a series of processing steps that consist of a source, one or more processing steps, and a sink. It may enable the flow of data from an application to a data warehouse, from a data lake to an analytics database, or into a payment processing system. Hazelcast allows you to create data pipelines, using either SQL or the Hazelcast Java API. See About Data Pipelines.
Distributed System Tools
Hazelcast offers distributed implementations of standard collections, concurrency utilities, and publish/subscribe messaging model.
Standard collection implementations include Maps, Queues, Lists, Sets and Ringbuffers. Concurrency utilities include AtomicLongs, AtomicReferences, Semaphores and CountDownLatches. It also provides a broadcast messaging system based on publish/subscribe model; it lets applications communicate in real time at high speed. Your applications can publish to specific channels called topics, and then one or more subscribers can read the messages from those topics. See the Distributed Data Structures.
Hazelcast also provides a CP subsystem for distributed coordination use cases such as leader election, distributed locking, synchronization and metadata management. See the CP Subsystem section.
SQL Service
Hazelcast’s SQL service lets you query static and streaming data. You can load static data from sources (files and maps) to transform and analyze it. Hazelcast can also load and query real-time streaming data as it is being generated, which is ideal for use cases that require complex queries with low latency, e.g., fraud detection. Besides performing transformations and queries, you can store your transform/query results in one or more systems; it is useful for sending results to other systems or caching results in Hazelcast to avoid running redundant queries.
