A distinctive feature of Hazelcast is that it has no dependency on disk storage, it keeps all its operational state in the RAM of the cluster. Here are some details on how that storage works.
Data is Partitioned and Replicated
Hazelcast divides the key space into partitions (aka. shards) and maps each key to a single partition. By default, there are 271 partitions. For each partition, Hazelcast creates multiple replicas, and assigns one replica as primary and other replicas as backups.
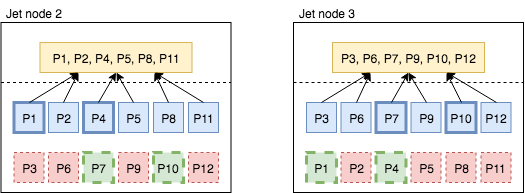
We’ll walk through a scenario with 3 Hazelcast members and 12 partitions, as shown in Figure 1. Primaries are blue, backups red. For instance, the 1st member keeps primaries for partitions 1, 4, 7, 10 and backups for partitions 2, 3, 5, 6. On the top, in yellow, there is a single Jet processor (local parallelism = 1) that does a group-and-aggregate operation.
The DAG edge that delivers the data to this processor is of the partitioned-distributed kind. For each item Hazelcast first extracts its key, computes the key’s partition, looks up the processor in charge of that partition, and sends it there. Every processor maintains its own internal state.
Snapshots are Stored in IMap
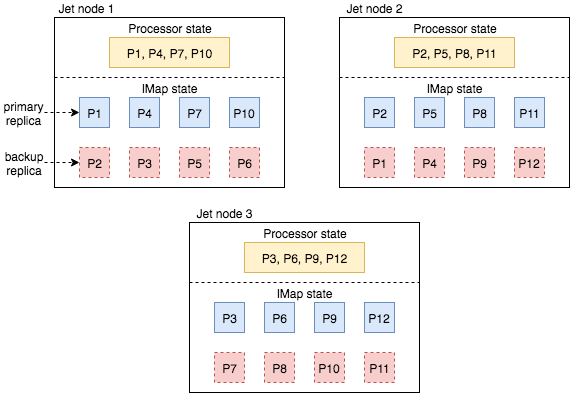
When a processor receives a snapshot barrier from its input streams, it saves its internal state to the Hazelcast IMap which is created for the current snapshot. Figure 2 shows how state objects of the first processor instance end up in the local member’s primaries, thanks to the same partitioning scheme used for both processing and storage. Additionally, backup copies of these state objects are sent to the 2nd and the 3rd member.
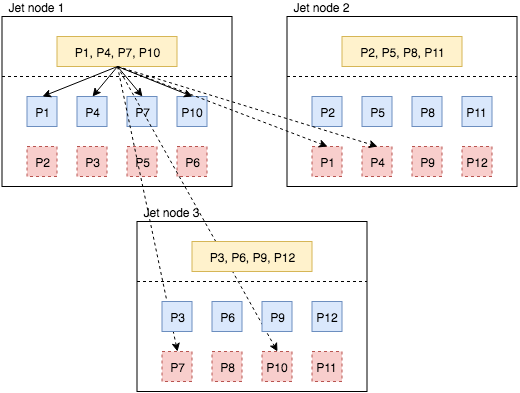
Data Spreads to a Newly Added Member
Let’s see how we make use of the partition replicas to recover processor state after a change in the cluster topology. In Figure 3 we added a new member to the Hazelcast cluster. Hazelcast rebalances the partitions and assigns some partition replicas to the new member. It uses the consistent hashing algorithm to move a minimum amount of data between the members while rebalancing. In our scenario, the new member receives one primary and one backup from each existing Hazelcast member. For instance, from the 1st member it receives the primary of partition 1 and backup of partition 2. After rebalancing the job is restarted and processor states are initialized from local replicas of the snapshot.
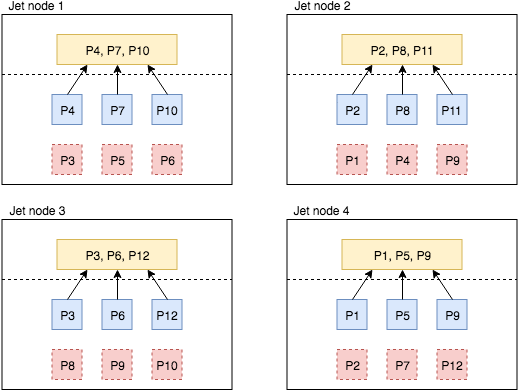
Data Recovered from Backups when a Member Fails
Finally, Figure 4 shows how Hazelcast recovers from the failure of 1st member. Before the failure, 2nd and 3rd members were keeping the backup replicas for the partitions assigned to the 1st member. After the failure, the 2nd member promotes partitions 1 and 4 from backup to primary. Similarly, the 3rd member promotes partitions 7 and 10. After promotion these partitions lack a backup so the members create new backup replicas for each other, as shown with the bold-dashed green boxes. After this point, processor states are restored from the local primary partition replicas.