Hazelcast Map (IMap) extends the interface java.util.concurrent.ConcurrentMap
and hence java.util.Map. It is the distributed implementation of Java map. You can
perform operations like reading and writing from/to a Hazelcast map with the well
known get and put methods.
| IMap data structure can also be used by Hazelcast Jet for Real-Time Stream Processing (by enabling the Event Journal on your map) and Fast Batch Processing. Hazelcast Jet uses IMap as a source (reads data from IMap) and as a sink (writes data to IMap). See the Fast Batch Processing and Real-Time Stream Processing use cases for Hazelcast Jet. See also here in the Hazelcast Jet Programming Guide to learn how Jet uses IMap, i.e., how it can read from and write to IMap. |
Getting a Map and Putting an Entry
Hazelcast partitions your map entries and their backups, and almost evenly distribute them onto all Hazelcast members. Each member carries approximately "number of map entries * 2 * 1/n" entries, where n is the number of members in the cluster. For example, if you have a member with 1000 objects to be stored in the cluster and then you start a second member, each member will both store 500 objects and back up the 500 objects in the other member.
Let’s create a Hazelcast instance and fill a map named Capitals with key-value pairs
using the following code. Use the HazelcastInstance getMap method to get the map,
then use the map put method to put an entry into the map.
HazelcastInstance hzInstance = Hazelcast.newHazelcastInstance();
Map<String, String> capitalcities = hzInstance.getMap( "capitals" );
capitalcities.put( "1", "Tokyo" );
capitalcities.put( "2", "Paris" );
capitalcities.put( "3", "Washington" );
capitalcities.put( "4", "Ankara" );
capitalcities.put( "5", "Brussels" );
capitalcities.put( "6", "Amsterdam" );
capitalcities.put( "7", "New Delhi" );
capitalcities.put( "8", "London" );
capitalcities.put( "9", "Berlin" );
capitalcities.put( "10", "Oslo" );
capitalcities.put( "11", "Moscow" );
...
capitalcities.put( "120", "Stockholm" );When you run this code, a cluster member is created with a map whose entries are distributed across the members' partitions. See the below illustration. For now, this is a single member cluster.
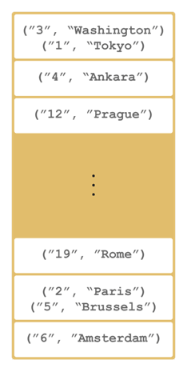
Please note that some of the partitions do not contain any data entries since
we only have 120 objects and the partition count is 271 by default. This count is
configurable and can be changed using the system property hazelcast.partition.count.
See the System Properties appendix.
|
Creating A Member for Map Backup
Now let’s create a second member by running the above code again. This creates a cluster with two members. This is also where backups of entries are created - remember the backup partitions mentioned in the Hazelcast Overview section. The following illustration shows two members and how the data and its backup is distributed.
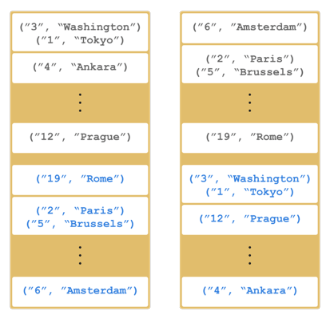
As you see, when a new member joins the cluster, it takes ownership and loads some of the
data in the cluster. Eventually, it will carry almost "(1/n * total-data) + backups" of the data,
reducing the load on other members.
HazelcastInstance.getMap() returns an instance of com.hazelcast.map.IMap which extends
the java.util.concurrent.ConcurrentMap interface. Methods like
ConcurrentMap.putIfAbsent(key,value) and ConcurrentMap.replace(key,value) can be used
on the distributed map, as shown in the example below.
public class BasicMapOperations {
private HazelcastInstance hazelcastInstance = Hazelcast.newHazelcastInstance();
public Customer getCustomer(String id) {
ConcurrentMap<String, Customer> customers = hazelcastInstance.getMap("customers");
Customer customer = customers.get(id);
if (customer == null) {
customer = new Customer(id);
customer = customers.putIfAbsent(id, customer);
}
return customer;
}
public boolean updateCustomer(Customer customer) {
ConcurrentMap<String, Customer> customers = hazelcastInstance.getMap("customers");
return (customers.replace(customer.getId(), customer) != null);
}
public boolean removeCustomer(Customer customer) {
ConcurrentMap<String, Customer> customers = hazelcastInstance.getMap("customers");
return customers.remove(customer.getId(), customer);
}
}All ConcurrentMap operations such as put and remove might wait if the key is locked
by another thread in the local or remote JVM. But, they will eventually return with success.
ConcurrentMap operations never throw a java.util.ConcurrentModificationException.
Backing Up Maps
Hazelcast distributes map entries onto multiple cluster members (JVMs). Each member holds some portion of the data.
Distributed maps have one backup by default. If a member goes down, your data is recovered using the backups in the cluster. There are two types of backups as described below: sync and async.
Creating Sync Backups
To provide data safety, Hazelcast allows you to specify the number of backup copies you want to have. That way, data on a cluster member is copied onto other member(s).
To create synchronous backups, select the number of backup copies using the backup-count property.
<hazelcast>
...
<map name="default">
<backup-count>1</backup-count>
</map>
...
</hazelcast>hazelcast:
map:
default:
backup-count: 1When this count is 1, a map entry will have its backup on one other member in the cluster. If you set it to 2, then a map entry will have its backup on two other members. You can set it to 0 if you do not want your entries to be backed up, e.g., if performance is more important than backing up. The maximum value for the backup count is 6.
Hazelcast supports both synchronous and asynchronous backups. By default, backup operations
are synchronous and configured with backup-count. In this case, backup operations block
operations until backups are successfully copied to backup members (or deleted from backup
members in case of remove) and acknowledgements are received. Therefore, backups are updated
before a write(put, set, remove and their async counterparts) operation is completed,
provided that the cluster is stable. Sync backup operations have a blocking cost which may
lead to latency issues.
Creating Async Backups
Asynchronous backups, on the other hand, do not block operations. They are fire & forget and do not require acknowledgements; the backup operations are performed at some point in time.
To create asynchronous backups, select the number of async backups with the async-backup-count
property. An example is shown below.
<hazelcast>
...
<map name="default">
<backup-count>0</backup-count>
<async-backup-count>1</async-backup-count>
</map>
...
</hazelcast>hazelcast:
map:
default:
backup-count: 0
async-backup-count: 1See Consistency and Replication Model for more detail.
| Backups increase memory usage since they are also kept in memory. |
| A map can have both sync and async backups at the same time. |
Enabling Backup Reads
By default, Hazelcast has one sync backup copy. If backup-count is set to more than 1, then
each member will carry both owned entries and backup copies of other members. So for the map.get(key)
call, it is possible that the calling member has a backup copy of that key. By default, map.get(key)
always reads the value from the actual owner of the key for consistency.
To enable backup reads (read local backup entries), set the value of the read-backup-data property
to true. Its default value is false for consistency. Enabling backup reads can improve
performance but on the other hand it can cause stale reads while still preserving monotonic-reads property.
<hazelcast>
...
<map name="default">
<backup-count>0</backup-count>
<async-backup-count>1</async-backup-count>
<read-backup-data>true</read-backup-data>
</map>
...
</hazelcast>hazelcast:
map:
default:
backup-count: 0
async-backup-count: 1
read-backup-data: trueThis feature is available when there is at least one sync or async backup.
Please note that if you are performing a read from a backup, you should take into account that your hits to the keys in the backups are not reflected as hits to the original keys on the primary members. This has an impact on IMap’s maximum idle seconds or time-to-live seconds expiration. Therefore, even though there is a hit on a key in backups, your original key on the primary member may expire.
| Backup reads that are requested by Hazelcast clients are ignored since this operation is performed on the local entries. |
Map Eviction
Hazelcast maps have no restrictions on the size and may grow arbitrarily large, by default. Unless you delete the map entries manually or use an eviction policy, they will remain in the map. When it comes to reducing the size of a map, there are two concepts: expiration and eviction.
Expiration puts a limit on the maximum lifetime of an entry stored inside the map.
When the entry expires it cannot be retrieved from the map any longer and at some point
in time it will be cleaned out from the map to free up the memory. You can configure the expiration,
and hence the eviction based on the expiration, using the elements time-to-live-seconds
and max-idle-seconds as described in Configuring Map Eviction below.
Eviction puts a limit on the maximum size of the map. If the size of the map grows larger than
the maximum allowed size, an eviction policy decides which item to evict from the map to reduce
its size. You can configure the maximum allowed size and eviction policy using the elements
size and eviction-policy as described in Configuring Map Eviction below.
Eviction and expiration can be used together. In this case, the expiration configurations
(time-to-live-seconds and max-idle-seconds) continue to work as usual cleaning out the
expired entries regardless of the map size. Note that locked map entries are not the subjects
for eviction and expiration.
Hazelcast Map uses the same eviction mechanism as our JCache implementation. See the Eviction Algorithm section for details.
Understanding Map Eviction
Hazelcast Map performs eviction based on partitions. For example, when you specify a size using
the PER_NODE attribute for max-size (see the Configuring Map Eviction section),
Hazelcast internally calculates the maximum size for every partition. Hazelcast uses the following
equation to calculate the maximum size of a partition:
partition-maximum-size = max-size * member-count / partition-count
If the partition-maximum-size is less than 1 in the equation above, it will be set to 1
(otherwise, the partitions would be emptied immediately by eviction due to the exceedance of
max-size being less than 1).
|
The eviction process starts according to this calculated partition maximum size when you try to put an entry. When entry count in that partition exceeds partition maximum size, eviction starts on that partition.
Assume that you have the following figures as examples:
-
partition count: 200
-
entry count for each partition: 100
-
max-size(PER_NODE): 20000
The total number of entries here is 20000 (partition count * entry count for each partition).
This means you are at the eviction threshold since you set the max-size to 20000. When you
try to put an entry:
-
the entry goes to the relevant partition
-
the partition checks whether the eviction threshold is reached (
max-size) -
only one entry will be evicted.
As a result of this eviction process, when you check the size of your map, it is 19999. After
this eviction, subsequent put operations do not trigger the next eviction until the map size
is again close to the max-size.
| The above scenario is simply an example that describes how the eviction process works. Hazelcast finds the most optimum number of entries to be evicted according to your cluster size and selected policy. |
Configuring Map Eviction
The following is an example declarative configuration for map eviction.
Some map entries are not always evicted or expired according to their time-to-live or max-idle-seconds configurations. To fix this issue, you must set the per-entry-stats-enabled property to true. For details about this issue, see the pull request on GitHub.
|
<hazelcast>
...
<map name="default">
<time-to-live-seconds>0</time-to-live-seconds>
<max-idle-seconds>0</max-idle-seconds>
<eviction eviction-policy="LRU" max-size-policy="PER_NODE" size="5000"/>
</map>
...
</hazelcast>hazelcast:
map:
default:
time-to-live-seconds: 0
max-idle-seconds: 0
eviction:
eviction-policy: LRU
max-size-policy: PER_NODE
size: 5000The following are the configuration element descriptions:
-
time-to-live-seconds: Maximum time in seconds for each entry to stay in the map (TTL). It limits the lifetime of the entries relative to the time of the last write access performed on them. If it is not 0, the entries whose lifetime exceeds this period (without any write access performed on them during this period) are expired and evicted automatically. An individual entry may have its own lifetime limit by using one of the methods accepting a TTL; see Evicting Specific Entries section. If there is no TTL value provided for the individual entry, it inherits the value set for this element. Valid values are integers between 0 andInteger.MAX VALUE. Its default value is 0, which means infinite (no expiration and eviction). If it is not 0, entries are evicted regardless of the seteviction-policydescribed below. -
max-idle-seconds: Maximum time in seconds for each entry to stay idle in the map. It limits the lifetime of the entries relative to the time of the last read or write access performed on them. The entries whose idle period exceeds this limit are expired and evicted automatically. An entry is idle if noget,put,EntryProcessor.processorcontainsKeyis called on it. Valid values are integers between 0 andInteger.MAX VALUE. Its default value is 0, which means infinite.Setting this property to 1 second expires the entry after 1 second, regardless of the operations done on that entry in-between, due to the loss of millisecond resolution on the entry timestamps. Assume that you create a record at time = 1 second (1000 milliseconds) and access it at wall clock time 1100 milliseconds and then again at 1400 milliseconds. In this case, the entry is deemed as not touched. So, setting this property to 1 second is not supported. Both time-to-live-secondsandmax-idle-secondsmay be used simultaneously on the map entries. In that case, the entry is considered expired if at least one of the policies marks it as expired. -
eviction: By default map has no eviction configured. To make it work you have to configure it using the following attributes of this element:-
eviction-policy: Eviction policy to be applied when the size of map grows larger than the value specified by thesizeelement described below. Valid values are:-
NONE: Default policy. If set, no items are evicted and the property
sizedescribed below is ignored. You still can combine it withtime-to-live-secondsandmax-idle-seconds. -
LRU: Least Recently Used.
-
LFU: Least Frequently Used.
Apart from the above values, you can also develop and use your own eviction policy. See the Custom Eviction Policy section.
-
-
size: Maximum size of the map. When maximum size is reached, the map is evicted based on the policy defined. Valid values are integers between 0 andInteger.MAX VALUE. Its default value is 0, which means infinite. If you wantsizeto work, set theeviction-policyproperty to a value other thanNONE. Its attributes are described below. -
max-size-policy: Maximum size policy for eviction of the map. Available values are as follows:-
PER_NODE: Maximum number of map entries in each cluster member. This is the default policy. -
PER_PARTITION: Maximum number of map entries within each partition. Storage size depends on the partition count in a cluster member. This attribute should not be used often. For instance, avoid using this attribute with a small cluster. If the cluster is small, it hosts more partitions, and therefore map entries, than that of a larger cluster. Thus, for a small cluster, eviction of the entries decreases performance (the number of entries is large). -
USED_HEAP_SIZE: Maximum used heap size in megabytes per map for each Hazelcast instance. Please note that this policy does not work when in-memory format is set toOBJECT, since the memory footprint cannot be determined when data is put asOBJECT.
-
-
USED_HEAP_PERCENTAGE: Maximum used heap size percentage per map for each Hazelcast instance. If, for example, a JVM is configured to have 1000 MB and this value is 10, then the map entries will be evicted when used heap size exceeds 100 MB. Please note that this policy does not work when in-memory format is set toOBJECT, since the memory footprint cannot be determined when data is put asOBJECT.-
FREE_HEAP_SIZE: Minimum free heap size in megabytes for each JVM. -
FREE_HEAP_PERCENTAGE: Minimum free heap size percentage for each JVM. If, for example, a JVM is configured to have 1000 MB and this value is 10, then the map entries will be evicted when free heap size is below 100 MB. -
USED_NATIVE_MEMORY_SIZE: (Hazelcast IMDG Pro and Enterprise) Maximum used native memory size in megabytes per map for each Hazelcast instance. -
USED_NATIVE_MEMORY_PERCENTAGE: (Hazelcast IMDG Pro and Enterprise) Maximum used native memory size percentage per map for each Hazelcast instance. -
FREE_NATIVE_MEMORY_SIZE: (Hazelcast IMDG Pro and Enterprise) Minimum free native memory size in megabytes for each Hazelcast instance. -
FREE_NATIVE_MEMORY_PERCENTAGE: (Hazelcast IMDG Pro and Enterprise) Minimum free native memory size percentage for each Hazelcast instance.`
-
-
Fine-Tuning Map Eviction
Besides the above configuration elements and attributes you can fine-tune the eviction related to the entry counts to be evicted using the following Hazelcast properties:
-
hazelcast.map.eviction.batch.size: Specifies the maximum number of map entries that are evicted during a single eviction cycle. Its default value is 1, meaning at most 1 entry is evicted, which is typically fine. However, when you insert values during an eviction cycle, each iteration doubles the entry size. In this situation more than just a single entry should be evicted. -
hazelcast.map.eviction.sample.count: Whenever a map eviction is required, a new sampling starts by the built-in sampler. The sampling algorithm selects a random sample from the underlying data storage and it results in a set of map entries. This property specifies the entry count of this sample. Its default value is 15.
See also the Eviction Algorithm section to learn more details on evicting entries.
Example Eviction Configurations
<hazelcast>
...
<map name="documents">
<eviction eviction-policy="LRU" max-size-policy="PER_NODE" size="10000"/>
<max-idle-seconds>60</max-idle-seconds>
</map>
...
</hazelcast>hazelcast:
map:
documents:
eviction:
eviction-policy: LRU
max-size-policy: PER_NODE
size: 10000
max-idle-seconds: 60In the above example, documents map starts to evict its entries from a member when the
map size exceeds 10000 in that member. Then the entries least recently used will be evicted.
The entries not used for more than 60 seconds will be evicted as well.
And the following is an example eviction configuration for a map having NATIVE as the
in-memory format:
<hazelcast>
...
<map name="nativeMap">
<in-memory-format>NATIVE</in-memory-format>
<eviction max-size-policy="USED_NATIVE_MEMORY_PERCENTAGE" eviction-policy="LFU" size="99"/>
</map>
...
</hazelcast>hazelcast:
map:
nativeMap:
in-memory-format: NATIVE
eviction:
eviction-policy: LFU
max-size-policy: USED_NATIVE_MEMORY_PERCENTAGE
size: 99Evicting Specific Entries
The eviction policies and configurations explained above apply to all the entries of a map. The entries that meet the specified eviction conditions are evicted.
If you want to evict some specific map entries, you can use the ttl and ttlUnit parameters of
the method map.put(). An example code line is given below.
myMap.put( "1", "John", 50, TimeUnit.SECONDS )
The map entry with the key "1" will be evicted 50 seconds after it is put into myMap.
You may also use map.setTTL method to alter the time-to-live value of an existing entry.
It is done as follows:
myMap.setTTL( "1", 50, TimeUnit.SECONDS )
In addition to the ttl, you may also specify a maximum idle timeout for specific map entries
using the maxIdle and maxIdleUnit parameters:
myMap.put( "1", "John", 50, TimeUnit.SECONDS, 40, TimeUnit.SECONDS )
Here ttl is set as 50 seconds and maxIdle is set as 40 seconds. The entry is considered to
be evicted if at least one of these policies marks it as expired. If you want to specify only
the maxIdle parameter, you need to set ttl as 0 seconds.
Evicting All Entries
To evict all keys from the map except the locked ones, use the method evictAll().
If a MapStore is defined for the map, deleteAll is not called by evictAll. If
you want to call the method deleteAll, use clear().
An example is given below.
final int numberOfKeysToLock = 4;
final int numberOfEntriesToAdd = 1000;
HazelcastInstance node1 = Hazelcast.newHazelcastInstance();
HazelcastInstance node2 = Hazelcast.newHazelcastInstance();
IMap<Integer, Integer> map = node1.getMap( "map" );
for (int i = 0; i < numberOfEntriesToAdd; i++) {
map.put(i, i);
}
for (int i = 0; i < numberOfKeysToLock; i++) {
map.lock(i);
}
// should keep locked keys and evict all others.
map.evictAll();
System.out.printf("# After calling evictAll...\n");
System.out.printf("# Expected map size\t: %d\n", numberOfKeysToLock);
System.out.printf("# Actual map size\t: %d\n", map.size());| Only EVICT_ALL event is fired for any registered listeners. |
Forced Eviction
Hazelcast IMDG Enterprise
Hazelcast may use forced eviction in the cases when the eviction
explained in Understanding Map Eviction
is not enough to free up your memory. Note that this is valid if
you are using Hazelcast IMDG Enterprise and you set your
in-memory format to NATIVE.
The forced eviction mechanism is explained below as steps in the given order:
-
When the normal eviction is not enough, forced eviction is triggered and first it tries to evict approx. 20% of the entries from the current partition. It retries this five times.
-
If the result of above step is still not enough, forced eviction applies the above step to all maps. This time it might perform eviction from some other partitions too, provided that they are owned by the same thread.
-
If that is still not enough to free up your memory, it evicts not the 20% but all the entries from the current partition.
-
If that is not enough, it will evict all the entries from the other data structures; from the partitions owned by the local thread.
Finally, when all the above steps are not enough, Hazelcast throws
a native OutOfMemoryException.
When you have an evictable cache/map, you should safely put entries to it without facing with any memory shortages. Forced eviction helps to achieve this. Regular eviction removes one entry at a time while forced eviction can remove multiple entries, which can even be owned by another caches/maps.
Custom Eviction Policy
Apart from the policies such as LRU and LFU, which Hazelcast provides out-of-the-box, you can develop and use your own eviction policy.
To achieve this, you need to provide an implementation of MapEvictionPolicyComparator as in
the following OddEvictor example:
public class MapCustomEvictionPolicyComparator {
public static void main(String[] args) {
Config config = new Config();
config.getMapConfig("test")
.getEvictionConfig()
.setComparator(new OddEvictor())
.setMaxSizePolicy(PER_NODE)
.setSize(10000);
HazelcastInstance instance = Hazelcast.newHazelcastInstance(config);
IMap<Integer, Integer> map = instance.getMap("test");
final Queue<Integer> oddKeys = new ConcurrentLinkedQueue<Integer>();
final Queue<Integer> evenKeys = new ConcurrentLinkedQueue<Integer>();
map.addEntryListener((EntryEvictedListener<Integer, Integer>) event -> {
Integer key = event.getKey();
if (key % 2 == 0) {
evenKeys.add(key);
} else {
oddKeys.add(key);
}
}, false);
// wait some more time to receive evicted-events
parkNanos(SECONDS.toNanos(5));
for (int i = 0; i < 15000; i++) {
map.put(i, i);
}
String msg = "IMap uses sampling based eviction. After eviction"
+ " is completed, we are expecting number of evicted-odd-keys"
+ " should be greater than number of evicted-even-keys. \nNumber"
+ " of evicted-odd-keys = %d, number of evicted-even-keys = %d";
out.println(format(msg, oddKeys.size(), evenKeys.size()));
instance.shutdown();
}
/**
* Odd evictor tries to evict odd keys first.
*/
private static class OddEvictor
implements MapEvictionPolicyComparator<Integer, Integer> {
@Override
public int compare(EntryView<Integer, Integer> e1,
EntryView<Integer, Integer> e2) {
Integer key1 = e1.getKey();
if (key1 % 2 != 0) {
return -1;
}
Integer key2 = e2.getKey();
if (key2 % 2 != 0) {
return 1;
}
return 0;
}
}
}Then you can enable your policy by setting it via the method
MapConfig.getEvictionConfig().setComparatorClassName()
programmatically or via XML declaratively. Following is the example
declarative configuration for the eviction policy OddEvictor implemented above:
<hazelcast>
...
<map name="test">
...
<eviction comparator-class-name="com.mycompany.OddEvictor"/>
...
</map>
</hazelcast>hazelcast:
map:
test:
eviction:
comparator-class-name: com.mycompany.OddEvictorIf you Hazelcast with Spring, you can enable your policy as shown below.
<hz:map name="test">
<hz:map-eviction comparator-class-name="com.package.OddEvictor"/>
</hz:map>Setting In-Memory Format
IMap (and a few other Hazelcast data structures, such as ICache)
has an in-memory-format configuration option. By default, Hazelcast
stores data into memory in binary (serialized) format. Sometimes it can
be efficient to store the entries in their object form, especially in cases
of local processing, such as entry processor and queries.
Specify the in-memory-format element in the configuration to set how the
data will be stored in the memory. You have the following format options:
-
BINARY(default): The data (both the key and value) is stored in serialized binary format. You can use this option if you mostly perform regular map operations, such asputandget. -
OBJECT: The data is stored in deserialized form. This configuration is good for maps where entry processing and queries form the majority of all operations and the objects are complex, making the serialization cost comparatively high. By storing objects, entry processing does not contain the deserialization cost. Note that when you useOBJECTas the in-memory format, the key is still stored in binary format and the value is stored in object format. -
NATIVE: (Hazelcast IMDG Enterprise) This format behaves the same as BINARY, however, instead of on-heap memory, keys and values are stored in the off-heap memory.
Regular operations like get rely on the object instance. When the OBJECT format
is used and a get is performed, the map does not return the stored instance,
but creates a clone. Therefore, this whole get operation first includes a
serialization on the member owning the instance and then a deserialization on
the member calling the instance. When the BINARY format is used, only a
deserialization is required; BINARY is faster.
Similarly, a put operation is faster when the BINARY format is used. If the
format was OBJECT, the map would create a clone of the instance, and there would
first be a serialization and then a deserialization. When BINARY is used, only a
deserialization is needed.
If a value is stored in OBJECT format, a change on a returned value does not
affect the stored instance. In this case, the returned instance is not the actual one
but a clone. Therefore, changes made on an object after it is returned will not reflect
on the actual stored data. Similarly, when a value is written to a map and the value is
stored in OBJECT format, it will be a copy of the put value. Therefore, changes made
on the object after it is stored will not reflect on the stored data.
|
Using High-Density Memory Store with Map
Hazelcast IMDG Enterprise HD
Hazelcast instances are Java programs. In case of BINARY and OBJECT in-memory
formats, Hazelcast stores your distributed data into the heap of its server instances.
Java heap is subject to garbage collection (GC). In case of larger heaps, garbage
collection might cause your application to pause for tens of seconds (even minutes
for really large heaps), badly affecting your application performance and response times.
As the data gets bigger, you either run the application with larger heap, which would result in longer GC pauses or run multiple instances with smaller heap which can turn into an operational nightmare if the number of such instances becomes very high.
To overcome this challenge, Hazelcast offers High-Density Memory Store for your maps.
You can configure your map to use High-Density Memory Store by setting the in-memory
format to NATIVE. The following snippet is the declarative configuration example.
<hazelcast>
...
<map name="nativeMap">
<in-memory-format>NATIVE</in-memory-format>
</map>
...
</hazelcast>hazelcast:
map:
nativeMap:
in-memory-format: NATIVEKeep in mind that you should have already enabled the High-Density Memory Store usage for your cluster. See the Configuring High-Density Memory Store section.
You can also benefit from the persistent memory technologies such as Intel® Optane™ DC to be used by the High-Density Memory Store. See the Using Persistent Memory section.
Required Configuration Changes When Using NATIVE
Note that the eviction mechanism is different for NATIVE in-memory format.
The new eviction algorithm for map with High-Density Memory Store is similar
to that of JCache with High-Density Memory Store and is described here.
<hazelcast>
...
<map name="nativeMap">
<in-memory-format>NATIVE</in-memory-format>
<eviction eviction-policy="LFU" max-size-policy="USED_NATIVE_MEMORY_PERCENTAGE" size="99"/>
</map>
...
</hazelcast>hazelcast:
map:
nativeMap:
in-memory-format: NATIVE
eviction:
eviction-policy: LFU
max-size-policy: USED_NATIVE_MEMORY_PERCENTAGE
size: 99-
These IMap eviction policies for
sizecannot be used:FREE_HEAP_PERCENTAGE,FREE_HEAP_SIZE,USED_HEAP_PERCENTAGE,USED_HEAP_SIZE. -
Near Cache eviction policy
ENTRY_COUNTcannot be used formax-size-policy.
| See the High-Density Memory Store section for more information. |
Metadata Policy
Hazelcast IMap offers automatic preprocessing of various data types on the update time to make queries faster. It is currently supported only by the HazelcastJsonValue type. When metadata creation is on, IMap creates additional metadata about the objects of supported types and uses this metadata during the querying. It does not affect the latency and throughput of the object of any type except the supported types.
This feature is on by default. You can configure it using the metadata-policy
configuration element.
Declarative Configuration:
<hazelcast>
...
<map name="map-a">
<!--
valid values for metadata-policy are:
- OFF
- CREATE_ON_UPDATE (default)
-->
<metadata-policy>OFF</metadata-policy>
</map>
...
</hazelcast>hazelcast:
map:
map-a:
# valid values for metadata-policy are:
# - OFF
# - CREATE_ON_UPDATE (default)
metadata-policy: OFFProgrammatic Configuration:
MapConfig mapConfig = new MapConfig();
mapConfig.setMetadataPolicy(MetadataPolicy.OFF);Loading and Storing Persistent Data
In some cases, you may want to load and store distributed map entries
from/to a persistent data store such as a relational database. For example,
if you want to back up your map entries or if you want to check your database
for updated data entries. To do this,
you can use Hazelcast’s MapStore and
MapLoader interfaces.
| Interface | Description | ||
|---|---|---|---|
|
This method checks the map for a requested value.
If the requested value does not exist in memory, the |
||
|
This method stores the contents of a map in the data store.
|
The following example shows you how to implement the MapStore interface.
The MapStore interface extends the MapLoader interface.
Therefore, all methods and configuration parameters of the MapLoader
interface are also available on the MapStore interface.
|
public class PersonMapStore implements MapStore<Long, Person> {
private final Connection con;
private final PreparedStatement allKeysStatement;
public PersonMapStore() {
try {
con = DriverManager.getConnection("jdbc:hsqldb:mydatabase", "SA", "");
con.createStatement().executeUpdate(
"create table if not exists person (id bigint not null, name varchar(45), primary key (id))");
allKeysStatement = con.prepareStatement("select id from person");
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
public synchronized void delete(Long key) {
System.out.println("Delete:" + key);
try {
con.createStatement().executeUpdate(
format("delete from person where id = %s", key));
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
public synchronized void store(Long key, Person value) {
try {
con.createStatement().executeUpdate(
format("insert into person values(%s,'%s')", key, value.getName()));
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
public synchronized void storeAll(Map<Long, Person> map) {
for (Map.Entry<Long, Person> entry : map.entrySet()) {
store(entry.getKey(), entry.getValue());
}
}
public synchronized void deleteAll(Collection<Long> keys) {
for (Long key : keys) {
delete(key);
}
}
public synchronized Person load(Long key) {
try {
ResultSet resultSet = con.createStatement().executeQuery(
format("select name from person where id =%s", key));
try {
if (!resultSet.next()) {
return null;
}
String name = resultSet.getString(1);
return new Person(key, name);
} finally {
resultSet.close();
}
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
public synchronized Map<Long, Person> loadAll(Collection<Long> keys) {
Map<Long, Person> result = new HashMap<Long, Person>();
for (Long key : keys) {
result.put(key, load(key));
}
return result;
}
public Iterable<Long> loadAllKeys() {
return new StatementIterable<Long>(allKeysStatement);
}
}During the initial loading process, the MapStore interface uses an ExecutorService thread, not a partition thread, in order to avoid affecting ongoing partition operations. After the initial loading process, the IMap.get() and IMap.put() methods use a partition thread.
Each member receives an instance of the MapStore implementation, which means that multiple threads can access it at the same time. If you use multiple threads to access shared state in a MapStore implementation, you need to make sure that the implementation is thread safe.
|
MapStore or MapLoader implementations should not use Hazelcast Map/Queue/MultiMap/List/Set operations. Your implementation should
only work with your data store. Otherwise, you may get into deadlock situations.
|
To monitor the MapLoader instance for each loaded entry,
use the EntryLoadedListener interface. See the
Listening for Map Events section
to learn how you can catch entry-based events.
|
Setting Expiration Times on Loaded and Stored Data Entries
Entries loaded by MapLoader implementations do not have a set time-to-live property.
Therefore, they live until evicted or explicitly removed. To enforce expiration
times on the entries, you can use the EntryLoader and EntryStore interfaces.
These interfaces extend the MapLoader and MapStore interfaces.
Therefore, all methods and configuration parameters of the MapLoader and
MapStore implementations are also available on the EntryLoader and EntryStore implementations.
|
EntryLoader allows you to set time-to-live values per key before
handing the values to Hazelcast. Therefore, you can store and load
key-specific time-to-live values in the external storage.
Similar to EntryLoader, in order to store custom expiration times associated
with the entries, you may use EntryStore. EntryStore allows you to retrieve
associated expiration date for each entry. The expiration date is an offset
from an epoch in milliseconds. Epoch is January 1, 1970 UTC which is used
by System.currentTimeMillis().
Although the expiration date is expressed in milliseconds, expiration
dates are rounded to the nearest lower whole second because the IMap interface
uses second granularity when it comes to expiration.
|
The following example shows you how to implement the EntryStore interface.
public class PersonEntryStore implements EntryStore<Long, Person> {
private final Connection con;
private final PreparedStatement allKeysStatement;
public PersonEntryStore() {
try {
con = DriverManager.getConnection("jdbc:hsqldb:mydatabase", "SA", "");
con.createStatement().executeUpdate(
"create table if not exists person (id bigint not null, name varchar(45), expiration-date bigint, primary key (id))");
allKeysStatement = con.prepareStatement("select id from person");
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
@Override
public synchronized void delete(Long key) {
System.out.println("Delete:" + key);
try {
con.createStatement().executeUpdate(
format("delete from person where id = %s", key));
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
@Override
public synchronized void store(Long key, MetadataAwareValue<Person> value) {
try {
con.createStatement().executeUpdate(
format("insert into person values(%s,'%s', %d)", key, value.getValue().getName(), value.getExpirationTime()));
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
@Override
public void storeAll(Map<Long, MetadataAwareValue<Person>> map) {
for (Map.Entry<Long, MetadataAwareValue<Person>> entry : map.entrySet()) {
store(entry.getKey(), entry.getValue());
}
}
@Override
public synchronized void deleteAll(Collection<Long> keys) {
for (Long key : keys) {
delete(key);
}
}
@Override
public synchronized MetadataAwareValue<Person> load(Long key) {
try {
ResultSet resultSet = con.createStatement().executeQuery(
format("select name,expiration-date from person where id =%s", key));
try {
if (!resultSet.next()) {
return null;
}
String name = resultSet.getString(1);
Long expirationDate = resultSet.getLong(2);
return new MetadataAwareValue<>(new Person(key, name), expirationDate);
} finally {
resultSet.close();
}
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
@Override
public synchronized Map<Long, MetadataAwareValue<Person>> loadAll(Collection<Long> keys) {
Map<Long, MetadataAwareValue<Person>> result = new HashMap<>();
for (Long key : keys) {
result.put(key, load(key));
}
return result;
}
public Iterable<Long> loadAllKeys() {
return new StatementIterable<Long>(allKeysStatement);
}
}Using Read-Through Persistence
If an entry does not exist in memory when an application asks for it, Hazelcast asks the loader implementation to load that entry from the data store. If the entry exists there, the loader implementation gets it, hands it to Hazelcast, and Hazelcast puts it into memory. This is read-through persistence mode.
As you can remember from the introduction of this section, the IMap.get() method
triggers the load() method in your MapLoader implementation if an entry does not
exist in the memory. In this case, note that the IMap.get() method does not create
backup copies for such entries, when the mode is read-through persistence: there is no
need for backups for these entries since if the primary entry is lost, then a read for
the key triggers the load() method and loads the entry from the persistence layer.
Setting Write-Through Persistence
The MapStore interface can be configured to be write-through by setting the write-delay-seconds
property to 0. This means the entries are sent to the data store synchronously.
In this mode, when the map.put(key,value) call returns:
-
The
MapStore.store(key,value)method is successfully called so the entry is persisted. -
The in-memory entry is updated.
-
Any in-memory backup copies are successfully created on other cluster members (if the
backup-countproperty is greater than 0).
If the MapStore.store(key,value) method throws an exception, it is propagated to
the original IMap.put() or IMap.remove() call in the form of RuntimeException.
Setting Write-Behind Persistence
You can configure MapStore as write-behind by setting the write-delay-seconds
property to a value bigger than 0. This means the modified entries will be
put to the data store asynchronously after a configured delay.
In write-behind mode, Hazelcast coalesces updates on a specific key by
default, which means it applies only the last update on that key. However,
you can set MapStoreConfig.setWriteCoalescing() to FALSE and you can store
all updates performed on a key to the data store.
|
When you set MapStoreConfig.setWriteCoalescing() to FALSE, after you
reached per-node maximum write-behind-queue capacity, subsequent put operations
will fail with ReachedMaxSizeException. This exception is thrown to prevent
uncontrolled grow of write-behind queues. You can set per-node maximum capacity
using the system property hazelcast.map.write.behind.queue.capacity. See the
System Properties appendix for information on this property
and how to set the system properties.
|
In write-behind mode, when the map.put(key,value) call returns:
-
in-memory entry is updated
-
in-memory backup copies are successfully created on the other cluster members (if
backup-countis greater than 0) -
the entry is marked as dirty so that after
write-delay-seconds, it can be persisted withMapStore.store(key,value)call -
and for fault tolerance, dirty entries are stored in a queue on the primary member and also on a back-up member.
The same behavior goes for the map.remove(key), the only difference is that
MapStore.delete(key) is called when the entry will be deleted.
If MapStore throws an exception, then Hazelcast tries to store the entry again.
If the entry still cannot be stored, a log message is printed and the entry is re-queued.
For batch write operations, which are only allowed in write-behind mode,
Hazelcast calls the MapStore.storeAll(map) and MapStore.deleteAll(collection)
methods to do all writes in a single call.
If a map entry is marked as dirty, meaning that it is waiting to be
persisted to the MapStore in a write-behind scenario, the eviction process
forces the entry to be stored. This way you have control over the number of
entries waiting to be stored, and thus you can prevent a possible OutOfMemory
exception.
|
MapStore or MapLoader implementations should not use
Hazelcast Map/Queue/MultiMap/List/Set operations. Your implementation should
only work with your data store. Otherwise, you may get into deadlock situations.
|
Here is an example configuration:
<hazelcast>
...
<map name="default">
<map-store enabled="true" initial-mode="LAZY">
<class-name>com.hazelcast.examples.DummyStore</class-name>
<write-delay-seconds>60</write-delay-seconds>
<write-batch-size>1000</write-batch-size>
<write-coalescing>true</write-coalescing>
</map-store>
</map>
...
</hazelcast>hazelcast:
map:
default:
map-store:
enabled: true
initial-mode: LAZY
class-name: com.hazelcast.examples.DummyStore
write-delay-seconds: 60
write-batch-size: 1000
write-coalescing: trueThe following are the descriptions of MapStore configuration elements and attributes:
-
class-name: Name of the class implementing MapLoader and/or MapStore. -
write-delay-seconds: Number of seconds to delay to call the MapStore.store(key, value). If the value is zero then it is write-through, so theMapStore.store(key,value)method is called as soon as the entry is updated. Otherwise, it is write-behind; so the updates will be stored after thewrite-delay-secondsvalue by calling theHazelcast.storeAll(map)method. Its default value is 0. -
write-batch-size: Used to create batch chunks when writing map store. In default mode, all map entries are tried to be written in one go. To create batch chunks, the minimum meaningful value for write-batch-size is 2. For values smaller than 2, it works as in default mode. -
write-coalescing: In write-behind mode, Hazelcast coalesces updates on a specific key by default; it applies only the last update on it. You can set this element tofalseto store all updates performed on a key to the data store. -
enabled: True to enable this map-store, false to disable. Its default value is true. -
initial-mode: Sets the initial load mode. LAZY is the default load mode, where load is asynchronous. EAGER means load is blocked till all partitions are loaded. See the Initializing Map on Startup section for more details.
Managing the Lifecycle of a MapLoader
With MapLoader (and MapStore which extends it), you can do the regular store and load operations.
If you need to perform other operations on create or on destroy of a MapLoader,
such as establishing a connection to a database or accessing to other Hazelcast maps,
you need to implement the MapLoaderLifeCycleSupport interface. By implementing
it, you will have the init() and destroy() methods.
The init() method initializes the MapLoader implementation. Hazelcast calls
this method when the map is first created on a Hazelcast instance. The MapLoader
implementation can initialize the required resources
such as reading a configuration file or creating a database connection
or accessing a Hazelcast instance.
The destroy() method is called during the graceful shutdown of a Hazelcast instance.
You can override this method to cleanup the resources held by the MapLoader implementation, such as
closing the database connections.
In summary, you need MapLoaderLifecycleSupport to perform actions
on create and on destroy of a MapLoader.
See here to see this interface in action.
Storing Entries to Multiple Maps
A configuration can be applied to more than one map using wildcards
(see Using Wildcards), meaning that the configuration is
shared among the maps. But MapStore does not know which entries to store
when there is one configuration applied to multiple maps.
To store entries when there is one configuration applied to multiple maps,
use Hazelcast’s MapStoreFactory interface. Using the MapStoreFactory interface,
MapStores for each map can be created when a wildcard configuration is used.
Example code is shown below.
Config config = new Config();
MapConfig mapConfig = config.getMapConfig( "*" );
MapStoreConfig mapStoreConfig = mapConfig.getMapStoreConfig();
mapStoreConfig.setFactoryImplementation( new MapStoreFactory<Object, Object>() {
@Override
public MapLoader<Object, Object> newMapStore( String mapName, Properties properties ) {
return null;
}
});To initialize the MapLoader implementation with the given map name, configuration
properties and the Hazelcast instance, implement the
MapLoaderLifecycleSupport interface
which is described in the previous section.
Initializing Map on Startup
To pre-populate the in-memory map when it is first used, you can
implement the MapLoader.loadAllKeys() method. This method is the fastest
way of pre-populating maps because Hazelcast optimizes the loading process
by having each cluster member load its owned portion of the entries.
The MapLoader.loadAllKeys() method loads all data from the data store, depending
on whether your MapStore or MapLoader implementations have their
initial-mode property set to LAZY (default) or EAGER.
If you add indices to your map with the
IndexConfig
class or the addIndex method,
then the initial-mode property is overridden by EAGER.
|
| Initial Mode | Behavior | ||
|---|---|---|---|
|
The |
||
|
After getting or creating the map, the
|
If your implementation of the MapLoader.loadAllKeys() method returns a null value, nothing will be loaded.
Your MapLoader.loadAllKeys() method can also return all or some of the
keys. For example, you may select and return only the keys that are most
important to you.
Here is the MapLoader initialization flow:
-
When
getMap()is first called from any member, initialization starts depending on the value of theinitial-modeproperty. If it is set toEAGER, initialization starts on all partitions as soon as the map is created, i.e., all partitions are loaded whengetMapis called. A map is loaded when theIMap#getMapmethod is called in theEAGERmode; otherwise, it is loaded after the first operation, e.g.,IMap#size,IMap#get, etc. of the map in theLAZYmode. -
Hazelcast calls the
MapLoader.loadAllKeys()to get all your keys on one of the members. -
That member distributes keys to all other members in batches.
-
Each member loads values of all its owned keys by calling
MapLoader.loadAll(keys). -
Each member puts its owned entries into the map by calling
IMap.putTransient(key,value).
If the load mode is LAZY and the clear() method is called
(which triggers MapStore.deleteAll()), Hazelcast removes ONLY the
loaded entries from your map and datastore. Since all the data is not loaded
in this case (LAZY mode), please note that there may still be entries in your datastore.
|
If you do not want the MapStore start to load as soon as the
first cluster member starts, you can use the system property hazelcast.initial.min.cluster.size.
For example, if you set its value as 3, loading process will be
blocked until all three members are completely up.
|
Loading Keys Incrementally
If the number of keys to load is large, it is more efficient to
load them incrementally rather than loading them all at once. To support
incremental loading, the MapLoader.loadAllKeys() method returns an Iterable
which can be lazily populated with the results of a database query.
In Hazelcast IMDG version 3.5, the return type of loadAllKeys()
was changed from a Set type to an Iterable type. MapLoader implementations from previous
releases are also supported and do not need to be adapted.
|
Hazelcast iterates over the returned data and, while doing so, sends the keys
to their respective owner members. The iterator that was returned from the MapLoader.loadAllKeys()
may also implement the Closeable interface, in which case the iterator is closed when
the iteration is over. This is intended for releasing resources such as closing a JDBC result set.
Forcing All Keys To Be Loaded
The MapLoader.loadAll() method loads some or all keys into a
data store in order to optimize multiple load operations. This method has
two signatures (the same method can take two different parameter lists):
One signature loads the given keys and the other loads all keys. See the example code below.
final int numberOfEntriesToAdd = 1000;
final String mapName = LoadAll.class.getCanonicalName();
final Config config = createNewConfig(mapName);
final HazelcastInstance node = Hazelcast.newHazelcastInstance(config);
final IMap<Integer, Integer> map = node.getMap(mapName);
populateMap(map, numberOfEntriesToAdd);
System.out.printf("# Map store has %d elements\n", numberOfEntriesToAdd);
map.evictAll();
System.out.printf("# After evictAll map size\t: %d\n", map.size());
map.loadAll(true);
System.out.printf("# After loadAll map size\t: %d\n", map.size());Post-Processing Objects in Map Store
In some scenarios, you may need to modify the object after storing it into the map store. For example, you can get an ID or version auto-generated by your database and then need to modify your object stored in the distributed map, but not to break the synchronization between the database and the data grid.
To post-process an object in the map store, implement the PostProcessingMapStore
interface to put the modified object into the distributed map. This triggers an
extra step of Serialization, so use it only when needed. (This is only valid
when using the write-through map store configuration.)
Here is an example of post processing map store:
class ProcessingStore implements MapStore<Integer, Employee>, PostProcessingMapStore {
@Override
public void store( Integer key, Employee employee ) {
EmployeeId id = saveEmployee();
employee.setId( id.getId() );
}
}| Please note that if you are using a post-processing map store in combination with the entry processors, post-processed values will not be carried to backups. |
Accessing a Database Using Properties
You can prepare your own MapLoader to access a database such as Cassandra
and MongoDB. For this, you can first declaratively specify the database properties
in your hazelcast.xml configuration file and then implement the
MapLoaderLifecycleSupport interface to pass those properties.
You can define the database properties, such as its URL and name, using the
properties configuration element. The following is a configuration example
for MongoDB:
<hazelcast>
...
<map name="supplements">
<map-store enabled="true" initial-mode="LAZY">
<class-name>com.hazelcast.loader.YourMapStoreImplementation</class-name>
<properties>
<property name="mongo.url">mongodb://localhost:27017</property>
<property name="mongo.db">mydb</property>
<property name="mongo.collection">supplements</property>
</properties>
</map-store>
</map>
...
</hazelcast>hazelcast:
map:
supplements:
map-store:
enabled: true
initial-mode: LAZY
class-name: com.hazelcast.loader.YourMapStoreImplementation
properties:
mongo_url: mongodb://localhost:27017
mongo.db: mydb
mango.collection: supplementsAfter specifying the database properties in your configuration,
you need to implement the MapLoaderLifecycleSupport interface and
give those properties in the init() method, as shown below:
public class YourMapStoreImplementation implements MapStore<String, Supplement>, MapLoaderLifecycleSupport {
private MongoClient mongoClient;
private MongoCollection collection;
public YourMapStoreImplementation() {
}
@Override
public void init(HazelcastInstance hazelcastInstance, Properties properties, String mapName) {
String mongoUrl = (String) properties.get("mongo.url");
String dbName = (String) properties.get("mongo.db");
String collectionName = (String) properties.get("mongo.collection");
this.mongoClient = new MongoClient(new MongoClientURI(mongoUrl));
this.collection = mongoClient.getDatabase(dbName).getCollection(collectionName);
}See the full example here.
MapStore and MapLoader Methods Triggered by IMap Operations
As explained in the above sections, you can configure
Hazelcast maps to be backed by a map store to persist the entries.
In this case many of the IMap methods call MapLoader or MapStore
methods to load, store, or remove data. This section summarizes the IMap
operations that may trigger the MapStore or MapLoader methods.
If the initial-mode property of the MapLoader
implementation is set to LAZY, the first time any IMap method
is called, it triggers the MapLoader.loadAllKeys() method.
|
IMap Method |
Impact on the MapStore/MapLoader implementations |
|---|---|
|
This method flushes all the local dirty
entries by calling the |
|
These methods are used to put entries to the map. They call the
|
|
These methods put an entry into the map without returning the old value.
They call the |
|
Removes the mapping for a key from the map if it is present. It calls the
|
|
These methods are used to remove entries from the map for various conditions.
They call the |
|
This method updates time-to-live of an existing entry. It calls the |
|
It clears the map and deletes the items from the backing map store. It calls
the |
|
It replaces the entry for a key only if currently mapped to a given value.
It calls the |
|
These methods apply the user defined entry processors to the entry or entries.
They call the |
Creating Near Cache for Map
The Hazelcast distributed map supports a local Near Cache for remotely stored entries to increase the performance of local read operations. See the Near Cache section for a detailed explanation of the Near Cache feature and its configuration.
Locking Maps
Hazelcast Distributed Map (IMap) is thread-safe to meet your thread safety requirements. When these requirements increase or you want to have more control on the concurrency, consider the Hazelcast solutions described here.
Consider the following example:
public class RacyUpdateMember {
public static void main( String[] args ) throws Exception {
HazelcastInstance hz = Hazelcast.newHazelcastInstance();
IMap<String, Value> map = hz.getMap( "map" );
String key = "1";
map.put( key, new Value() );
System.out.println( "Starting" );
for ( int k = 0; k < 1000; k++ ) {
if ( k % 100 == 0 ) System.out.println( "At: " + k );
Value value = map.get( key );
Thread.sleep( 10 );
value.amount++;
map.put( key, value );
}
System.out.println( "Finished! Result = " + map.get(key).amount );
}
static class Value implements Serializable {
public int amount;
}
}If the above code is run by more than one cluster member simultaneously, a race condition is likely. You can solve this condition with Hazelcast using either pessimistic or optimistic locking.
Pessimistic Locking
One way to solve the race issue is by using pessimistic locking - lock the map entry until you are finished with it.
To perform pessimistic locking, use the lock mechanism provided by the
Hazelcast distributed map, i.e., the map.lock and map.unlock methods.
See the below example code.
public class PessimisticUpdateMember {
public static void main( String[] args ) throws Exception {
HazelcastInstance hz = Hazelcast.newHazelcastInstance();
IMap<String, Value> map = hz.getMap( "map" );
String key = "1";
map.put( key, new Value() );
System.out.println( "Starting" );
for ( int k = 0; k < 1000; k++ ) {
map.lock( key );
try {
Value value = map.get( key );
Thread.sleep( 10 );
value.amount++;
map.put( key, value );
} finally {
map.unlock( key );
}
}
System.out.println( "Finished! Result = " + map.get( key ).amount );
}
static class Value implements Serializable {
public int amount;
}
}The IMap lock will automatically be collected by the garbage collector when the lock is released and no other waiting conditions exist on the lock.
The IMap lock is reentrant, but it does not support fairness.
In some cases, a client application connected to your
cluster may cause the entries in a map to remain locked
after the application has been restarted (which were already locked
before such a restart). This can be due to the
reasons such as incomplete/incorrect client implementations. In these cases,
you can unlock the entries, either from the thread which locked them
using the IMap.unlock() method, or check if the entry is locked
using the IMap.isLock() method and then call IMap.forceUnlock().
|
For the above case, as a workaround, you can also kill all the applications connected
to the cluster and use the Management Center’s scripting functionality to clear the map and
release the locks (instead of using IMap.forceUnlock()). Keep in mind that the scripting
functionality is limited to working with maps that have primitive key types, e.g., string keys
and limited to relaying only a single string of output per member to the result panel in the Management Center.
|
Another way to solve the race issue is by acquiring a predictable Lock
object from Hazelcast. This way, every value in the map can be given a lock,
or you can create a stripe of locks.
Optimistic Locking
In Hazelcast, you can apply the optimistic locking strategy with the
map’s replace method. This method compares values in object or data forms
depending on the in-memory format configuration. If the values are equal,
it replaces the old value with the new one. If you want to use your defined
equals method, in-memory-format should be OBJECT. Otherwise, Hazelcast
serializes objects to BINARY forms and compares them.
See the below example code.
| The below example code is intentionally broken. |
public class OptimisticMember {
public static void main( String[] args ) throws Exception {
HazelcastInstance hz = Hazelcast.newHazelcastInstance();
IMap<String, Value> map = hz.getMap( "map" );
String key = "1";
map.put( key, new Value() );
System.out.println( "Starting" );
for ( int k = 0; k < 1000; k++ ) {
if ( k % 10 == 0 ) System.out.println( "At: " + k );
for (; ; ) {
Value oldValue = map.get( key );
Value newValue = new Value( oldValue );
Thread.sleep( 10 );
newValue.amount++;
if ( map.replace( key, oldValue, newValue ) )
break;
}
}
System.out.println( "Finished! Result = " + map.get( key ).amount );
}
static class Value implements Serializable {
public int amount;
public Value() {
}
public Value( Value that ) {
this.amount = that.amount;
}
public boolean equals( Object o ) {
if ( o == this ) return true;
if ( !( o instanceof Value ) ) return false;
Value that = ( Value ) o;
return that.amount == this.amount;
}
}
}Pessimistic vs. Optimistic Locking
The locking strategy you choose depends on your locking requirements.
Optimistic locking is better for mostly read-only systems. It has a performance boost over pessimistic locking.
Pessimistic locking is good if there are lots of updates on the same key. It is more robust than optimistic locking from the perspective of data consistency.
In Hazelcast, use IExecutorService to submit a task to a key owner,
or to a member or members. This is the recommended way to perform task executions,
rather than using pessimistic or optimistic locking techniques. IExecutorService
has fewer network hops and less data over wire, and tasks are executed very near to the data.
See the Data Affinity section.
Solving the ABA Problem
The ABA problem occurs in environments when a shared resource is open to change by multiple threads. Even if one thread sees the same value for a particular key in consecutive reads, it does not mean that nothing has changed between the reads. Another thread may change the value, do work and change the value back, while the first thread thinks that nothing has changed.
To prevent these kind of problems, you can assign a version number and check it before any write to be sure that nothing has changed between consecutive reads. Although all the other fields are equal, the version field will prevent objects from being seen as equal. This is the optimistic locking strategy; it is used in environments that do not expect intensive concurrent changes on a specific key.
In Hazelcast, you can apply the optimistic locking
strategy with the map replace method.
Lock Split-Brain Protection with Pessimistic Locking
Locks can be configured to check the number of currently present members
before applying a locking operation. If the check fails, the lock operation
fails with a SplitBrainProtectionException (see the Split-Brain Protection section).
As pessimistic locking uses lock operations internally, it also uses the configured
lock split-brain protection. This means that you can configure a lock split-brain protection with the same name or a
pattern that matches the map name. Note that the split-brain protection for IMap locking actions can be
different from the split-brain protection for other IMap actions.
The following actions check for lock split-brain protection before being applied:
-
IMap.lock(K)andIMap.lock(K, long, java.util.concurrent.TimeUnit) -
IMap.isLocked() -
IMap.tryLock(K),IMap.tryLock(K, long, java.util.concurrent.TimeUnit)andIMap.tryLock(K, long, java.util.concurrent.TimeUnit, long, java.util.concurrent.TimeUnit) -
IMap.unlock() -
IMap.forceUnlock() -
MultiMap.lock(K)andMultiMap.lock(K, long, java.util.concurrent.TimeUnit) -
MultiMap.isLocked() -
MultiMap.tryLock(K),MultiMap.tryLock(K, long, java.util.concurrent.TimeUnit)andMultiMap.tryLock(K, long, java.util.concurrent.TimeUnit, long, java.util.concurrent.TimeUnit) -
MultiMap.unlock() -
MultiMap.forceUnlock()
An example of declarative configuration:
<hazelcast>
...
<map name="myMap">
<split-brain-protection-ref>map-actions-split-brain-protection</split-brain-protection-ref>
</map>
<lock name="myMap">
<split-brain-protection-ref>map-lock-actions-split-brain-protection</split-brain-protection-ref>
</lock>
...
</hazelcast>hazelcast:
map:
myMap:
split-brain-protection-ref: map-actions-split-brain-protection
lock:
myMap:
split-brain-protection-ref: map-lock-actions-split-brain-protectionHere the configured map uses the map-lock-actions-split-brain-protection for
map lock actions and the map-actions-split-brain-protection for other map actions.
Accessing Map and Entry Statistics
You can retrieve the statistics of maps in your Hazelcast IMDG members using the
getLocalMapStats() method.
It returns information such as primary and backup entry count, last update
time and locked entry count. If you need the cluster-wide map statistics, you can
get the local map statistics from all members of the cluster and combine them.
Alternatively, you can see the map statistics on
Hazelcast Management Center.
To be able to retrieve the statistics on map level, you should set statistics-enabled
under the map configuration as true, which is also the default value:
<hazelcast>
...
<map name="myMap">
<statistics-enabled>true</statistics-enabled>
</map>
...
</hazelcast>hazelcast:
map:
myMap:
statistics-enabled: trueIf it is false, the statistics are not gathered
for the map: you cannot see them on the Hazelcast Management Center, nor retrieve
using getLocalMapStats().
When enabled, you can simply use getLocalMapStats(), an example of which is shown below:
HazelcastInstance hc = Hazelcast.newHazelcastInstance();
IMap<String, String> myMap = hc.getMap( "myMap" );
LocalMapStats mapStatistics = myMap.getLocalMapStats();
System.out.println( "Number of entries owned on this member = "
+ mapStatistics.getOwnedEntryCount() );Using the same method, you can also retrieve the statistics on entry level.
For this, you should set per-entry-stats-enabled under the map configuration as
true (its default value is false):
<hazelcast>
...
<map name="myMap">
<per-entry-stats-enabled>true</per-entry-stats-enabled>
</map>
...
</hazelcast>hazelcast:
map:
myMap:
per-entry-stats-enabled: trueWhen enabled, you can retrieve map entry statistics such as last accessed/updated time, creation
time and last stored time, again using the getLocalMapStats() method.
Also, when enabled, the fields in the getEntryView(key) operation becomes
visible. This method returns an overview of a map entry specified by its key.
Here is an example.
HazelcastInstance hz = Hazelcast.newHazelcastInstance();
EntryView entry = hz.getMap( "quotes" ).getEntryView( "1" );
System.out.println ( "size in memory : " + entry.getCost() );
System.out.println ( "creationTime : " + entry.getCreationTime() );
System.out.println ( "expirationTime : " + entry.getExpirationTime() );
System.out.println ( "number of hits : " + entry.getHits() );
System.out.println ( "lastAccessedTime: " + entry.getLastAccessTime() );
System.out.println ( "lastUpdateTime : " + entry.getLastUpdateTime() );
System.out.println ( "version : " + entry.getVersion() );
System.out.println ( "key : " + entry.getKey() );
System.out.println ( "value : " + entry.getValue() );Listening to Map Entries with Predicates
You can think of it as an entry listener with predicates.
| See the Listening for Map Events section for information on the listeners for Hazelcast maps and how to use them. |
The default backwards-compatible event publishing strategy only publishes
UPDATED events when map entries are updated to a value that
matches the predicate with which the listener was registered.
This implies that when using the default event publishing strategy,
your listener is not notified about an entry whose
value is updated from one that matches the predicate to a new value
that does not match the predicate.
|
Since version 3.7, when you configure Hazelcast members with property
hazelcast.map.entry.filtering.natural.event.types set to true,
handling of entry updates conceptually treats value transition as entry,
update or exit with regards to the predicate value space.
The following table compares how a listener is notified about an update
to a map entry value under the default
backwards-compatible Hazelcast behavior (when property
hazelcast.map.entry.filtering.natural.event.types is not set or is set
to false) versus when set to true:
Default |
|
|
When old value matches predicate, new value does not match predicate |
No event is delivered to entry listener |
|
When old value matches predicate, new value matches predicate |
|
|
When old value does not match predicate, new value does not match predicate |
No event is delivered to entry listener |
No event is delivered to entry listener |
When old value does not match predicate, new value matches predicate |
|
|
As an example, let’s listen to the changes made on an employee
with the surname "Smith". First, let’s create the Employee class.
public class Employee implements Serializable {
private final String surname;
public Employee(String surname) {
this.surname = surname;
}
@Override
public String toString() {
return "Employee{" +
"surname='" + surname + '\'' +
'}';
}
}Then, let’s create a listener with predicate by adding a listener
that tracks ADDED, UPDATED and REMOVED entry events with the surname predicate.
public class ListenerWithPredicate {
public static void main(String[] args) {
Config config = new Config();
config.setProperty("hazelcast.map.entry.filtering.natural.event.types", "true");
HazelcastInstance hz = Hazelcast.newHazelcastInstance(config);
IMap<String, String> map = hz.getMap("map");
map.addEntryListener(new MyEntryListener(),
Predicates.sql("surname=smith"), true);
System.out.println("Entry Listener registered");
}
static class MyEntryListener
implements EntryAddedListener<String, String>,
EntryUpdatedListener<String, String>,
EntryRemovedListener<String, String> {
@Override
public void entryAdded(EntryEvent<String, String> event) {
System.out.println("Entry Added:" + event);
}
@Override
public void entryRemoved(EntryEvent<String, String> event) {
System.out.println("Entry Removed:" + event);
}
@Override
public void entryUpdated(EntryEvent<String, String> event) {
System.out.println("Entry Updated:" + event);
}
}
}And now, let’s play with the employee "smith" and see how that employee is listened to.
public class Modify {
public static void main(String[] args) {
Config config = new Config();
config.setProperty("hazelcast.map.entry.filtering.natural.event.types", "true");
HazelcastInstance hz = Hazelcast.newHazelcastInstance(config);
IMap<String, Employee> map = hz.getMap("map");
map.put("1", new Employee("smith"));
map.put("2", new Employee("jordan"));
System.out.println("done");
System.exit(0);
}
}When you first run the class ListenerWithPredicate and then run Modify,
an output similar to the one below appears.
entryAdded:EntryEvent {Address[192.168.178.10]:5702} key=1,oldValue=null,
value=Person{name= smith }, event=ADDED, by Member [192.168.178.10]:5702| See the Continuous Query Cache section for more information. |
Removing Map Entries in Bulk with Predicates
You can remove all map entries that match your predicate. For this,
Hazelcast offers the method removeAll(). Its syntax is as follows:
void removeAll(Predicate<K, V> predicate);Normally the map entries matching the predicate are found with a full scan of the map. If the entries are indexed, Hazelcast uses the index search to find them. With index, you can expect that finding the entries is faster.
When removeAll() is called, ALL entries in the caller member’s
Near Cache are also removed.
|
Adding Interceptors
You can add intercept operations and execute your own business logic
synchronously blocking the operations. You can change the returned value
from a get operation, change the value in put, or cancel operations
by throwing an exception.
Interceptors are different from listeners. With listeners, you take an action after the operation has been completed. Interceptor actions are synchronous and you can alter the behavior of operation, change its values, or totally cancel it.
Map interceptors are chained, so adding the same interceptor multiple times to the
same map can result in duplicate effects. This can easily happen when the interceptor
is added to the map at member initialization, so that each member adds the same interceptor.
When you add the interceptor in this way, be sure to implement the hashCode()
method to return the same value for every instance of the interceptor.
It is not strictly necessary, but it is a good idea to also implement equals()
as this ensures that the map interceptor can be removed reliably.
The IMap API has two methods for adding and removing an interceptor to the map:
addInterceptor and removeInterceptor. See also the
MapInterceptor interface
to learn about the methods used to intercept the changes in a map.
The following is an example usage.
public class MapInterceptorMember {
public static void main(String[] args) {
HazelcastInstance hz = Hazelcast.newHazelcastInstance();
IMap<String, String> map = hz.getMap("themap");
map.addInterceptor(new MyMapInterceptor());
map.put("1", "1");
System.out.println(map.get("1"));
}
private static class MyMapInterceptor implements MapInterceptor {
@Override
public Object interceptGet(Object value) {
return value + "-foo";
}
@Override
public void afterGet(Object value) {
}
@Override
public Object interceptPut(Object oldValue, Object newValue) {
return null;
}
@Override
public void afterPut(Object value) {
}
@Override
public Object interceptRemove(Object removedValue) {
return null;
}
@Override
public void afterRemove(Object value) {
}
}
}Preventing Out of Memory Exceptions
It is very easy to trigger an out of memory exception (OOME) with query-based map methods,
especially with large clusters or heap sizes. For example, on a cluster with five members
having 10 GB of data and 25 GB heap size per member, a single call of IMap.entrySet()
fetches 50 GB of data and crashes the calling instance.
A call of IMap.values() may return too much data for a single member.
This can also happen with a real query and an unlucky choice of predicates,
especially when the parameters are chosen by a user of your application.
To prevent this, you can configure a maximum result size limit for query based operations.
This is not a limit like SELECT * FROM map LIMIT 100, which you can achieve by a
Paging Predicate. A maximum result size limit
for query based operations is meant to be a last line of defense to prevent your members
from retrieving more data than they can handle.
The Hazelcast component which calculates this limit is the QueryResultSizeLimiter.
Setting Query Result Size Limit
If the QueryResultSizeLimiter is activated, it calculates a result size limit per partition.
Each QueryOperation runs on all partitions of a member, so it collects result entries
as long as the member limit is not exceeded. If that happens, a
QueryResultSizeExceededException is thrown and propagated to the calling instance.
This feature depends on an equal distribution of the data on the cluster members to
calculate the result size limit per member. Therefore, there is a minimum value defined
in QueryResultSizeLimiter.MINIMUM_MAX_RESULT_LIMIT. Configured values below the minimum
will be increased to the minimum.
Local Pre-check
In addition to the distributed result size check in the QueryOperations,
there is a local pre-check on the calling instance. If you call the method from a client,
the pre-check is executed on the member that invokes the QueryOperations.
Since the local pre-check can increase the latency of a QueryOperation,
you can configure how many local partitions should be considered for the pre-check,
or you can deactivate the feature completely.
Scope of Result Size Limit
Besides the designated query operations, there are other operations that use predicates internally.
Those method calls throw the QueryResultSizeExceededException as well.
See the following matrix for the methods that are covered by the query result size limit.
Configuring Query Result Size
The query result size limit is configured via the following system properties.
-
hazelcast.query.result.size.limit: Result size limit for query operations on maps. This value defines the maximum number of returned elements for a single query result. If a query exceeds this number of elements, a QueryResultSizeExceededException is thrown. -
hazelcast.query.max.local.partition.limit.for.precheck: Maximum value of local partitions to trigger local pre-check forPredicates#alwaysTrue()query operations on maps.
See the System Properties appendix to see the full descriptions of these properties and how to set them.