Hazelcast is an open source In-Memory Data Grid (IMDG). It provides elastically scalable distributed In-Memory computing, widely recognized as the fastest and most scalable approach to application performance. Hazelcast does this in open source. More importantly, Hazelcast makes distributed computing simple by offering distributed implementations of many developer-friendly interfaces from Java such as Map, Queue, ExecutorService, Lock and JCache. For example, the Map interface provides an In-Memory Key Value store which confers many of the advantages of NoSQL in terms of developer friendliness and developer productivity.
In addition to distributing data In-Memory, Hazelcast provides a convenient set of APIs to access the CPUs in your cluster for maximum processing speed. Hazelcast is designed to be lightweight and easy to use. Since Hazelcast is delivered as a compact library (JAR) and since it has no external dependencies other than Java, it easily plugs into your software solution and provides distributed data structures and distributed computing utilities.
Hazelcast is highly scalable and available. Distributed applications can use Hazelcast for distributed caching, synchronization, clustering, processing, pub/sub messaging, etc. Hazelcast is implemented in Java and has clients for Java, C/C++, .NET, REST, Python, Go and Node.js. Hazelcast also speaks Memcached protocol. It plugs into Hibernate and can easily be used with any existing database system.
If you are looking for in-memory speed, elastic scalability and the developer friendliness of NoSQL, Hazelcast is a great choice.
Hazelcast is Simple
Hazelcast is written in Java with no other dependencies. It exposes the same API from the familiar Java util package,
exposing the same interfaces. Just add hazelcast.jar to your classpath and you can quickly enjoy JVMs clustering
and start building scalable applications.
Hazelcast is Peer-to-Peer
Unlike many NoSQL solutions, Hazelcast is peer-to-peer. There is no master and slave; there is no single point of failure. All members store equal amounts of data and do equal amounts of processing. You can embed Hazelcast in your existing application or use it in client and server mode where your application is a client to Hazelcast members.
Hazelcast is Scalable
Hazelcast is designed to scale up to hundreds and thousands of members. Simply add new members; they automatically discover the cluster and linearly increase both the memory and processing capacity. The members maintain a TCP connection between each other and all communication is performed through this layer.
Hazelcast is Fast
Hazelcast stores everything in-memory. It is designed to perform very fast reads and updates.
Hazelcast is Redundant
Hazelcast keeps the backup of each data entry on multiple members. On a member failure, the data is restored from the backup and the cluster continues to operate without downtime.
Sharding in Hazelcast
Hazelcast shards are called Partitions. By default, Hazelcast has 271 partitions. Given a key, we serialize, hash and mod it with the number of partitions to find the partition which the key belongs to. The partitions themselves are distributed equally among the members of the cluster. Hazelcast also creates the backups of partitions and distributes them among members for redundancy.
| See the Data Partitioning section for more information on how Hazelcast partitions your data. |
Hazelcast Topology
You can deploy a Hazelcast cluster in two ways: Embedded or Client/Server.
If you have an application whose main focal point is asynchronous or high performance computing and lots of task executions, then Embedded deployment is the preferred way. In Embedded deployment, members include both the application and Hazelcast data and services. The advantage of the Embedded deployment is having a low-latency data access.
See the below illustration.
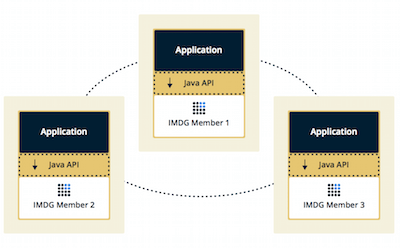
In the Client/Server deployment, Hazelcast data and services are centralized in one or more server members and they are accessed by the application through clients. You can have a cluster of server members that can be independently created and scaled. Your clients communicate with these members to reach to Hazelcast data and services on them.
See the below illustration.
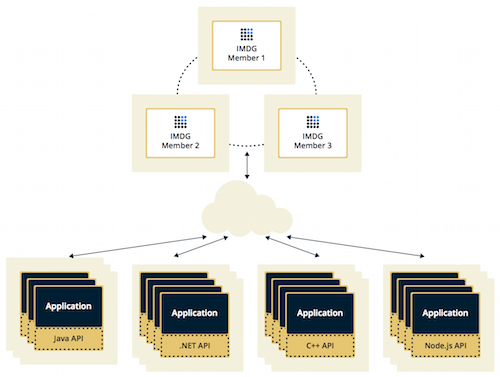
Hazelcast provides native clients (Java, .NET and C++), Memcache and REST clients, Scala, Python and Node.js client implementations.
Client/Server deployment has advantages including more predictable and reliable Hazelcast performance, easier identification of problem causes and, most importantly, better scalability. When you need to scale in this deployment type, just add more Hazelcast server members. You can address client and server scalability concerns separately.
Note that Hazelcast member libraries are available only in Java. Therefore, embedding a member to a business service, it is only possible with Java. Applications written in other languages (.NET, C++, Node.js, etc.) can use Hazelcast client libraries to access the cluster. See the Hazelcast Clients chapter for information on the clients and other language implementations.
If you want low-latency data access, as in the Embedded deployment, and you also want the scalability advantages of the Client/Server deployment, you can consider defining Near Caches for your clients. This enables the frequently used data to be kept in the client’s local memory. See the Configuring Client Near Cache section.
Why Hazelcast?
A Glance at Traditional Data Persistence
Data is at the core of software systems. In conventional architectures, a relational database persists and provides access to data. Applications are talking directly with a database which has its backup as another machine. To increase performance, tuning or a faster machine is required. This can cost a large amount of money or effort.
There is also the idea of keeping copies of data next to the database, which is performed using technologies like external key-value stores or second level caching that help offload the database. However, when the database is saturated or the applications perform mostly "put" operations (writes), this approach is of no use because it insulates the database only from the "get" loads (reads). Even if the applications are read-intensive there can be consistency problems - when data changes, what happens to the cache and how are the changes handled? This is when concepts like time-to-live (TTL) or write-through come in.
In the case of TTL, if the access is less frequent than the TTL, the result is always a cache miss. On the other hand, in the case of write-through caches, if there are more than one of these caches in a cluster, it means there are consistency issues. This can be avoided by having the members communicate with each other so that entry invalidations can be propagated.
We can conclude that an ideal cache would combine TTL and write-through features. There are several cache servers and in-memory database solutions in this field. However, these are stand-alone single instances with a distribution mechanism that is provided by other technologies to an extent. So, we are back to square one; we experience saturation or capacity issues if the product is a single instance or if consistency is not provided by the distribution.
And, there is Hazelcast
Hazelcast, a brand new approach to data, is designed around the concept of distribution. Hazelcast shares data around the cluster for flexibility and performance. It is an in-memory data grid for clustering and highly scalable data distribution.
One of the main features of Hazelcast is that it does not have a master member. Each cluster member is configured to be the same in terms of functionality. The oldest member (the first member created in the cluster) automatically performs the data assignment to cluster members. If the oldest member dies, the second oldest member takes over.
| You can come across with the term "master" or "master member" in some sections of this manual. They are used for contextual clarification purposes; please remember that they refer to the "oldest member" which is explained in the above paragraph. |
Another main feature of Hazelcast is that the data is held entirely in-memory. This is fast. In the case of a failure, such as a member crash, no data is lost since Hazelcast distributes copies of the data across all the cluster members.
As shown in the feature list in the Distributed Data Structures chapter, Hazelcast supports a number of distributed data structures and distributed computing utilities. These provide powerful ways of accessing distributed clustered memory and accessing CPUs for true distributed computing.
Hazelcast’s Distinctive Strengths
-
Hazelcast is open source.
-
Hazelcast is only a JAR file. You do not need to install software.
-
Hazelcast is a library, it does not impose an architecture on Hazelcast users.
-
Hazelcast provides out-of-the-box distributed data structures, such as Map, Queue, MultiMap, Topic, Lock and Executor.
-
There is no "master," meaning no single point of failure in a Hazelcast cluster; each member in the cluster is configured to be functionally the same.
-
When the size of your memory and compute requirements increase, new members can be dynamically joined to the Hazelcast cluster to scale elastically.
-
Data is resilient to member failure. Data backups are distributed across the cluster. This is a big benefit when a member in the cluster crashes as data is not lost.
-
Members are always aware of each other unlike in traditional key-value caching solutions.
-
You can build your own custom-distributed data structures using the Service Programming Interface (SPI) if you are not happy with the data structures provided.
Finally, Hazelcast has a vibrant open source community enabling it to be continuously developed.
Hazelcast is a fit when you need:
-
analytic applications requiring big data processing by partitioning the data
-
to retain frequently accessed data in the grid
-
a cache, particularly an open source JCache provider with elastic distributed scalability
-
a primary data store for applications with utmost performance, scalability and low-latency requirements
-
an In-Memory NoSQL Key Value Store
-
publish/subscribe communication at highest speed and scalability between applications
-
applications that need to scale elastically in distributed and cloud environments
-
a highly available distributed cache for applications
-
an alternative to Coherence and Terracotta.
Data Partitioning
As you read in the Sharding in Hazelcast section, Hazelcast shards are called Partitions. Partitions are memory segments that can contain hundreds or thousands of data entries each, depending on the memory capacity of your system. Each Hazelcast partition can have multiple replicas, which are distributed among the cluster members. One of the replicas becomes the primary and other replicas are called backups. Cluster member which owns primary replica of a partition is called partition owner. When you read or write a particular data entry, you transparently talk to the owner of the partition that contains the data entry.
By default, Hazelcast offers 271 partitions. When you start a cluster with a single member, it owns all of 271 partitions (i.e., it keeps primary replicas for 271 partitions). The following illustration shows the partitions in a Hazelcast cluster with single member.

When you start a second member on that cluster (creating a Hazelcast cluster with two members), the partition replicas are distributed as shown in the illustration here.
| Partition distributions in the below illustrations are shown for the sake of simplicity and for descriptive purposes. Normally, the partitions are not distributed in any order, as they are shown in these illustrations, but are distributed randomly (they do not have to be sequentially distributed to each member). The important point here is that Hazelcast equally distributes the partition primaries and their backup replicas among the members. |
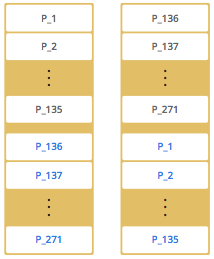
In the illustration, the partition replicas with black text are primaries and the partition replicas with blue text are backups. The first member has primary replicas of 135 partitions (black) and each of these partitions are backed up in the second member (i.e., the second member owns the backup replicas) (blue). At the same time, the first member also has the backup replicas of the second member’s primary partition replicas.
As you add more members, Hazelcast moves some of the primary and backup partition replicas to the new members one by one, making all members equal and redundant. Thanks to the consistent hashing algorithm, only the minimum amount of partitions are moved to scale out Hazelcast. The following is an illustration of the partition replica distributions in a Hazelcast cluster with four members.
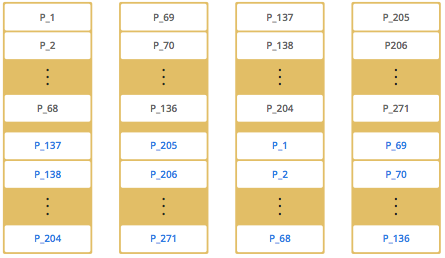
Hazelcast distributes partitions' primary and backup replicas equally among the members of the cluster. Backup replicas of the partitions are maintained for redundancy.
| Your data can have multiple copies on partition primaries and backups, depending on your backup count. See the Backing Up Maps section. |
Hazelcast also offers lite members. These members do not own any partition. Lite members are intended for use in computationally-heavy task executions and listener registrations. Although they do not own any partitions, they can access partitions that are owned by other members in the cluster.
| See the Enabling Lite Members section. |
How the Data is Partitioned
Hazelcast distributes data entries into the partitions using a hashing algorithm. Given an object key (for example, for a map) or an object name (for example, for a topic or list):
-
the key or name is serialized (converted into a byte array)
-
this byte array is hashed
-
the result of the hash is mod by the number of partitions.
The result of this modulo - MOD(hash result, partition count) - is the partition in which the data will be stored, that is the partition ID. For ALL members you have in your cluster, the partition ID for a given key is always the same.
Partition Table
When you start a member, a partition table is created within it. This table stores the partition IDs and the cluster members to which they belong. The purpose of this table is to make all members (including lite members) in the cluster aware of this information, making sure that each member knows where the data is.
The oldest member in the cluster (the one that started first) periodically sends the partition table to all members. In this way each member in the cluster is informed about any changes to partition ownership. The ownerships may be changed when, for example, a new member joins the cluster, or when a member leaves the cluster.
| If the oldest member of the cluster goes down, the next oldest member sends the partition table information to the other ones. |
You can configure the frequency (how often) that the member sends the partition table the information by using the hazelcast.partition.table.send.interval system property. The property is set to every 15 seconds by default.
Repartitioning
Repartitioning is the process of redistribution of partition ownerships. Hazelcast performs the repartitioning when a member joins or leaves the cluster.
In these cases, the partition table in the oldest member is updated with the new partition ownerships. Note that if a lite member joins or leaves a cluster, repartitioning is not triggered since lite members do not own any partitions.
Use Cases
Hazelcast can be used:
-
to share server configuration/information to see how a cluster performs
-
to cluster highly changing data with event notifications, e.g., user based events, and to queue and distribute background tasks
-
as a simple Memcache with Near Cache
-
as a cloud-wide scheduler of certain processes that need to be performed on some members
-
to share information (user information, queues, maps, etc.) on the fly with multiple members in different installations under OSGI environments
-
to share thousands of keys in a cluster where there is a web service interface on an application server and some validation
-
as a distributed topic (publish/subscribe server) to build scalable chat servers for smartphones
-
as a front layer for a Cassandra back-end
-
to distribute user object states across the cluster, to pass messages between objects and to share system data structures (static initialization state, mirrored objects, object identity generators)
-
as a multi-tenancy cache where each tenant has its own map
-
to share datasets, e.g., table-like data structure, to be used by applications
-
to distribute the load and collect status from Amazon EC2 servers where the front-end is developed using, for example, Spring framework
-
as a real-time streamer for performance detection
-
as storage for session data in web applications (enables horizontal scalability of the web application).
Resources
-
Hazelcast source code can be found at Github/Hazelcast.
-
Hazelcast API can be found at hazelcast.org/docs/Javadoc.
-
Code samples can be downloaded from hazelcast.org/download.
-
More use cases and resources can be found at hazelcast.com.
-
Questions and discussions can be posted at the Hazelcast mail group.