| MapReduce is deprecated since Hazelcast 3.8. You can use Fast-Aggregations and Hazelcast Jet for map aggregations and general data processing, respectively. See the MapReduce Deprecation section for more details. |
You have likely heard about MapReduce ever since Google released its research white paper on this concept. With Hadoop as the most common and well known implementation, MapReduce gained a broad audience and made it into all kinds of business applications dominated by data warehouses.
MapReduce is a software framework for processing large amounts of data in a distributed way. Therefore, the processing is normally spread over several machines. The basic idea behind MapReduce is that source data is mapped into a collection of key-value pairs and reducing those pairs, grouped by key, in a second step towards the final result.
The main idea can be summarized with the following steps:
-
Read the source data.
-
Map the data to one or multiple key-value pairs.
-
Reduce all pairs with the same key.
Use Cases
The best known examples for MapReduce algorithms are text processing tools, such as counting the word frequency in large texts or websites. Apart from that, there are more interesting examples of use cases listed below:
-
Log Analysis
-
Data Querying
-
Aggregation and summing
-
Distributed Sort
-
ETL (Extract Transform Load)
-
Credit and Risk management
-
Fraud detection
-
and more.
Understanding MapReduce
This section gives a deeper insight into the MapReduce pattern and helps you understand the semantics behind the different MapReduce phases and how they are implemented in Hazelcast.
In addition to this, the following sections compare Hadoop and Hazelcast MapReduce implementations to help adopters with Hadoop backgrounds quickly get familiar with Hazelcast MapReduce.
MapReduce Workflow Example
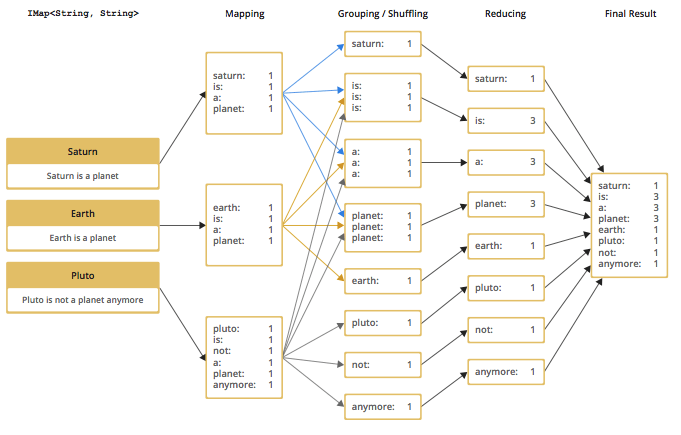
The flowchart below demonstrates the basic workflow of the word count example (distributed occurrences analysis) mentioned in the MapReduce section introduction. From left to right, it iterates over all the entries of a data structure (in this case an IMap). In the mapping phase, it splits the sentence into single words and emits a key-value pair per word: the word is the key, 1 is the value. In the next phase, values are collected (grouped) and transported to their corresponding reducers, where they are eventually reduced to a single key-value pair, the value being the number of occurrences of the word. At the last step, the different reducer results are grouped up to the final result and returned to the requester.
In pseudo code, the corresponding map and reduce function would look like the following. A Hazelcast code example is shown in the next section.
map( key:String, document:String ):Void ->
for each w:word in document:
emit( w, 1 )
reduce( word:String, counts:List[Int] ):Int ->
return sum( counts )MapReduce Phases
As seen in the workflow example, a MapReduce process consists of multiple phases. The original MapReduce pattern describes two phases (map, reduce) and one optional phase (combine). In Hazelcast, these phases either only exist virtually to explain the data flow, or are executed in parallel during the real operation while the general idea is still persisting.
(K x V)* → (L x W)*
[(k*1*, v*1*), …, (k*n*, v*n*)] → [(l*1*, w*1*), …, (l*m*, w*m*)]
Mapping Phase
The mapping phase iterates all key-value pairs of any kind of legal input source. The mapper then analyzes the input pairs and emits zero or more new key-value pairs.
K x V → (L x W)*
(k, v) → [(l*1*, w*1*), …, (l*n*, w*n*)]
Combine Phase
In the combine phase, multiple key-value pairs with the same key are collected and combined to an intermediate result before being sent to the reducers. Combine phase is also optional in Hazelcast, but is highly recommended to lower the traffic.
In terms of the word count example, this can be explained using the sentences "Saturn is a planet but the Earth is a planet, too". As shown above, we would send two key-value pairs (planet, 1). The registered combiner now collects those two pairs and combines them into an intermediate result of (planet, 2). Instead of two key-value pairs sent through the wire, there is now only one for the key "planet".
The pseudo code for a combiner is similar to the reducer.
combine( word:String, counts:List[Int] ):Void ->
emit( word, sum( counts ) )Grouping / Shuffling Phase
The grouping or shuffling phase only exists virtually in Hazelcast since it is not a real phase; emitted key-value pairs with the same key are always transferred to the same reducer in the same job. They are grouped together, which is equivalent to the shuffling phase.
Reducing Phase
In the reducing phase, the collected intermediate key-value pairs are reduced by their keys to build the final by-key result. This value can be a sum of all the emitted values of the same key, an average value, or something completely different, depending on the use case.
Here is a reduced representation of this phase.
L x W* → X*
(l, [w*1*, …, w*n*]) → [x*1*, …, x*n*]
Producing the Final Result
This is not a real MapReduce phase, but it is the final step in Hazelcast after all reducers are notified that reducing has finished. The original job initiator then requests all reduced results and builds the final result.
Additional MapReduce Resources
The Internet is full of useful resources for finding deeper information on MapReduce. Below is a short collection of more introduction material. In addition, there are books written about all kinds of MapReduce patterns and how to write a MapReduce function for your use case. To name them all is out of the scope of this documentation, but here are some resources:
Using the MapReduce API
This section explains the basics of the Hazelcast MapReduce framework. While walking through the different API classes, we will build the word count example that was discussed earlier and create it step by step.
The Hazelcast API for MapReduce operations consists of a fluent DSL-like configuration
syntax to build and submit jobs. JobTracker is the basic entry point to all MapReduce
operations and is retrieved from com.hazelcast.core.HazelcastInstance by calling getJobTracker
and supplying the name of the required JobTracker configuration. The configuration for
JobTrackers will be discussed later; for now we focus on the API itself.
In addition, the complete submission part of the API is built to support a fully reactive
way of programming.
To give an easy introduction to people used to Hadoop, we created the class names to be as familiar as possible to their counterparts on Hadoop. That means while most users recognize a lot of similar sounding classes, the way to configure the jobs is more fluent due to the DSL-like styled API.
While building the example, we will go through as many options as possible, e.g., we will
create a specialized JobTracker configuration (at the end). Special JobTracker configuration
is not required, because for all other Hazelcast features you can use "default" as the
configuration name. However, special configurations offer better options to predict behavior
of the framework execution.
The full example is available here as a ready to run Maven project.
Retrieving a JobTracker Instance
JobTracker creates Job instances, whereas every instance of com.hazelcast.mapreduce.Job
defines a single MapReduce configuration. The same Job can be submitted multiple times regardless
of whether it is executed in parallel or after the previous execution is finished.
After retrieving the JobTracker, be aware that it should only be used with data structures
derived from the same HazelcastInstance. Otherwise, you can get unexpected behavior.
|
To retrieve a JobTracker from Hazelcast, we start by using the "default" configuration for
convenience reasons to show the basic way.
JobTracker jobTracker = hazelcastInstance.getJobTracker( "default" );JobTracker is retrieved using the same kind of entry point as most other Hazelcast features.
After building the cluster connection, you use the created HazelcastInstance to request the
configured (or default) JobTracker from Hazelcast.
The next step is creating a new Job and configuring it to execute our first MapReduce request
against cluster data.
Creating a Job
As mentioned in the previous section, you create a Job using the retrieved JobTracker instance.
A Job defines exactly one configuration of a MapReduce task. Mapper, combiner and reducers are
defined per job. However, since the Job instance is only a configuration, it can be submitted
multiple times, regardless of whether executions happen in parallel or one after the other.
A submitted job is always identified using a unique combination of the JobTracker’s name and a
jobId generated on submit-time. The way to retrieve the `jobId is shown in one of the later
sections.
To create a Job, a second class com.hazelcast.mapreduce.KeyValueSource is necessary. We will
have a deeper look at the KeyValueSource class in the next section. KeyValueSource is used
to wrap any kind of data or data structure into a well defined set of key-value pairs.
The example code below is a direct follow up to the example in Retrieving a JobTracker Instance. It reuses the already created HazelcastInstance and JobTracker
instances.
The example starts by retrieving an instance of our data map and then it creates the Job instance. Implementations used to configure the Job are discussed while walking further through the API documentation.
| Since the Job class is highly dependent upon generics to support type safety, the generics change over time and may not be assignment compatible to old variable types. To make use of the full potential of the fluent API, we recommend you use fluent method chaining as shown in this example to prevent the need for too many variables. |
IMap<String, String> map = hazelcastInstance.getMap( "articles" );
KeyValueSource<String, String> source = KeyValueSource.fromMap( map );
Job<String, String> job = jobTracker.newJob( source );
ICompletableFuture<Map<String, Long>> future = job
.mapper( new TokenizerMapper() )
.combiner( new WordCountCombinerFactory() )
.reducer( new WordCountReducerFactory() )
.submit();
// Attach a callback listener
future.andThen( buildCallback() );
// Wait and retrieve the result
Map<String, Long> result = future.get();As seen above, we create the Job instance and define a mapper, combiner and reducer. Then
we submit the request to the cluster. The submit method returns an ICompletableFuture
that can be used to attach our callbacks or to wait for the result to be processed in a
blocking fashion.
There are more options available for job configurations, such as defining a general chunk size or on what keys the operation will operate. See Hazelcast source code for the Job.java for more information.
Creating Key-Value Input Sources with KeyValueSource
KeyValueSource can either wrap Hazelcast data structures (like IMap, MultiMap, IList, ISet)
into key-value pair input sources, or build your own custom key-value input source. The
latter option makes it possible to feed Hazelcast MapReduce with all kinds of data, such
as just-in-time downloaded web page contents or data files. People familiar with Hadoop
will recognize similarities with the Input class.
You can imagine a KeyValueSource as a bigger java.util.Iterator implementation. Whereas
most methods must be implemented, implementing the getAllKeys method is optional.
If implementation is able to gather all keys upfront, it should be implemented and
isAllKeysSupported must return true. That way, Job configured KeyPredicates are
able to evaluate keys upfront before sending them to the cluster. Otherwise they are
serialized and transferred as well, to be evaluated at execution time.
As shown in the example above, the abstract KeyValueSource class provides a number of
static methods to easily wrap Hazelcast data structures into KeyValueSource
implementations already provided by Hazelcast. The data structures' generics are
inherited by the resulting KeyValueSource instance. For data structures like IList or
ISet, the key type is always String. While mapping, the key is the data structure’s name,
whereas
the value type and value itself are inherited from the IList or ISet itself.
// KeyValueSource from com.hazelcast.core.IMap
IMap<String, String> map = hazelcastInstance.getMap( "my-map" );
KeyValueSource<String, String> source = KeyValueSource.fromMap( map );// KeyValueSource from com.hazelcast.core.MultiMap
MultiMap<String, String> multiMap = hazelcastInstance.getMultiMap( "my-multimap" );
KeyValueSource<String, String> source = KeyValueSource.fromMultiMap( multiMap );// KeyValueSource from com.hazelcast.core.IList
IList<String> list = hazelcastInstance.getList( "my-list" );
KeyValueSource<String, String> source = KeyValueSource.fromList( list );// KeyValueSource from com.hazelcast.core.ISet
ISet<String> set = hazelcastInstance.getSet( "my-set" );
KeyValueSource<String, String> source = KeyValueSource.fromSet( set );PartitionIdAware
The com.hazelcast.mapreduce.PartitionIdAware interface can be implemented by the
KeyValueSource implementation if the underlying data set is aware of the Hazelcast
partitioning schema (as it is for all internal data structures). If this interface is
implemented, the same KeyValueSource instance is reused multiple times for all partitions
on the cluster member. As a consequence, the close and open methods are also executed
multiple times but once per partitionId.
Implementing Mapping Logic with Mapper
You implement the mapping logic using the Mapper interface. Mappers can transform,
split, calculate and aggregate data from data sources. In Hazelcast you can also integrate
data from more than the KeyValueSource data source by implementing
com.hazelcast.core.HazelcastInstanceAware and requesting additional maps, multimaps,
list and/or sets.
The mappers map function is called once per available entry in the data structure. If
you work on distributed data structures that operate in a partition-based fashion, multiple
mappers work in parallel on the different cluster members on the members' assigned partitions.
Mappers then prepare and maybe transform the input key-value pair and emit zero or more
key-value pairs for the reducing phase.
For our word count example, we retrieve an input document (a text document) and we transform it by splitting the text into the available words. After that, as discussed in the pseudo code, we emit every single word with a key-value pair with the word as the key and 1 as the value.
A common implementation of that Mapper might look like the following example:
public class TokenizerMapper implements Mapper<String, String, String, Long> {
private static final Long ONE = Long.valueOf( 1L );
@Override
public void map(String key, String document, Context<String, Long> context) {
StringTokenizer tokenizer = new StringTokenizer( document.toLowerCase() );
while ( tokenizer.hasMoreTokens() ) {
context.emit( tokenizer.nextToken(), ONE );
}
}
}This code splits the mapped texts into their tokens, iterates over the tokenizer as long as there are more tokens and emits a pair per word. Note that we’re not yet collecting multiple occurrences of the same word, we just fire every word on its own.
LifecycleMapper / LifecycleMapperAdapter
The LifecycleMapper interface or its adapter class LifecycleMapperAdapter can be used to make the Mapper implementation lifecycle aware. That means it will be notified when mapping of a partition or set of data begins and when the last entry was mapped.
Only special algorithms might need those additional lifecycle events to prepare, clean up, or emit additional values.
Minimizing Cluster Traffic with Combiner
As stated in the introduction, a Combiner is used to minimize traffic between the different cluster members when transmitting mapped values from mappers to the reducers. It does this by aggregating multiple values for the same emitted key. This is a fully optional operation, but using it is highly recommended.
Combiners can be seen as an intermediate reducer. The calculated value is always assigned back to the key for which the combiner initially was created. Since combiners are created per emitted key, the Combiner implementation itself is not defined in the jobs configuration; instead, a CombinerFactory that is able to create the expected Combiner instance is created.
Because Hazelcast MapReduce is executing the mapping and reducing phases in parallel, the
Combiner implementation must be able to deal with chunked data. Therefore, you must reset
its internal state whenever you call finalizeChunk. Calling the finalizeChunk method
creates a chunk of intermediate data to be grouped (shuffled) and sent to the reducers.
Combiners can override beginCombine and finalizeCombine to perform preparation or
cleanup work.
For our word count example, we are going to have a simple CombinerFactory and Combiner implementation similar to the following example.
public class WordCountCombinerFactory
implements CombinerFactory<String, Long, Long> {
@Override
public Combiner<Long, Long> newCombiner( String key ) {
return new WordCountCombiner();
}
private class WordCountCombiner extends Combiner<Long, Long> {
private long sum = 0;
@Override
public void combine( Long value ) {
sum++;
}
@Override
public Long finalizeChunk() {
return sum;
}
@Override
public void reset() {
sum = 0;
}
}
}The Combiner must be able to return its current value as a chunk and reset the internal
state by setting sum back to 0. Since combiners are always called from a single thread,
no synchronization or volatility of the variables is necessary.
Doing Algorithm Work with Reducer
Reducers do the last bit of algorithm work. This can be aggregating values, calculating averages, or any other work that is expected from the algorithm.
Since values arrive in chunks, the reduce method is called multiple times for every
emitted value of the creation key. This also can happen multiple times per chunk if no
Combiner implementation was configured for a job configuration.
Unlike combiners, a reducer’s finalizeReduce method is only called once per reducer
(which means once per key). Therefore, a reducer does not need to reset its internal
state at any time.
Reducers can override beginReduce to perform preparation work.
For our word count example, the implementation looks similar to the following code example.
public class WordCountReducerFactory implements ReducerFactory<String, Long, Long> {
@Override
public Reducer<Long, Long> newReducer( String key ) {
return new WordCountReducer();
}
private class WordCountReducer extends Reducer<Long, Long> {
private volatile long sum = 0;
@Override
public void reduce( Long value ) {
sum += value.longValue();
}
@Override
public Long finalizeReduce() {
return sum;
}
}
}Reducers Switching Threads
Unlike combiners, reducers tend to switch threads if running out of data to prevent
blocking threads from the JobTracker configuration. They are rescheduled at a later
point when new data to be processed arrives, but are unlikely to be executed on the same
thread as before. As of Hazelcast version 3.3.3 the guarantee for memory visibility on the
new thread is ensured by the framework. This means the previous requirement for making
fields volatile is dropped.
Modifying the Result with Collator
A Collator is an optional operation that is executed on the job emitting member and is able to modify the finally reduced result before returned to the user’s codebase. Only special use cases are likely to use collators.
For an imaginary use case, we might want to know how many words were all over in the
documents we analyzed. For this case, a Collator implementation can be given to the
submit method of the Job instance.
A collator would look like the following snippet:
public class WordCountCollator implements Collator<Map.Entry<String, Long>, Long> {
@Override
public Long collate( Iterable<Map.Entry<String, Long>> values ) {
long sum = 0;
for ( Map.Entry<String, Long> entry : values ) {
sum += entry.getValue().longValue();
}
return sum;
}
}The definition of the input type is a bit strange, but because Combiner and Reducer implementations are optional, the input type heavily depends on the state of the data. As stated above, collators are non-typical use cases and the generics of the framework always help in finding the correct signature.
Preselecting Keys with KeyPredicate
You can use KeyPredicate to pre-select whether or not a key should be selected for
mapping in the mapping phase. If the KeyValueSource implementation is able to know
all keys prior to execution, the keys are filtered before the operations are divided
among the different cluster members.
A KeyPredicate can also be used to select only a special range of data, e.g., a
time frame, or in similar use cases.
A basic KeyPredicate implementation that only maps keys containing the word
"hazelcast" might look like the following code example:
public class WordCountKeyPredicate implements KeyPredicate<String> {
@Override
public boolean evaluate( String s ) {
return s != null && s.toLowerCase().contains( "hazelcast" );
}
}Job Monitoring with TrackableJob
You can retrieve a TrackableJob instance after submitting a job. It is requested
from the JobTracker using the unique jobId (per JobTracker). You can use it get
runtime statistics of the job. The information available is limited to the number of
processed (mapped) records and the processing state of the different partitions or
members (if KeyValueSource is not PartitionIdAware).
To retrieve the jobId after submission of the job, use com.hazelcast.mapreduce.JobCompletableFuture
instead of the com.hazelcast.core.ICompletableFuture as the variable type for
the returned future.
The example code below gives a quick introduction on how to retrieve the instance and the runtime data. For more information, please have a look at the Javadoc corresponding your running Hazelcast version.
The example performs the following steps to get the job instance.
-
It gets the map with the hazelcastInstance
getMapmethod. -
From the map, it gets the source with the KeyValueSource
fromMapmethod. -
From the source, it gets a job with the JobTracker
newJobmethod.
IMap<String, String> map = hazelcastInstance.getMap( "articles" );
KeyValueSource<String, String> source = KeyValueSource.fromMap( map );
Job<String, String> job = jobTracker.newJob( source );
JobCompletableFuture<Map<String, Long>> future = job
.mapper( new TokenizerMapper() )
.combiner( new WordCountCombinerFactory() )
.reducer( new WordCountReducerFactory() )
.submit();
String jobId = future.getJobId();
TrackableJob trackableJob = jobTracker.getTrackableJob(jobId);
JobProcessInformation stats = trackableJob.getJobProcessInformation();
int processedRecords = stats.getProcessedRecords();
log( "ProcessedRecords: " + processedRecords );
JobPartitionState[] partitionStates = stats.getPartitionStates();
for ( JobPartitionState partitionState : partitionStates ) {
log( "PartitionOwner: " + partitionState.getOwner()
+ ", Processing state: " + partitionState.getState().name() );
}| Caching of the JobProcessInformation does not work on Java native clients since current values are retrieved while retrieving the instance to minimize traffic between executing member and client. |
Configuring JobTracker
You configure JobTracker configuration to set up behavior of the Hazelcast
MapReduce framework.
Every JobTracker is capable of running multiple MapReduce jobs at once; one
configuration is meant as a shared resource for all jobs created by the same
JobTracker. The configuration gives full control over the expected load behavior
and thread counts to be used.
The following snippet shows a typical JobTracker configuration. The configuration
properties are discussed below the example.
<hazelcast>
...
<jobtracker name="default">
<max-thread-size>0</max-thread-size>
<!-- Queue size 0 means number of partitions * 2 -->
<queue-size>0</queue-size>
<retry-count>0</retry-count>
<chunk-size>1000</chunk-size>
<communicate-stats>true</communicate-stats>
<topology-changed-strategy>CANCEL_RUNNING_OPERATION</topology-changed-strategy>
</jobtracker>
...
</hazelcast>JobTracker has the following configuration elements:
-
max-thread-size: Maximum thread pool size of the JobTracker. -
queue-size: Maximum number of tasks that are able to wait to be processed. A value of 0 means an unbounded queue. Very low numbers can prevent successful execution since the job might not be correctly scheduled or intermediate chunks might be lost. -
retry-count: Currently not used. Reserved for later use where the framework will automatically try to restart/retry operations from an available save point. -
chunk-size: Number of emitted values before a chunk is sent to the reducers. If your emitted values are big or you want to better balance your work, you might want to change this to a lower or higher value. A value of 0 means immediate transmission, but remember that low values mean higher traffic costs. A very high value might cause an OutOfMemoryError to occur if the emitted values do not fit into heap memory before being sent to the reducers. To prevent this, you might want to use a combiner to pre-reduce values on mapping members. -
communicate-stats: Specifies whether the statistics (for example, statistics about processed entries) are transmitted to the job emitter. This can show progress to a user inside of an UI system, but it produces additional traffic. If not needed, you might want to deactivate this. -
topology-changed-strategy: Specifies how the MapReduce framework reacts on topology changes while executing a job. Currently, only CANCEL_RUNNING_OPERATION is fully supported, which throws an exception to the job emitter (throwscom.hazelcast.mapreduce.TopologyChangedException).
Hazelcast MapReduce Architecture
This section explains some of the internals of the MapReduce framework. This is more advanced information. If you’re not interested in how it works internally, you might want to skip this section.
Member Interoperation Example
To understand the following technical internals, we first have a short look at what happens in terms of an example workflow.
As a simple example, think of an IMap<String, Integer> and emitted keys
having the same types. Imagine you have a cluster with three members and you
initiate the MapReduce job on the first member. After you requested the JobTracker
from your running/connected Hazelcast, we submit the task and retrieve the
ICompletableFuture, which gives us a chance to wait for the result to be calculated
or to add a callback (and being more reactive).
The example expects that the chunk size is 0 or 1, so an emitted value is directly sent to the reducers. Internally, the job is prepared, started and executed on all members as shown below. The first member acts as the job owner (job emitter).
Member1 starts MapReduce job
Member1 emits key=Foo, value=1
Member1 does PartitionService::getKeyOwner(Foo) => results in Member3
Member2 emits key=Foo, value=14
Member2 asks jobOwner (Member1) for keyOwner of Foo => results in Member3
Member1 sends chunk for key=Foo to Member3
Member3 receives chunk for key=Foo and looks if there is already a Reducer,
if not creates one for key=Foo
Member3 processes chunk for key=Foo
Member2 sends chunk for key=Foo to Member3
Member3 receives chunk for key=Foo and looks if there is already a Reducer and uses
the previous one
Member3 processes chunk for key=Foo
Member1 send LastChunk information to Member3 because processing local values finished
Member2 emits key=Foo, value=27
Member2 has cached keyOwner of Foo => results in Member3
Member2 sends chunk for key=Foo to Member3
Member3 receives chunk for key=Foo and looks if there is already a Reducer and uses
the previous one
Member3 processes chunk for key=Foo
Member2 send LastChunk information to Member3 because processing local values finished
Member3 finishes reducing for key=Foo
Member1 registers its local partitions are processed
Member2 registers its local partitions are processed
Member1 sees all partitions processed and requests reducing from all members
Member1 merges all reduced results together in a final structure and returns itThe flow is quite complex but extremely powerful since everything is executed in parallel. Reducers do not wait until all values are emitted, but they immediately begin to reduce (when the first chunk for an emitted key arrives).
Internal MapReduce Packages
Beginning with the package level, there is one basic package: com.hazelcast.mapreduce.
This includes the external API and the impl package, which itself contains the
internal implementation.
-
The impl package contains all the default
KeyValueSourceimplementations and abstract base and support classes for the exposed API. -
The client package contains all classes that are needed on the client and member sides when a client offers a MapReduce job.
-
The notification package contains all "notification" or event classes that notify other members about progress on operations.
-
The operation package contains all operations that are used by the workers or job owner to coordinate work and sync partition or reducer processing.
-
The task package contains all classes that execute the actual MapReduce operation. It features the supervisor, mapping phase implementation and mapping/reducing tasks.
MapReduce Job Walk-Through
Now to the technical walk-through: A MapReduce Job is always retrieved from a
named JobTracker, which is implemented in NodeJobTracker (extends AbstractJobTracker)
and is configured using the configuration DSL. All of the internal implementation is
completely ICompletableFuture-driven and mostly non-blocking in design.
On submit, the Job creates a unique UUID which afterwards acts as a jobId and is combined with the JobTracker’s name to be uniquely identifiable inside the cluster. Then, the preparation is sent around the cluster and every member prepares its execution by creating a JobSupervisor, MapCombineTask and ReducerTask. The job-emitting JobSupervisor gains special capabilities to synchronize and control JobSupervisors on other members for the same job.
If preparation is finished on all members, the job itself is started by executing a StartProcessingJobOperation on every member. This initiates a MappingPhase implementation (defaults to KeyValueSourceMappingPhase) and starts the actual mapping on the members.
The mapping process is currently a single threaded operation per member, but will be extended to run in parallel on multiple partitions (configurable per Job) in future versions. The Mapper is now called on every available value on the partition and eventually emits values. For every emitted value, either a configured CombinerFactory is called to create a Combiner or a cached one is used (or the default CollectingCombinerFactory is used to create Combiners). When the chunk limit is reached on a member, a IntermediateChunkNotification is prepared by collecting emitted keys to their corresponding members. This is either done by asking the job owner to assign members or by an already cached assignment. In later versions, a PartitionStrategy might also be configurable.
The IntermediateChunkNotification is then sent to the reducers (containing only values for this member) and is offered to the ReducerTask. On every offer, the ReducerTask checks if it is already running and if not, it submits itself to the configured ExecutorService (from the JobTracker configuration).
If reducer queue runs out of work, the ReducerTask is removed from the ExecutorService to not block threads but eventually will be resubmitted on next chunk of work.
On every phase, the partition state is changed to keep track of the currently running
operations. A JobPartitionState can be in one of the following states with self-explanatory
titles: [WAITING, MAPPING, REDUCING, PROCESSED, CANCELLED]. If you have a deeper
interest of these states, look at the Javadoc.
-
Member asks for new partition to process: WAITING ⇒ MAPPING
-
Member emits first chunk to a reducer: MAPPING ⇒ REDUCING
-
All members signal that they finished mapping phase and reducing is finished, too: REDUCING ⇒ PROCESSED
Eventually, all JobPartitionStates reach the state of PROCESSED. Then, the job emitter’s JobSupervisor asks all members for their reduced results and executes a potentially offered Collator. With this Collator, the overall result is calculated before it removes itself from the JobTracker, doing some final cleanup and returning the result to the requester (using the internal TrackableJobFuture).
If a job is cancelled while execution, all partitions are immediately set to the CANCELLED state and a CancelJobSupervisorOperation is executed on all members to kill the running processes.
While the operation is running in addition to the default operations, some more operations like ProcessStatsUpdateOperation (updates processed records statistics) or NotifyRemoteExceptionOperation (notifies the members that the sending member encountered an unrecoverable situation and the Job needs to be cancelled, e.g., NullPointerException inside of a Mapper, are executed against the job owner to keep track of the process.
MapReduce Deprecation
This section informs Hazelcast users about the MapReduce deprecation, it’s motivation and replacements.
Motivation
We’ve decided to deprecate the MapReduce framework in Hazelcast IMDG 3.8. The MapReduce framework provided the distributed computing model and it was used to back the old Aggregations system. Unfortunately the implementation didn’t live up to the expectations and adoption wasn’t high, so it never got out of Beta status. Apart from that the current shift in development away from M/R-like processing to a more near-realtime, streaming approach left us with the decision to deprecate and finally remove the MapReduce framework from Hazelcast IMDG. With that said, we want to introduce the successors and replacements; Fast Aggregations on top of Query infrastructure and the Hazelcast Jet distributed computing platform.
Built-In Aggregations
MapReduce is a very powerful tool, however it’s demanding in terms of space, time and bandwidth. We realized that we don’t need so much power when we simply want to find out a simple metric such as the number of entries matching a predicate. Therefore, the built-in aggregations were rebuilt on top of the existing Query infrastructure (count, sum, min, max, mean, variance) which automatically leverages any matching query index. The aggregations are computed in tho phases:
-
1st phase: on each member (scatter)
-
2nd phase: one member aggregates responses from members (gather)
It is not as flexible as a full-blown M/R system due to the 2nd phase being single-member and the input can be massive in some use cases. The member doing the 2nd step needs enough capacity to hold all intermediate results from all members from the 1st step, but in practice it is sufficient for many aggregation tasks like "find average" or "find highest" and other common examples.
The benefits are:
-
improved performance
-
simplified API
-
utilization of existing indexes.
See the Fast-Aggregations section for examples. If you need a more powerful tool like MapReduce, then there is Hazelcast Jet!
Distributed Computation with Jet
Hazelcast Jet is the new distributed computing framework build on top of Hazelcast IMDG. It uses directed acyclic graphs (DAG) to model relationships between individual steps in the data processing pipeline. Conceptually speaking, the MapReduce model simply states that distributed computation on a large dataset can be boiled down to two kinds of computation steps - a map step and a reduce step. One pair of map and reduce does one level of aggregation over data. Complex computations typically require multiple such steps. Multiple M/R-steps essentially form a DAG of operations, so that a DAG execution model boils down to a generalization of the MapReduce model. Therefore it is always possible to rewrite a MapReduce application to Hazelcast Jet DAG or "pipeline of tasks" without conceptual changes.
The benefits can be summarized as follows:
-
MapReduce steps are completely isolated (by definition). With the whole computation modeled as a DAG, the Jet scheduler can optimize the operation pipeline
-
Hazelcast Jet provides a convenient high-level API (distributed j.u.stream). The code stays compact but also offers a more concrete API to leverage the full power of DAGs.
Moving MapReduce Tasks to Hazelcast Jet
We’ll use the example of the word count application which summarizes a set of documents into a mapping from each word to the total number of its occurrences in the documents. This involves both a mapping stage where one document is transformed into a stream of words and a reducing stage that performs a COUNT DISTINCT operation on the stream and populates a Hazelcast IMap with the results.
This is the word count code in MapReduce (also available on Hazelcast Jet Code Samples):
JobTracker t = hz.getJobTracker("word-count");
IMap<Long, String> documents = hz.getMap("documents");
LongSumAggregation<String, String> aggr = new LongSumAggregation<>();
Map<String, Long> counts =
t.newJob(KeyValueSource.fromMap(documents))
.mapper((Long x, String document, Context<String, Long> ctx) ->
Stream.of(document.toLowerCase().split("\\W+"))
.filter(w -> !w.isEmpty())
.forEach(w -> ctx.emit(w, 1L)))
.combiner(aggr.getCombinerFactory())
.reducer(aggr.getReducerFactory())
.submit()
.get();Jet’s Core API is strictly lower-level than MapReduce’s because it can
be used to build the entire infrastructure that can drive MapReduce’s
mapper, combiner and reducer, fully preserving the semantics of the MapReduce
job. However, this approach to migrating your code to Jet is not a good option
because the MapReduce API enforces a quite suboptimal computation model.
The simplest approach is implementing the job in terms of Jet’s
java.util.stream support (Jet JUS for short):
IStreamMap<String, String> documents = jet.getMap("documents");
IMap<String, Long> counts = documents
.stream()
.flatMap(m -> Stream.of(m.getValue().toLowerCase().split("\\W+"))
.filter(w -> !w.isEmpty()))
.collect(DistributedCollectors.toIMap(w -> w, w -> 1L, (left, right) -> left + right));This can be taken as a general template to express a MapReduce job in terms
of Jet JUS: the logic of the mapper is inside flatMap and the logic of
both the combiner and the reducer is inside collect. Jet automatically applies
the optimization where the data stream is first "combined" locally on each member,
then the partial results "reduced" in the final step, after sending across the network.
Keep in mind that MapReduce and JUS use the same terminology, but with quite different meaning: in JUS the final step is called "combine" (MapReduce calls it "reduce") and the middle step is called "reduce" (MapReduce calls this one "combine"). MapReduce’s "combine" collapses the stream in fixed-size batches, whereas in Jet JUS "reduce" collapses the complete local dataset and sends just a single item per distinct key to the final step. In Jet JUS, the final "combine" step combines just one partial result per member into the total result, whereas in MapReduce the final step "reduces" all the one-per-batch items to the final result. Therefore, in Jet there are only O (distinct-key-count) items sent over the network whereas in MapReduce it is still O (total-item-count) with just a linear scaling factor equal to the configured batch size.
A complete example of the word count done with the Streams API can be found in the Hazelcast Jet Code Samples A minor difference is that the code on GitHub stores the documents line by line, with the effect of a finer-grained distribution across the cluster.
To better understand how the JUS pipeline is executed by Jet, take a look at the file
WordCount.java in the core/wordcount module, which builds the same DAG as the Jet
JUS implementation, but using the Jet Core API. Here is a somewhat simplified DAG from
this example:
DAG dag = new DAG();
Vertex source = dag.newVertex("source", Processors.readMap("documents"))
.localParallelism(1);
Vertex map = dag.newVertex("map", Processors.flatMap(
(String document) -> traverseArray(document.split("\\W+"))));
Vertex reduce = dag.newVertex("reduce", Processors.groupAndAccumulate(
() -> 0L, (count, x) -> count + 1));
Vertex combine = dag.newVertex("combine", Processors.groupAndAccumulate(
Entry::getKey,
() -> 0L,
(Long count, Entry<String, Long> wordAndCount) ->
count + wordAndCount.getValue())
);
Vertex sink = dag.newVertex("sink", writeMap("counts"));
dag.edge(between(source, map))
.edge(between(map, reduce).partitioned(wholeItem(), HASH_CODE))
.edge(between(reduce, combine).partitioned(entryKey()).distributed())
.edge(between(combine, sink));It is a simple cascade of vertices: source → map → reduce → combine → sink and
matches quite closely the workflow of a MapReduce job. On each member, a distinct
slice of data (IMap partitions stored locally) is ingested by the source vertex
and sent to map on the local member. The output of map are words and they travel
over a partitioned edge to reduce. Note that, as opposed to MapReduce, a single
instance of a processor doesn’t count occurrences of just one word, but is responsible
for entire partitions. There are only as many processors as configured by the
localParallelism property. This is one of several examples where Jet’s DAG
exposes performance-critical attributes of the computation to the user.
Another example of this can be seen in arguments passed to partitioned(wholeItem(), HASH_CODE).
The user has a precise control over the partitioning key as well as the algorithm used
to map the key to a partition ID. In this case we use the whole item (the word) as the
key and apply the fast HASH_CODE strategy, which derives the partition ID from the
object’s hashCode().
The reduce → combine edge is both partitioned and distributed. Whereas each cluster
member has its own reduce processor for any given word, there is only one combine
processor in the entire cluster for a given word. This is where network traffic happens:
reduce sends its local results for a word to that one combine processor in the cluster.
Note that here we didn’t specify HASH_CODE; it is not guaranteed to be safe on a
distributed edge because on the target member the hashcode can come out differently.
For many value classes (like String and Integer) it is guaranteed to work, though,
because their hashcode explicitly specifies the function used. By default Jet applies the
slower but safer Hazelcast strategy: first serialize and then compute the MurmurHash3 of
the resulting blob. It is up to the user to ensure that the faster strategy is safe, or to
provide a custom strategy.
In the above example we can see many out-of-the-box processors being used:
-
readMapto ingest the data from an IMap -
flatMapto perform a flat-map operation on incoming items (closely corresponds to MapReduce’s mapper) -
groupAndAccumulateto perform the reduction and combining
There are some more in the Processors class.
For even more flexibility we’ll now show how you can implement a processor on your
own (also available in the Hazelcast Jet Code Samples repository):
public class MapReduce {
public static void main(String[] args) throws Exception {
Jet.newJetInstance();
JetInstance jet = Jet.newJetInstance();
try {
DAG dag = new DAG();
Vertex source = dag.newVertex("source", readMap("sourceMap"));
Vertex map = dag.newVertex("map", MapP::new);
Vertex reduce = dag.newVertex("reduce", ReduceP::new);
Vertex combine = dag.newVertex("combine", CombineP::new);
Vertex sink = dag.newVertex("sink", writeMap("sinkMap"));
dag.edge(between(source, map))
.edge(between(map, reduce).partitioned(wholeItem(), HASH_CODE))
.edge(between(reduce, combine).partitioned(entryKey()).distributed())
.edge(between(combine, sink.localParallelism(1)));
jet.newJob(dag).execute().get();
} finally {
Jet.shutdownAll();
}
}
private static class MapP extends AbstractProcessor {
private final FlatMapper<Entry<Long, String>, String> flatMapper = flatMapper(
(Entry<Long, String> e) -> new WordTraverser(e.getValue())
);
@Override
protected boolean tryProcess0(@Nonnull Object item) {
return flatMapper.tryProcess((Entry<Long, String>) item);
}
}
private static class WordTraverser implements Traverser<String> {
private final StringTokenizer tokenizer;
WordTraverser(String document) {
this.tokenizer = new StringTokenizer(document.toLowerCase());
}
@Override
public String next() {
return tokenizer.hasMoreTokens() ? tokenizer.nextToken() : null;
}
}
private static class ReduceP extends AbstractProcessor {
private final Map<String, Long> wordToCount = new HashMap<>();
private final Traverser<Entry<String, Long>> resultTraverser =
lazy(() -> traverseIterable(wordToCount.entrySet()));
@Override
protected boolean tryProcess0(@Nonnull Object item) {
wordToCount.compute((String) item, (x, count) -> 1 + (count != null ? count : 0L));
return true;
}
@Override
public boolean complete() {
return emitCooperatively(resultTraverser);
}
}
private static class CombineP extends AbstractProcessor {
private final Map<String, Long> wordToCount = new HashMap<>();
private final Traverser<Entry<String, Long>> resultTraverser =
lazy(() -> traverseIterable(wordToCount.entrySet()));
@Override
protected boolean tryProcess0(@Nonnull Object item) {
final Entry<String, Long> e = (Entry<String, Long>) item;
wordToCount.compute(e.getKey(),
(x, count) -> e.getValue() + (count != null ? count : 0L));
return true;
}
@Override
public boolean complete() {
return emitCooperatively(resultTraverser);
}
}
}One of the challenges of implementing a custom processor is cooperativeness: it must
back off as soon as there is no more room in the output buffer (the outbox). This
example shows how to make use of another line of convenience provided at this lower
level, which takes care of almost all the mechanics involved. One gotcha is that a
simple for loop must be converted to a stateful iterator-style object, like
WordTraverser in the above code. To make this conversion as painless as possible we
chose to not require a Java Iterator, but defined our own Traverser interface with
just a single method to implement. This means that Traverser is a functional
interface and can often be implemented with a one-liner lambda.
Jet Compared with New Aggregations
Hazelcast has native support for aggregation operations on the contents of its distributed data structures. They operate on the assumption that the aggregating function is commutative and associative, which allows the two-tiered approach where first the local data is aggregated, then all the local subresults sent to one member, where they are combined and returned to the user. This approach works quite well as long as the result is of manageable size. Many interesting aggregations produce an O(1) result and for those, the native aggregations are a good match.
The main area where native aggregations may not be sufficient are the operations that
group the data by key and produce results of size O (keyCount). The architecture of
Hazelcast aggregations is not well adapted to this use case, although it still works
even for moderately-sized results (up to 100 MB, as a ballpark figure). Beyond these
numbers, and whenever something more than a single aggregation step is needed, Jet
becomes the preferred choice. In the mentioned use case Jet helps because it doesn’t
send the entire hashtables in serialized form and materialize all the results on the
user’s machine, but rather streams the key-value pairs directly into a target IMap.
Since it is a distributed structure, it doesn’t focus its load on a single member.
Jet’s DAG paradigm offers much more than the basic map-reduce-combine cascade. Among other setups, it can compose several such cascades and also perform co-grouping, joining and many other operations in complex combinations.