Hazelcast IMDG Pro Feature
This chapter explains Hazelcast’s Hot Restart Persistence feature. It provides fast cluster restarts by storing the states of the cluster members on the disk. This feature is currently provided for the Hazelcast map data structure and Hazelcast JCache implementation.
Hot Restart Persistence Overview
Hot Restart Persistence enables you to get your cluster up and running swiftly after a cluster restart. A restart can be caused by a planned shutdown (including rolling upgrades) or a sudden cluster-wide crash, e.g., power outage. For Hot Restart Persistence, required states for Hazelcast clusters and members are introduced. See the Managing Cluster and Member States section for information on the cluster and member states. The purpose of the Hot Restart Persistence is to provide a maintenance window for member operations and restart the cluster in a fast way. It is not meant to recover the catastrophic shutdown of one member.
Hot Restart Persistence supports optional data encryption. See the Encryption at Rest section for more information.
Hot Restart Types
The Hot Restart feature is supported for the following restart types:
-
Restart after a planned shutdown:
-
The cluster is shut down completely and restarted with the exact same previous setup and data.
You can shut down the cluster completely using the
HazelcastInstance.getCluster().shutdown()method or you can manually change the cluster state toPASSIVEand then shut down each member one by one. When you send the command to shut the cluster down, i.e.,HazelcastInstance.getCluster().shutdown(), the members that are not in thePASSIVEstate temporarily change their states toPASSIVE. Then, each member shuts itself down by calling the methodHazelcastInstance.shutdown().Difference between explicitly changing state to
PASSIVEbefore shutdown and shutting down cluster directly viaHazelcastInstance.getCluster().shutdown()is, on the latter case when cluster is restarted, the cluster state will be in the latest state before shutdown. That means if cluster isACTIVEbefore shutdown, cluster state automatically becomesACTIVEafter restart is completed. -
Rolling restart: The cluster is restarted intentionally member by member. For example, this could be done to install an operating system patch or new hardware.
To be able to shut down the cluster member by member as part of a planned restart, each member in the cluster should be in the
FROZENorPASSIVEstate. After the cluster state is changed toFROZENorPASSIVE, you can manually shut down each member by calling the methodHazelcastInstance.shutdown(). When that member is restarted, it rejoins the running cluster. After all members are restarted, the cluster state can be changed back toACTIVE.
-
-
Restart after a cluster crash: The cluster is restarted after all its members crashed at the same time due to a power outage, networking interruptions, etc.
Restart Process
During the restart process, each member waits to load data until all the members in the
partition table are started. During this process, no operations are allowed. Once all
cluster members are started, Hazelcast changes the cluster state to PASSIVE and starts
to load data. When all data is loaded, Hazelcast changes the cluster state to its previous
known state before shutdown and starts to accept the operations which are allowed by the
restored cluster state.
If a member fails to either start, join the cluster in time (within the timeout), or load its data, then that member is terminated immediately. After the problems causing the failure are fixed, that member can be restarted. If the cluster start cannot be completed in time, then all members fail to start. See the Configuring Hot Restart section for defining timeouts.
In the case of a restart after a cluster crash, the Hot Restart feature realizes that it was not a clean shutdown and Hazelcast tries to restart the cluster with the last saved data following the process explained above. In some cases, specifically when the cluster crashes while it has an ongoing partition migration process, currently it is not possible to restore the last saved state.
Restart of a Member in Running Cluster
Assume the following:
-
You have a cluster consisting of members A, B and C with Hot Restart enabled, which is initially stable.
-
Member B is killed.
-
Member B restarts.
Since only a single member has failed, the cluster performed the standard High Availability routine by recovering member B’s data from backups and redistributing the data among the remaining members (the members A and C in this case). Member B’s persisted Hot Restart data is completely irrelevant.
Furthermore, when a member starts with existing Hot Restart data,
it expects to find itself within a cluster that has been shut down
as a whole and is now restarting as a whole. Since the reality is that
the cluster has been running all along, member B’s persisted cluster state
does not match the actual state. Depending on the automatic removal of stale data (auto-remove-stale-data) configuration:
-
If
auto-remove-stale-datais enabled, member B automatically deletes its Hot Restart directory inside the base directory (base-dir) and starts as a fresh, empty member. The cluster assigns some partitions to it, unrelated to the partitions it owned before going down. -
Otherwise, member B aborts the initialization and shuts down. To be able to join the cluster, Hot Restart directory previously used by member B inside the base directory (
base-dir) must be deleted manually.
Force Start
A member can crash permanently and then be unable to recover from the failure. In that case, restart process cannot be completed since some of the members do not start or fail to load their own data. In that case, you can force the cluster to clean its persisted data and make a fresh start. This process is called force start.
Assume the following which is a valid scenario to use force start:
-
You have a cluster consisting of members A and B which is initially stable.
-
Cluster transitions into
FROZENorPASSIVEstate. -
Cluster gracefully shuts down.
-
Member A restarts, but member B does not.
-
Member A uses its Hot Restart data to initiate the Hot Restart procedure.
-
Since it knows the cluster originally contained member B as well, it waits for it to join.
-
This never happens.
-
Now you have the choice to Force Start the cluster without member B.
-
Cluster discards all Hot Restart data and starts empty.
You can trigger the force start process using the Management Center, REST API and cluster management scripts.
Please note that force start is a destructive process, which results in deletion of persisted Hot Restart data.
See the Hot Restart functionality^ of the Management Center section to learn how you can perform a force start using the Management Center.
Partial Start
When one or more members fail to start or have incorrect Hot Restart data (stale or corrupted data) or fail to load their Hot Restart data, cluster becomes incomplete and restart mechanism cannot proceed. One solution is to use Force Start and make a fresh start with existing members. Another solution is to do a partial start.
Partial start means that the cluster starts with an incomplete member set. Data belonging to those missing members is assumed lost and Hazelcast tries to recover missing data using the restored backups. For example, if you have minimum two backups configured for all maps and caches, then a partial start up to two missing members will be safe against data loss. If there are more than two missing members or there are maps/caches with less than two backups, then data loss is expected.
Partial start is controlled by cluster-data-recovery-policy configuration
parameter and is not allowed by default. To enable partial start, one of the
configuration values PARTIAL_RECOVERY_MOST_RECENT or PARTIAL_RECOVERY_MOST_COMPLETE
should be set. See the Configuring Hot Restart section
for details.
When partial start is enabled, Hazelcast can perform a partial start
automatically or manually, in case of some members are unable to restart
successfully. Partial start proceeds automatically when some members fail to
start and join to the cluster in validation-timeout-seconds. After the
validation-timeout-seconds duration is passed, Hot Restart chooses to perform
partial start with the members present in the cluster. Moreover, partial start can
be requested manually using the
Management Center,
REST API and cluster management scripts
before the validation-timeout-seconds duration passes.
The other situation to decide to perform a partial start is failures during
the data load phase. When Hazelcast learns data load result of all members which
have passed the validation step, it automatically performs a partial start with
the ones which have successfully restored their Hot Restart data. Please note that
partial start does not expect every member to succeed in the data load step.
It completes the process when it learns data load result for every member and
there is at least one member which has successfully restored its Hot Restart data.
Relatedly, if it cannot learn data load result of all members before data-load-timeout-seconds
duration, it proceeds with the ones which have already completed the data load process.
Selection of members to perform partial start among live members is done
according to the cluster-data-recovery-policy configuration.
Set of members which are not selected by the cluster-data-recovery-policy
are called Excluded members and they are instructed to perform force start.
Excluded members are allowed to join cluster only when they clean their
Hot Restart data and make a fresh-new start. This is a completely automatic
process. For instance, if you start the missing members after partial start
is completed, they clean their Hot Restart data and join to the cluster.
Please note that partial start is a destructive process. Once it is completed,
it cannot be repeated with a new configuration. For this reason, one may need
to perform the partial start process manually. Automatic behavior of partial start
relies on validation-timeout-seconds and data-load-timeout-seconds configuration
values. If you need to control the process manually, validation-timeout-seconds and
data-load-timeout-seconds properties can be set to very big values so that
Hazelcast cannot make progress on timeouts automatically. Then, the overall
process can be managed manually via aforementioned methods, i.e.,
Management Center, REST API and cluster management scripts.
Configuring Hot Restart
You can configure Hot Restart feature programmatically or declaratively. There are two steps of configuration:
-
Enabling and configuring the Hot Restart feature globally in your Hazelcast configuration: This is done using the configuration element
hot-restart-persistence. See the Global Hot Restart Configuration section below. -
Enabling and configuring the Hazelcast data structures to use the Hot Restart feature: This is done using the configuration element
hot-restart. See the Per Data Structure Hot Restart Configuration section below.
Global Hot Restart Configuration
This is where you configure the Hot Restart feature itself using the
hot-restart-persistence element. The following are the descriptions of its attribute and sub-elements:
-
enabled: Attribute of thehot-restart-persistenceelement which specifies whether the feature is globally enabled in your Hazelcast configuration. Set this attribute totrueif you want any of your data structures to use the Hot Restart feature. -
base-dir: Specifies the parent directory where the Hot Restart data is stored. The default value forbase-dirishot-restart. You can use the default value, or you can specify the value of another folder containing the Hot Restart configuration, but it is mandatory thatbase-direlement has a value. This directory is created automatically if it does not exist.base-diris used as the parent directory, and a unique Hot Restart directory is created insidebase-dirfor each Hazelcast member which uses the samebase-dir. That means,base-dircan be shared among multiple Hazelcast members safely. This is especially useful for cloud environments where the members generally use a shared filesystem.When a Hazelcast member starts, it tries to acquire the ownership of the first available Hot Restart directory inside the
base-dir. Ifbase-diris empty or if the starting member fails to acquire the ownership of any directory (happens when all the directories are already acquired by other Hazelcast members), then it creates its own fresh directory.Previously, base-dirwas being used only by a single Hazelcast member. If such an existingbase-diris configured for a Hazelcast member, Hot Restart starts in legacy mode andbase-diris used only by a single member, without creating a unique sub-directory. Other members trying to use thatbase-dirfails during the startup. -
backup-dir: Specifies the directory under which Hot Restart snapshots (Hot Backups) are stored. See the Hot Backup section for more information. -
parallelism: Level of parallelism in Hot Restart Persistence. There are this many I/O threads, each writing in parallel to its own files. During the Hot Restart procedure, this many I/O threads are reading the files and this many rebuilder threads are rebuilding the Hot Restart metadata. The default value for this property is 1. This is a good default in most but not all cases. You should measure the raw I/O throughput of your infrastructure and test with different values of parallelism. In some cases such as dedicated hardware higher parallelism can yield more throughput of Hot Restart. In other cases such as running on EC2, it can yield diminishing returns - more thread scheduling, more contention on I/O and less efficient garbage collection. -
validation-timeout-seconds: Validation timeout for the Hot Restart process when validating the cluster members expected to join and the partition table on the whole cluster. -
data-load-timeout-seconds: Data load timeout for the Hot Restart process. All members in the cluster should finish restoring their local data before this timeout. -
cluster-data-recovery-policy: Specifies the data recovery policy that is respected during the Hot Restart cluster start. Valid values are;-
FULL_RECOVERY_ONLY: Starts the cluster only when all expected members are present and correct. Otherwise, it fails. This is the default value. -
PARTIAL_RECOVERY_MOST_RECENT: Starts the cluster with the members which have most up-to-date partition table and successfully restored their data. All other members leave the cluster and force start themselves. If no member restores its data successfully, cluster start fails. -
PARTIAL_RECOVERY_MOST_COMPLETE: Starts the cluster with the largest group of members which have the same partition table version and successfully restored their data. All other members leave the cluster and force start themselves. If no member restores its data successfully, cluster start fails.
-
-
auto-remove-stale-data: Enables automatic removal of the stale Hot Restart data. When a member terminates or crashes when the cluster state isACTIVE, the remaining members redistribute the data among themselves and the data persisted on terminated member’s storage becomes stale. That terminated member cannot rejoin the cluster without removing Hot Restart data. When auto-removal of stale Hot Restart data is enabled, while restarting that member, Hot Restart data is automatically removed and it joins the cluster as a completely new member. Otherwise, Hot Restart data should be removed manually. -
encryption-at-rest: Configures encryption on the Hot Restart data level. See the Encryption at Rest section for more information.
Per Data Structure Hot Restart Configuration
This is where you configure the data structures of your choice, so that they can
have the Hot Restart feature. This is done using the hot-restart configuration
element. As it is explained in the introduction
paragraph, Hot Restart feature is currently supported by Hazelcast map data
structure and JCache implementation (map and cache), each of which has the
hot-restart configuration element. The following are the descriptions of this
element’s attribute and sub-element:
-
enabled: Attribute of thehot-restartelement which specifies whether the Hot Restart feature is enabled for the related data structure. Its default value isfalse. -
fsync: Turning onfsyncguarantees that data is persisted to the disk device when a write operation returns successful response to the caller. By default,fsyncis turned off (false). That means data is persisted to the disk device eventually, instead of on every disk write. This generally provides a better performance.
Hot Restart Configuration Examples
The following are example configurations for a Hazelcast map and JCache implementation.
Declarative Configuration:
An example configuration is shown below.
<hazelcast>
...
<hot-restart-persistence enabled="true">
<base-dir>/mnt/hot-restart</base-dir>
<backup-dir>/mnt/hot-backup</backup-dir>
<validation-timeout-seconds>120</validation-timeout-seconds>
<data-load-timeout-seconds>900</data-load-timeout-seconds>
<cluster-data-recovery-policy>FULL_RECOVERY_ONLY</cluster-data-recovery-policy>
</hot-restart-persistence>
...
<map name="test-map">
<hot-restart enabled="true">
<fsync>false</fsync>
</hot-restart>
</map>
...
<cache name="test-cache">
<hot-restart enabled="true">
<fsync>false</fsync>
</hot-restart>
</cache>
...
</hazelcast>hazelcast:
hot-restart-persistence:
enabled: true
base-dir: /mnt/hot-restart
backup-dir: /mnt/hot-backup
validation-timeout-seconds: 120
data-load-timeout-seconds: 900
cluster-data-recovery-policy: FULL_RECOVERY_ONLY
map:
test-map:
hot-restart:
enabled: true
fsync: false
cache:
test-cache:
hot-restart:
enabled: true
fsync: falseProgrammatic Configuration:
The programmatic equivalent of the above declarative configuration is shown below.
Config config = new Config();
HotRestartPersistenceConfig hotRestartPersistenceConfig = new HotRestartPersistenceConfig()
.setEnabled(true)
.setBaseDir(new File("/mnt/hot-restart"))
.setParallelism(1)
.setValidationTimeoutSeconds(120)
.setDataLoadTimeoutSeconds(900)
.setClusterDataRecoveryPolicy(HotRestartClusterDataRecoveryPolicy.FULL_RECOVERY_ONLY)
.setAutoRemoveStaleData(true);
config.setHotRestartPersistenceConfig(hotRestartPersistenceConfig);
MapConfig mapConfig = config.getMapConfig("test-map");
mapConfig.getHotRestartConfig().setEnabled(true);
CacheSimpleConfig cacheConfig = config.getCacheConfig("test-cache");
cacheConfig.getHotRestartConfig().setEnabled(true);Configuring Hot Restart Store on Intel® Optane™ DC Persistent Memory
Hazelcast can be configured to use Intel® Optane™ DC Persistent Memory as the Hot Restart directory. For this, you need to perform the following steps:
-
Configure the Persistent Memory as a File System
-
Configure the Hot Restart Store to Use Persistent Memory
Using Persistent Memory, Hot Restart times can be drastically improved. You can find the configuration steps in the Hot Restart Store section of the Hazelcast IMDG Operations and Deployment Guide.
Moving/Copying Hot Restart Data
After Hazelcast member owning the Hot Restart data is shutdown, Hot Restart
base-dir can be copied/moved to a different server (which may have different
IP address and/or different number of CPU cores) and Hazelcast member can be
restarted using the existing Hot Restart data on that new server. Having a new
IP address does not affect Hot Restart, since it does not rely on the IP address
of the server but instead uses Member UUID as a unique identifier.
This flexibility provides the following abilities:
-
Replacing one or more faulty servers with the new ones easily without touching remaining cluster.
-
Using Hot Restart on the cloud environments easily. Sometimes cloud providers do not preserve the IP addresses on restart or after shutdown. Also it is possible to startup the whole cluster on a different set of machines.
-
Copying production data to the test environment, so that a more functional test cluster can bet setup.
Unfortunately having different number of CPU cores is not that straightforward.
Hazelcast partition threads, by default, uses a heuristic from the number of
cores, e.g., # of partition threads = # of CPU cores. When a Hazelcast member
is started on a server with a different CPU core count, number of Hazelcast
partition threads changes and that makes Hot Restart fail during the startup.
Solution is to explicitly set number of Hazelcast partition threads
(hazelcast.operation.thread.count system property) and Hot Restart parallelism
configuration and use the same parameters on the new server. For setting system
properties see the System Properties appendix.
Hot Restart Persistence Design Details
Hazelcast’s Hot Restart Persistence uses the log-structured storage approach. The following is a top-level design description:
-
The only kind of update operation on persistent data is appending.
-
What is appended are facts about events that happened to the data model represented by the store; either a new value was assigned to a key or a key was removed.
-
Each record associated with a key makes stale the previous record that was associated with that key.
-
Stale records contribute to the amount of garbage present in the persistent storage.
-
Measures are taken to remove garbage from the storage.
This kind of design focuses almost all of the system’s complexity into the garbage collection (GC) process, stripping down the client’s operation to the bare necessity of guaranteeing persistent behavior: a simple file append operation. Consequently, the latency of operations is close to the theoretical minimum in almost all cases. Complications arise only during prolonged periods of maximum load; this is where the details of the GC process begin to matter.
Concurrent, Incremental, Generational GC
In order to maintain the lowest possible footprint in the update operation latency, the following properties are built into the garbage collection process:
-
A dedicated thread performs the GC. In Hazelcast terms, this thread is called the Collector and the application thread is called the Mutator.
-
On each update there is metadata to be maintained; this is done asynchronously by the Collector thread. The Mutator enqueues update events to the Collector’s work queue.
-
The Collector keeps draining its work queue at all times, including the time it goes through the GC cycle. Updates are taken into account at each stage in the GC cycle, preventing the copying of already dead records into compacted files.
-
All GC-induced I/O competes for the same resources as the Mutator’s update operations. Therefore, measures are taken to minimize the impact of I/O done during GC:
-
data is never read from files, but from RAM
-
a heuristic scheme is employed which minimizes the number of bytes written to the disk for each kilobyte of the reclaimed garbage
-
measures are also taken to achieve a good interleaving of Collector and Mutator operations, minimizing latency outliers perceived by the Mutator
-
I/O Minimization Scheme
The success of this scheme is subject to a bet on the Weak Generational Garbage Hypothesis, which states that a new record entering the system is likely to become garbage soon. In other words, a key updated now is more likely than average to be updated again soon.
The scheme was taken from the seminal Sprite LFS paper, Rosenblum, Ousterhout, The Design and Implementation of a Log-Structured File System. The following is an outline of the paper:
-
Data is not written to one huge file, but to many files of moderate size (8 MB) called "chunks".
-
Garbage is collected incrementally, i.e. by choosing several chunks, then copying all their live data to new chunks, then deleting the old ones.
-
I/O is minimized using a collection technique which results in a bimodal distribution of chunks with respect to their garbage content: most files are either almost all live data or they are all garbage.
-
The technique consists of two main principles:
-
Chunks are selected based on their Cost-Benefit factor (see below).
-
Records are sorted by age before copying to new chunks.
-
Cost-Benefit Factor
The Cost-Benefit factor of a chunk consists of two components multiplied together:
-
The ratio of benefit (amount of garbage that can be collected) to I/O cost (amount of live data to be written).
-
The age of the data in the chunk, measured as the age of the youngest record it contains.
The essence is in the second component: given equal amount of garbage in all chunks, it makes the young ones less attractive to the Collector. Assuming the generational garbage hypothesis, this allows the young chunks to quickly accumulate more garbage. On the flip side, it also ensures that even files with little garbage are eventually garbage collected. This removes garbage which would otherwise linger on, thinly spread across many chunk files.
Sorting records by age groups the young records together in a single chunk and does the same for older records. Therefore the chunks are either tend to keep their data live for a longer time, or quickly become full of garbage.
Hot Restart Performance Considerations
In this section you can find performance test summaries which are results of benchmark tests performed with a single Hazelcast member running on a physical server and on AWS R3.
Performance on a Physical Server
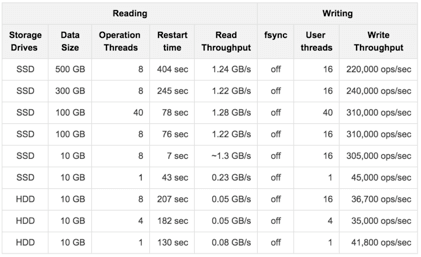
We have tested a member which has an IMap with High-Density Data Store. Its data size is changed for each test, started from 10 GB to 500 GB (each map entry has a value of 1 KB).
The tests investigate the write and read performance of Hot Restart Persistence and are performed on HP ProLiant servers with RHEL 7 operating system using Hazelcast Simulator.
The following are the specifications of the server hardware used for the test:
-
CPU: 2x Intel® Xeon® CPU E5-2687W v3 @ 3.10GHz – with 10 cores per processor. Total 20 cores, 40 with hyper threading enabled.
-
Memory: 768GB 2133 MHz memory 24x HP 32GB 4Rx4 PC4-2133P-L Kit
The following are the storage media used for the test:
-
A hot-pluggable 2.5 inch HDD with 1 TB capacity and 10K RPM.
-
An SSD, Light Endurance PCle Workload Accelerator.
The below table shows the test results.
Performance on AWS R3
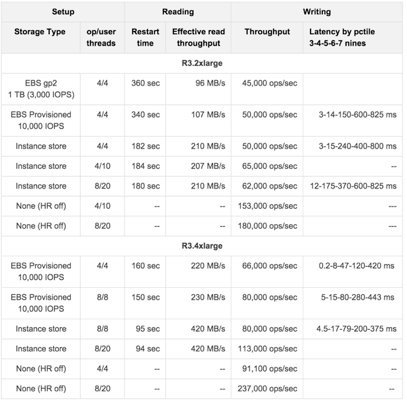
We have tested a member which has an IMap with High-Density Data Store:
-
This map has 40 million distinct keys, each map entry is 1 KB.
-
High-Density Memory Store is 59 GiB whose 19% is metadata.
-
Hot Restart is configured with
fsyncturned off. -
Data size reloaded on restart is 38 GB.
The tests investigate the write and read performance of Hot Restart Persistence and are performed on R3.2xlarge and R3.4xlarge EC2 instances using Hazelcast Simulator.
The following are the AWS storage types used for the test:
-
Elastic Block Storage (EBS) General Purpose SSD (GP2)
-
Elastic Block Storage with Provisioned IOPS (IO1) (Provisioned 10,000 IOPS on a 340 GiB volume, enabled EBS-optimized on instance)
-
SSD-backed instance store
The below table shows the test results.
Hot Backup
During Hot Restart operations you can take a snapshot of the Hot Restart Store at a certain point in time. This is useful when you wish to bring up a new cluster with the same data or parts of the data. The new cluster can then be used to share load with the original cluster, to perform testing, QA or reproduce an issue on production data.
Simple file copying of a currently running cluster does not suffice and can produce inconsistent snapshots with problems such as resurrection of deleted values or missing values.
Configuring Hot Backup
To create snapshots you must first configure the Hot Restart backup directory. You can configure the directory programmatically or declaratively using the following configuration element:
-
backup-dir: This element is included in thehot-restart-persistenceand denotes the destination under which backups are stored. If this element is not defined, hot backup is disabled. If a directory is defined which does not exist, it is created on the first backup. To avoid clashing data on multiple backups, each backup has a unique sequence ID which determines the name of the directory which contains all Hot Restart data. This unique directory is created as a subdirectory of the configuredbackup-dir.
The following are the example configurations for Hot backup.
Declarative Configuration:
An example configuration is shown below.
<hazelcast>
...
<hot-restart-persistence enabled="true">
<backup-dir>/mnt/hot-backup</backup-dir>
...
</hot-restart-persistence>
...
</hazelcast>hazelcast:
hot-restart-persistence:
enabled: true
backup-dir: /mnt/hot-backupProgrammatic Configuration:
The programmatic equivalent of the above declarative configuration is shown below.
HotRestartPersistenceConfig hotRestartPersistenceConfig = new HotRestartPersistenceConfig();
hotRestartPersistenceConfig.setBackupDir(new File("/mnt/hot-backup"));
...
config.setHotRestartPersistenceConfig(hotRestartPersistenceConfig);Using Hot Backup
Once configured, you can initiate a new backup via API or from the Management Center.
The backup is started transactionally and cluster-wide. This means that either
all or none of the members start the same backup. The member which receives the backup
request determines a new backup sequence ID and send that information to all members.
If all members respond that no other backup is currently in progress and that
no other backup request has already been made, then the coordinating member commands
the other members to start the actual backup process. This creates a directory under
the configured backup-dir with the name backup-<backupSeq> and start copying the
data from the original store.
The backup process is initiated nearly instantaneously on all members. Note that since there is no limitation as to when the backup process is initiated, it may be initiated during membership changes, partition table changes or during normal data update. Some of these operations may not be completed fully yet, which means that some members will backup some data while some members will backup a previous version of the same data. This is usually solved by the anti-entropy mechanism on the new cluster which reconciles different versions of the same data. Please check the Achieving High Consistency of Backup Data section for more information.
The duration of the backup process and the disk data usage drastically depends on what is supported by the system and the configuration. Please check the Achieving high performance of backup process section for more information on achieving better resource usage of the backup process.
Following is an example of how to trigger the Hot Backup via API:
HotRestartService service = instance.getCluster().getHotRestartService();
service.backup();The backupSeq is generated by the hot backup process, but you can define
your own backup sequences as shown below:
HotRestartService service = instance.getCluster().getHotRestartService();
long backupSeq = ...
service.backup(backupSeq);Keep in mind that the backup fails if any member contains a backup directory
with the name backup-<backupSeq>, where backupSeq is the given sequence.
Starting the Cluster From a Hot Backup
As mentioned in the previous section, hot backup process creates subdirectories
named backup-<backupSeq> under the configured hot backup directory
(i.e., backup-dir). When starting your cluster with data from a hot backup, you need to set
the base directory (i.e., base-dir) to the desired backup subdirectory.
Let’s say you have configured your hot backup directory as follows:
<hazelcast>
...
<hot-restart-persistence enabled="true">
<backup-dir>/mnt/hot-backup</backup-dir>
...
</hot-restart-persistence>
...
</hazelcast>hazelcast:
hot-restart-persistence:
enabled: true
backup-dir: /mnt/hot-backupAnd let’s say you have a subdirectory named backup-2018Oct24 under the
backup directory /mnt/hot-backup. When you want to start your cluster with data
from this backup (backup-2018Oct24), here is the configuration you should have
for the base-dir while starting the cluster:
<hazelcast>
...
<hot-restart-persistence enabled="true">
<base-dir>backup-2018Oct24</base-dir>
<parallelism>1</parallelism>
</hot-restart-persistence>
...
<map name="test-map">
<hot-restart enabled="true">
<fsync>false</fsync>
</hot-restart>
</map>
...
</hazelcast>hazelcast:
hot-restart-persistence:
enabled: true
base-dir: backup-2018Oct24
parallelism: 1
map:
test-map:
hot-restart:
enabled: true
fsync: falseAchieving High Consistency of Backup Data
The backup is initiated nearly simultaneously on all members but you can encounter some inconsistencies in the data. This is because some members might have and some might not have received updated values yet from executed operations, because the system could be undergoing partition and membership changes or because there are some transactions which have not yet been committed.
To achieve a high consistency of data on all members, the cluster should be
put to PASSIVE state for the duration of the call to the backup method.
See the Cluster Member States section on information on how to do this.
The cluster does not need to be in PASSIVE state for the entire
duration of the backup process, though. Because of the design, only partition metadata
is copied synchronously during the invocation of the backup method. Once the backup method has returned,
all cluster metadata is copied and the exact partition data which needs to be copied is marked.
After that, the backup process continues asynchronously and you can return the cluster to the
ACTIVE state and resume operations.
Achieving High Performance of Backup Process
Because of the design of Hot Restart Store, we can use hard links to achieve backups/snapshots of the store. The hot backup process uses hard links whenever possible because they provide big performance benefits and because the backups share disk usage.
The performance benefit comes from the fact that Hot Restart file contents are not being duplicated (thus using disk and I/O resources) but rather a new file name is created for the same contents on disk (another pointer to the same inode). Since all backups and stores share the same inode, disk usage drops.
The bigger the percentage of stable data in the Hot Restart Store (data not undergoing changes), the more files each backup shares with the operational Hot Restart Store and the less disk space it uses. For the hot backup to use hard links, you must be running Hazelcast members on JDK 7 or higher and must satisfy all requirements for the Files.createLink() method to be supported.
The backup process initially attempts to create a new hard link and if that fails for any reason it continues by copying the data. Subsequent backups also attempt to use hard links.
Backup Process Progress and Completion
Only cluster and distributed object metadata is copied synchronously during the invocation of the backup method. The rest of the Hot Restart Store containing partition data is copied asynchronously after the method call has ended. You can track the progress by API or view it from the Management Center.
An example of how to track the progress via API is shown below:
HotRestartService service = instance.getCluster().getHotRestartService();
BackupTaskStatus status = service.getBackupTaskStatus();
...The returned object contains the local member’s backup status:
-
the backup state (NOT_STARTED, IN_PROGRESS, FAILURE, SUCCESS)
-
the completed count
-
the total count
The completed and total count can provide you a way to track the
percentage of the copied data. Currently the count defines the
number of copied and total local member Hot Restart Stores
(defined by HotRestartPersistenceConfig.setParallelism())
but this can change at a later point to provide greater resolution.
Besides tracking the Hot Restart status by API, you can view the status in the
Management Center and you can inspect the on-disk files for each member.
Each member creates an inprogress file which is created in each of the copied Hot Restart Stores.
This means that the backup is currently in progress. When the backup task completes
the backup operation, this file is removed. If an error occurs during the backup task,
the inprogress file is renamed to failure which contains a stack trace of the exception.
Backup Task Interruption and Cancellation
Once the backup method call has returned and asynchronous copying of the partition data has started, the backup task can be interrupted. This is helpful in situations where the backup task has started at an inconvenient time. For instance, the backup task could be automatized and it could be accidentally triggered during high load on the Hazelcast instances, causing the performance of the Hazelcast instances to drop.
The backup task mainly uses disk IO, consumes little CPU and it generally does not last for a long time (although you should test it with your environment to determine the exact impact). Nevertheless, you can abort the backup tasks on all members via a cluster-wide interrupt operation. This operation can be triggered programmatically or from the Management Center.
An example of programmatic interruption is shown below:
HotRestartService service = instance.getCluster().getHotRestartService();
service.interruptBackupTask();
...This method sends an interrupt to all members. The interrupt is ignored if the backup task is currently not in progress so you can safely call this method even though it has previously been called or when some members have already completed their local backup tasks.
You can also interrupt the local member backup task as shown below:
HotRestartService service = instance.getCluster().getHotRestartService();
service.interruptLocalBackupTask();
...The backup task stops as soon as possible and it does not remove the disk contents of the backup directory meaning that you must remove it manually.
Encryption at Rest
Records stored in the Hot Restart Store may contain sensitive information. This sensitive information may be present in the keys, in the values, or in both. In Hot Restart terms, Encryption at Rest concerns with encryption on the chunk file level. Since complete chunk files are encrypted, all data stored in the Hot Restart Store is protected when Encryption at Rest is enabled.
Data persisted in the Hot Restart Store is encrypted using symmetric encryption. The implementation is based on Java Cryptography Architecture (JCA). The encryption scheme uses two levels of encryption keys: auto-generated Hot Restart Store-level encryption keys (one per configured parallelism) that are used to encrypt the chunk files and a master encryption key that is used to encrypt the store-specific encryption keys. The master encryption key is sourced from an external system called Secure Store and, in contrast to the Hot Restart Store-level encryption keys, it is not persisted anywhere within the Hot Restart Store.
When Hot Restart with Encryption at Rest is first enabled on a member, the member contacts the Secure Store during the startup and retrieves the master encryption key. Then it generates the Hot Restart Store-level encryption keys for the parallel Stores and stores them (encrypted using the master key) under the Hot Restart Store’s directory. The subsequent writes to Hot Restart chunk files will be encrypted using the Store-level encryption key. During Hot Restart, the member retrieves the master encryption key from the Secure Store, decrypts the Store-level encryption keys and uses those to decrypt the chunk files.
Master key rotation is supported. If the master encryption key changes in the Secure Store, the Hot Restart subsystem will detect it and retrieve the new master encryption key. During this process, it will also re-encrypt the Hot Restart Store-level encryption keys using the new master encryption key.
The Configuring a Secure Store section provides information about the supported Secure Store types.
Configuring Encryption at Rest
Encryption at Rest can be enabled and configured programmatically or declaratively using the
encryption-at-rest sub-element of hot-restart-persistence. The encryption-at-rest
element has the following attributes and sub-elements:
-
enabled: Attribute that specifies whether Encryption at Rest is enabled;falseby default. -
algorithm: Specifies the symmetric cipher to use (such asAES/CBC/PKCS5Padding). -
salt: The encryption salt. -
key-size: The size of the auto-generated Hot Restart Store-level encryption key. -
secure-store: Specifies the Secure Store to use for the retrieval of master encryption keys. See the Configuring a Secure Store section for more details.
The following are the example configurations for Encryption at Rest.
Declarative Configuration:
An example configuration is shown below.
<hazelcast>
...
<hot-restart-persistence enabled="true">
...
<encryption-at-rest enabled="true">
<algorithm>AEC/CBC/PKCS5Padding</algorithm>
<salt>thesalt</salt>
<key-size>128</key-size>
<secure-store>...</secure-store>
</encryption-at-rest>
...
</hot-restart-persistence>
...
</hazelcast>hazelcast:
hot-restart-persistence:
enabled: true
encryption-at-rest:
enabled: true
algorithm: AES/CBC/PKCS5Padding
salt: thesalt
key-size: 128
secure-store:
...Programmatic Configuration:
The programmatic equivalent of the above declarative configuration is shown below.
HotRestartPersistenceConfig hotRestartPersistenceConfig = new HotRestartPersistenceConfig();
EncryptionAtRestConfig encryptionAtRestConfig =
hotRestartPersistenceConfig.getEncryptionAtRestConfig();
encryptionAtRestConfig.setEnabled(true)
.setAlgorithm("AES/CBC/PKCS5Padding")
.setSalt("thesalt")
.setKeySize(128)
.setSecureStoreConfig(secureStore());Configuring a Secure Store
A Secure Store represents a (secure) source of master encryption keys and is required for using Encryption at Rest.
Hazelcast IMDG Enterprise provides Secure Store implementations for the Java KeyStore and for HashiCorp Vault.
Java KeyStore Secure Store
The Java KeyStore Secure Store provides integration with the Java KeyStore.
It can be configured programmatically or declaratively using the
keystore sub-element of secure-store. The keystore element has the following sub-elements:
-
path: The path to the KeyStore file. -
type: The type of the KeyStore (PKCS12,JCEKS, etc.). -
password: The KeyStore password. -
current-key-alias: The alias for the current encryption key entry (optional). -
polling-interval: The polling interval (in seconds) for checking for changes in the KeyStore. Disabled by default.
Sensitive configuration properties such as password should be protected using
encryption replacers.
|
The Java KeyStore Secure treats all KeyStore.SecretKeyEntry entries stored in the KeyStore as
encryption keys. It expects that these entries use the same protection password as the KeyStore
itself. Entries of other types (private key entries, certificate entries) are ignored. If
current-key-alias is set, the corresponding entry will be treated as the current encryption key;
otherwise, the highest entry in the alphabetical order will be used. The remaining entries will
represent historical versions of the encryption key.
An example declarative configuration is shown below:
<secure-store>
<keystore>
<path>/path/to/keystore.file</path>
<type>PKCS12</type>
<password>password</password>
<current-key-alias>current</current-key-alias>
<polling-interval>60</polling-interval>
</keystore>
</secure-store> secure-store:
keystore:
path: /path/to/keystore.file
type: PKCS12
password: password
current-key-alias: current
polling-interval: 60The following is an equivalent programmatic configuration:
JavaKeyStoreSecureStoreConfig keyStoreConfig =
new JavaKeyStoreSecureStoreConfig(new File("/path/to/keystore.file"))
.setType("PKCS12")
.setPassword("password")
.setCurrentKeyAlias("current")
.setPollingInterval(60);HashiCorp Vault Secure Store
The HashiCorp Vault Secure Store provides integration with HashiCorp Vault.
It can be configured programmatically or declaratively using the
vault sub-element of secure-store. The vault element has the following sub-elements:
-
address: The address of the Vault server. -
secret-path: The secret path under which the encryption keys are stored. -
token: The Vault authentication token. -
polling-interval: The polling interval (in seconds) for checking for changes in Vault. Disabled by default. -
ssl: The TLS/SSL configuration for HTTPS support. See the TLS/SSL section for more information about how to use thesslelement.
Sensitive configuration properties such as token should be protected using
encryption replacers.
|
The HashiCorp Vault Secure Store implementation uses the official REST API to integrate with HashiCorp Vault. Only for the KV secrets engine, both KV V1 and KV V2 can be used, but since only V2 provides secrets versioning, this is the recommended option. With KV V1 (no versioning support), only one version of the encryption key can be kept, whereas with KV V2, the HashiCorp Vault Secure Store is able to retrieve also the historical encryption keys. (Note that the size of the version history is configurable on the Vault side.) Having access to the previous encryption keys may be critical to avoid scenarios where the Hot Restart data becomes undecryptable because the master encryption key is no longer usable (for instance, when the original master encryption key got rotated out in the Secure Store while the cluster was down).
The encryption key is expected to be stored at the specified secret path and represented as a single key/value pair in the following format:
name=Base64-encoded-datawhere name can be an arbitrary string. Multiple key/value pairs under the same secret path are not
supported. Here is an example of how such a key/value pair can be stored using the HashiCorp
Vault command-line client (under the secret path hz/cluster):
vault kv put hz/cluster value=HEzO124Vz...With KV V2, a second put to the same secret path creates a new version of the encryption key.
With KV V1, it simply overwrites the current encryption key, discarding the old value.
An example declarative configuration is shown below:
<secure-store>
<vault>
<address>http://localhost:1234</address>
<secret-path>secret/path</secret-path>
<token>token</token>
<polling-interval>60</polling-interval>
<ssl>...</ssl>
</vault>
</secure-store> secure-store:
vault:
address: http://localhost:1234
secret-path: secret/path
token: token
polling-interval: 60
ssl:
...The following is an equivalent programmatic configuration:
VaultSecureStoreConfig vaultConfig =
new VaultSecureStoreConfig("http://localhost:1234", "secret/path", "token")
.setPollingInterval(60);
configureSSL(vaultConfig.getSSLConfig());