Hazelcast provides APIs and plugins for building distributed caches for your data, including web sessions, database queries, and compute results. Get familiar with Hazelcast as a cache and find useful resources for your use case.
What is a Cache?
A cache is a secondary data store that’s faster to read than the data’s primary store (also known as the source of truth).
The purpose of a cache is to improve the performance of your applications by doing the following:
-
Reducing network calls to a primary data store.
-
Saving the results of queries or computations to avoid resubmitting them.
Data stored in a cache is often kept in random-access memory (RAM) because its faster to read.
In Hazelcast, the RAM of all cluster members is combined into a single in-memory data store to provide fast access to data. This distributed model is called a cache cluster, and it makes your data fault-tolerant and scalable. If a member goes down, your data is repartitioned across the remaining members. And, if you need more or fewer resources, you can add or remove members as necessary.
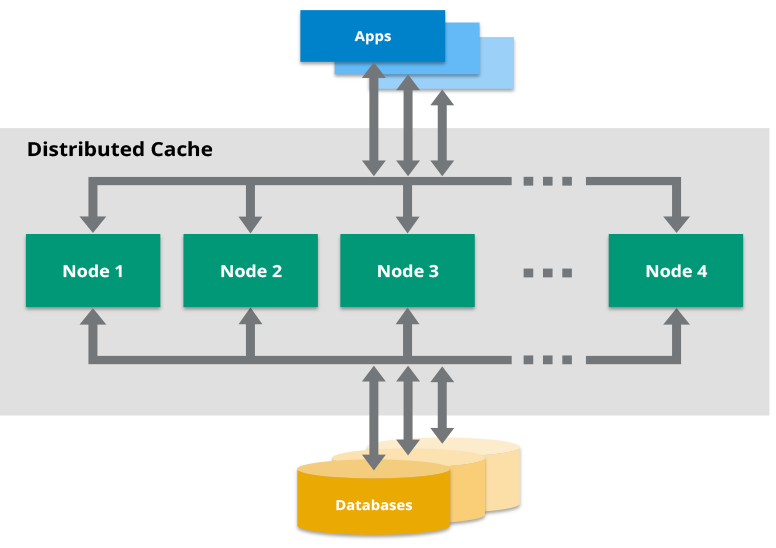
Caching Topologies
To use Hazelcast as a distributed cache, you can choose one of the following topologies:
-
Embedded mode: In this mode, the application and the cached data are stored on the same device. When a new entry is written to the cache, Hazelcast takes care of distributing it to the other members.
-
Client/server mode: In this mode, the cached data is separated from the application. Hazelcast members run on dedicated servers and applications connect to them through clients.
| Topology | Advantages | Disadvantages |
|---|---|---|
Embedded |
Data access is faster because applications don’t need to send a request to the cache cluster over the network. |
Hazelcast can be embedded only in Java applications. Each new instance of your application adds a new member to the cluster even if you don’t it. |
Client/server |
Supports independent scaling of the application and the cache cluster. Allows you to write polyglot applications that can all connect to the same cache cluster. |
To read from a cache or write to it, clients need to make network requests, which leads to higher latency than embedded mode. |
For more information about topologies, see Choosing an Application Topology.
Caching Data on the Client-Side
If you use the client-server topology, your application will request cached data from your cluster over a network.
To reduce these network requests, you can enable a near cache on the client.
A near cache is a local cache that is created on the client. When an application wants to read data, first it looks for the data in the near cache. If the near cache doesn’t have the data, the application requests it from the cache cluster and adds it to the near cache to use for future requests.
For information about how to use a near cache, see Best practices.
Caching Patterns
The way in which an application interacts with a cache is called a caching pattern. Many patterns exist and each one has its pros and cons.
For an in-depth discussion on caching patterns in Hazelcast, see our blog A Hitchhiker’s Guide to Caching Patterns.
Cache in Spring Applications
Spring is a framework that comes with out-of-the-box modules for developing Java applications.
To allow you to easily plug a cache cluster into your Spring application, Hazelcast includes a Spring integration.
For more information about caching in Spring applications, see the following:
Second-Level Cache for Hibernate
Hibernate is a framework for mapping an object-oriented domain model to a relational database in Java applications.
To make it faster to read data, Hibernate uses a multilevel caching scheme:
-
First-level cache: A mandatory cache that stores the
Sessionobject until the session is closed. -
Second-level cache: An optional cache that’s mainly responsible for caching objects across sessions.
To use Hazelcast as a second-level cache, see the following:
Cache Manager in JCache
JCache is a standard caching API for the Java programming language.
To find out more about JCache and how to use Hazelcast as the caching provider, see JCache Overview.
Caching Web Sessions in Hazelcast
To support more users, web applications often consist of multiple instances running at the same time. This way, traffic can be routed to different instances through load balancers to maximize speed and reliability.
However, in this architecture, if a server fails and the load balancer redirects the user to a new server, the session data is lost because sessions are stored on specific application servers.
The solution to this problem is to provide web session clustering (also known as web session replication) which allows any application server to access the same system-wide cache of web session data.

Hazelcast provides native integration for the Apache Tomcat and Eclipse Jetty application servers as well as for generic application servers through the use of filters.
To use Hazelcast for web session replication, see the following resources:
Caching with JDBC Data Stores
To configure a cache with a connection to JDBC data store, see Using the generic MapStore.
Building a Custom Database Cache
To build your own database cache, see Implementing a Custom MapStore.
Related Resources
For all Hazelcast integrations, see Hazelcast Plugins.